DAWN: Dependency-Aware Fast Inference for Diffusion LLMs
作者: Lizhuo Luo, Zhuoran Shi, Jiajun Luo, Zhi Wang, Shen Ren, Wenya Wang, Tianwei Zhang
分类: cs.CL
发布日期: 2026-02-06
🔗 代码/项目: GITHUB
💡 一句话要点
DAWN:面向Diffusion LLM的依赖感知快速推理方法,提升解码效率。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: Diffusion LLM 并行解码 依赖感知 快速推理 文本生成
📋 核心要点
- 现有dLLM推理受限于质量-速度权衡,并行解码策略保守,未充分挖掘效率潜力,忽略了token间的语义依赖关系。
- DAWN通过提取token依赖关系,构建依赖图,选择更可靠的未掩码位置进行并行解码,从而提升推理速度。
- 实验表明,DAWN在多个模型和数据集上,推理速度比基线提高了1.80-8.06倍,同时保持了生成质量。
📝 摘要(中文)
Diffusion大型语言模型(dLLM)在文本生成方面展现出优势,特别是其固有的并行解码能力。然而,受限于质量与速度的权衡,现有的推理方案采用保守的并行策略,导致效率潜力未被充分挖掘。核心挑战在于并行解码假设每个位置可以独立填充,但token之间通常存在语义耦合。因此,一个位置的正确选择会约束其他位置的有效选择。在没有对这些token间依赖关系进行建模的情况下,并行策略会产生质量下降的输出。基于此,我们提出DAWN,一种无需训练的依赖感知解码方法,用于快速dLLM推理。DAWN提取token依赖关系,并利用两个关键动机:(1)依赖于未掩码确定位置的位置变得更可靠,(2)同时未掩码强耦合的不确定位置会导致错误。基于这些发现,DAWN利用依赖图来选择每个迭代中更可靠的未掩码位置,从而在生成质量损失可忽略不计的情况下实现高并行性。在多个模型和数据集上的大量实验表明,DAWN在保持生成质量的同时,推理速度比基线提高了1.80-8.06倍。代码已发布在https://github.com/lizhuo-luo/DAWN。
🔬 方法详解
问题定义:论文旨在解决Diffusion LLM推理过程中,由于token间语义依赖关系未被充分考虑,导致并行解码效率受限的问题。现有方法为了保证生成质量,通常采用保守的并行策略,牺牲了推理速度。
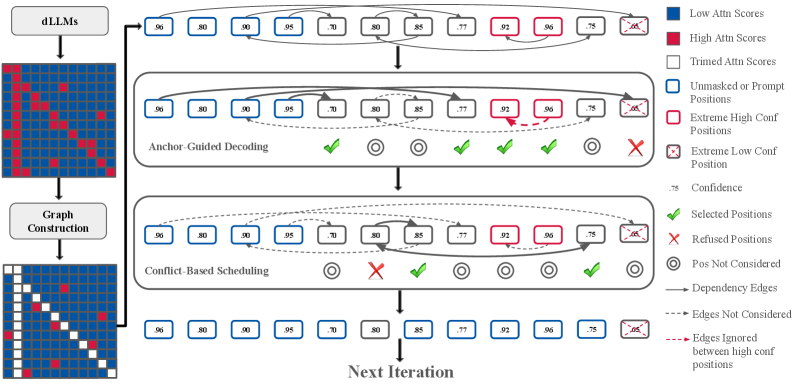
核心思路:DAWN的核心思路是利用token间的依赖关系,在并行解码过程中优先选择更可靠的位置进行未掩码操作。通过构建依赖图,DAWN能够识别哪些位置的token选择依赖于其他已确定的token,从而避免同时未掩码强耦合的不确定位置,减少错误的发生。
技术框架:DAWN的技术框架主要包括以下几个阶段:1) 依赖关系提取:从训练数据或预训练模型中提取token之间的依赖关系,构建依赖图。2) 位置选择:在每个解码迭代中,利用依赖图选择更可靠的未掩码位置。3) 并行解码:对选定的位置进行并行解码,生成token。4) 迭代更新:根据已生成的token,更新依赖图,并重复位置选择和并行解码过程,直到生成完整的文本序列。
关键创新:DAWN最重要的技术创新点在于其依赖感知的解码策略。与现有方法不同,DAWN并非盲目地进行并行解码,而是根据token间的依赖关系,动态地调整未掩码位置的选择,从而在保证生成质量的同时,最大化并行度。这种依赖感知的策略能够更有效地利用dLLM的并行解码能力。
关键设计:DAWN的关键设计包括:1) 依赖图的构建方法:如何有效地从数据中提取token间的依赖关系,例如使用注意力机制或共现统计等方法。2) 位置选择策略:如何根据依赖图选择更可靠的未掩码位置,例如可以考虑依赖于已确定token的数量、依赖关系的强度等因素。3) 并行解码的粒度:如何确定每次迭代中未掩码位置的数量,需要在并行度和生成质量之间进行权衡。论文中可能还涉及一些超参数的设置,例如依赖关系的阈值、位置选择的权重等。
🖼️ 关键图片


📊 实验亮点
DAWN在多个模型和数据集上进行了广泛的实验,结果表明其能够显著提高dLLM的推理速度,同时保持生成质量。具体而言,DAWN在推理速度上比基线方法提高了1.80-8.06倍,并且在BLEU、ROUGE等指标上与基线方法相当甚至略有提升。这些实验结果充分证明了DAWN的有效性和优越性。
🎯 应用场景
DAWN具有广泛的应用前景,可用于各种需要快速文本生成的场景,例如机器翻译、文本摘要、对话生成等。通过提高dLLM的推理速度,DAWN可以降低计算成本,并使其能够应用于对延迟敏感的实时应用中。此外,DAWN的依赖感知解码策略也可以用于改进其他类型的生成模型,例如GAN和VAE。
📄 摘要(原文)
Diffusion large language models (dLLMs) have shown advantages in text generation, particularly due to their inherent ability for parallel decoding. However, constrained by the quality--speed trade-off, existing inference solutions adopt conservative parallel strategies, leaving substantial efficiency potential underexplored. A core challenge is that parallel decoding assumes each position can be filled independently, but tokens are often semantically coupled. Thus, the correct choice at one position constrains valid choices at others. Without modeling these inter-token dependencies, parallel strategies produce deteriorated outputs. Motivated by this insight, we propose DAWN, a training-free, dependency-aware decoding method for fast dLLM inference. DAWN extracts token dependencies and leverages two key motivations: (1) positions dependent on unmasked certain positions become more reliable, (2) simultaneously unmasking strongly coupled uncertain positions induces errors. Given those findings, DAWN leverages a dependency graph to select more reliable unmasking positions at each iteration, achieving high parallelism with negligible loss in generation quality. Extensive experiments across multiple models and datasets demonstrate that DAWN speedups the inference by 1.80-8.06x over baselines while preserving the generation quality. Code is released at https://github.com/lizhuo-luo/DAWN.