Uncovering Cross-Objective Interference in Multi-Objective Alignment
作者: Yining Lu, Meng Jiang
分类: cs.CL, cs.LG
发布日期: 2026-02-06
💡 一句话要点
揭示多目标对齐中跨目标干扰现象,提出CTWA方法缓解性能退化。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多目标优化 大型语言模型 对齐 跨目标干扰 协方差 奖励模型 CTWA
📋 核心要点
- 大型语言模型多目标对齐中,部分目标性能提升的同时,其他目标性能反而下降,存在跨目标干扰。
- 论文提出协方差目标权重自适应(CTWA)方法,通过维持目标奖励与训练信号间的正协方差来缓解跨目标干扰。
- 实验验证了CTWA的有效性,并通过理论分析,从局部改进和全局收敛两个角度解释了跨目标干扰的成因。
📝 摘要(中文)
本文研究了大型语言模型(LLM)多目标对齐中一种持续存在的失效模式:训练仅提高了部分目标的性能,而导致其他目标性能下降。我们将这种现象形式化为跨目标干扰,并对经典标量化算法进行了首次系统研究,表明干扰普遍存在且具有很强的模型依赖性。为了解释这种现象,我们推导出一个局部协方差定律,表明当目标的奖励与标量化得分表现出正协方差时,该目标在一阶上得到改善。我们将此分析扩展到现代对齐中使用的裁剪替代目标,证明了在温和条件下,协方差定律在裁剪下仍然有效。在此分析的基础上,我们提出了一种即插即用方法——协方差目标权重自适应(CTWA),该方法保持目标奖励与训练信号之间的正协方差,以有效缓解跨目标干扰。最后,我们用Polyak-Łojasiewicz条件下的全局收敛分析来补充这些局部改进条件,从而确定非凸标量化优化何时实现全局收敛,以及跨目标干扰如何依赖于特定的模型几何属性。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)在多目标对齐过程中出现的跨目标干扰问题。现有方法在优化多个目标时,往往只能提升部分目标的性能,而牺牲其他目标的性能,导致整体效果不佳。这种现象表明,不同目标之间存在相互干扰,使得模型难以同时优化所有目标。
核心思路:论文的核心思路是基于协方差定律,即目标的改进与该目标的奖励和标量化得分之间的协方差有关。如果奖励与得分之间存在正协方差,则目标会得到改进;反之,则会退化。因此,论文提出通过维持目标奖励与训练信号之间的正协方差来缓解跨目标干扰。
技术框架:论文的技术框架主要包括以下几个部分:首先,形式化定义了跨目标干扰现象;其次,推导了局部协方差定律,解释了目标改进与协方差之间的关系;然后,将协方差定律扩展到裁剪替代目标;接着,提出了CTWA方法,用于维持正协方差;最后,进行了全局收敛分析,研究了非凸标量化优化的收敛性。
关键创新:论文的关键创新在于提出了CTWA方法,这是一种即插即用的方法,可以动态调整不同目标的权重,以维持目标奖励与训练信号之间的正协方差。与传统的标量化方法相比,CTWA能够更好地平衡不同目标之间的优化,从而缓解跨目标干扰。
关键设计:CTWA的关键设计在于如何估计目标奖励与训练信号之间的协方差,并根据协方差调整目标的权重。具体来说,CTWA使用滑动平均来估计协方差,并根据协方差的大小来调整目标的权重。此外,论文还对CTWA的参数进行了详细的分析和实验,以确保其有效性和稳定性。
🖼️ 关键图片
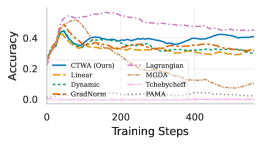

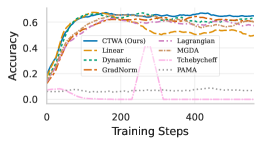
📊 实验亮点
论文通过实验验证了CTWA方法的有效性。实验结果表明,CTWA能够显著缓解跨目标干扰,提高多目标对齐的整体性能。例如,在某个实验中,CTWA使得所有目标的性能都得到了提升,而传统的标量化方法只能提升部分目标的性能,甚至导致其他目标性能下降。
🎯 应用场景
该研究成果可应用于各种需要多目标优化的LLM对齐场景,例如,在奖励模型训练中,可以同时优化模型的准确性和安全性,避免模型在追求准确性的同时产生有害内容。此外,该方法还可以推广到其他多目标优化问题,例如机器人控制、推荐系统等。
📄 摘要(原文)
We study a persistent failure mode in multi-objective alignment for large language models (LLMs): training improves performance on only a subset of objectives while causing others to degrade. We formalize this phenomenon as cross-objective interference and conduct the first systematic study across classic scalarization algorithms, showing that interference is pervasive and exhibits strong model dependence. To explain this phenomenon, we derive a local covariance law showing that an objective improves at first order when its reward exhibits positive covariance with the scalarized score. We extend this analysis to clipped surrogate objectives used in modern alignment, demonstrating that the covariance law remains valid under mild conditions despite clipping. Building on this analysis, we propose Covariance Targeted Weight Adaptation (CTWA), a plug-and-play method that maintains positive covariance between objective rewards and the training signal to effectively mitigate cross-objective interference. Finally, we complement these local improvement conditions with a global convergence analysis under the Polyak--Łojasiewicz condition, establishing when non-convex scalarized optimization achieves global convergence and how cross-objective interference depends on specific model geometric properties.