Visual Word Sense Disambiguation with CLIP through Dual-Channel Text Prompting and Image Augmentations
作者: Shamik Bhattacharya, Daniel Perkins, Yaren Dogan, Vineeth Konjeti, Sudarshan Srinivasan, Edmon Begoli
分类: cs.CL
发布日期: 2026-02-06
备注: 9 pages, 6 figures, pending journal/workshop submission
💡 一句话要点
提出基于CLIP和双通道文本提示的视觉词义消歧框架,提升词义理解能力。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉词义消歧 CLIP 双通道提示 文本提示 图像增强
📋 核心要点
- 大型语言模型在处理自然语言时,词汇歧义是一个持续存在的挑战,需要有效的消歧方法。
- 论文提出一种基于CLIP的视觉词义消歧框架,通过双通道文本提示和图像增强来提升模型性能。
- 实验表明,双通道提示能有效提升模型在SemEval-2023 VWSD数据集上的MRR和命中率。
📝 摘要(中文)
本文提出了一种可解释的视觉词义消歧(VWSD)框架,旨在解决大型语言模型(LLM)在自然语言理解中面临的词汇歧义问题。该模型利用CLIP将歧义语言和候选图像投影到共享的多模态空间中。通过结合WordNet同义词的语义和照片提示的双通道集成来丰富文本嵌入,并通过鲁棒的测试时增强来优化图像嵌入。然后,使用余弦相似度来确定与歧义文本最匹配的图像。在SemEval-2023 VWSD数据集上的评估表明,嵌入的丰富将MRR从0.7227提高到0.7590,命中率从0.5810提高到0.6220。消融研究表明,双通道提示提供了强大的低延迟性能,而激进的图像增强仅产生边际收益。使用WordNet定义和多语言提示集成的额外实验进一步表明,嘈杂的外部信号往往会稀释语义特异性,从而加强了精确的、与CLIP对齐的提示对于视觉词义消歧的有效性。
🔬 方法详解
问题定义:论文旨在解决自然语言理解中词汇歧义的问题,特别是如何利用视觉信息来辅助消除歧义。现有方法可能无法充分利用视觉信息,或者在文本提示方面不够精细,导致消歧效果不佳。
核心思路:论文的核心思路是将歧义文本和候选图像投影到CLIP的共享多模态空间中,然后通过比较文本和图像嵌入的相似度来确定最佳匹配。通过精心设计的双通道文本提示和图像增强技术来提升嵌入的质量,从而提高消歧的准确性。
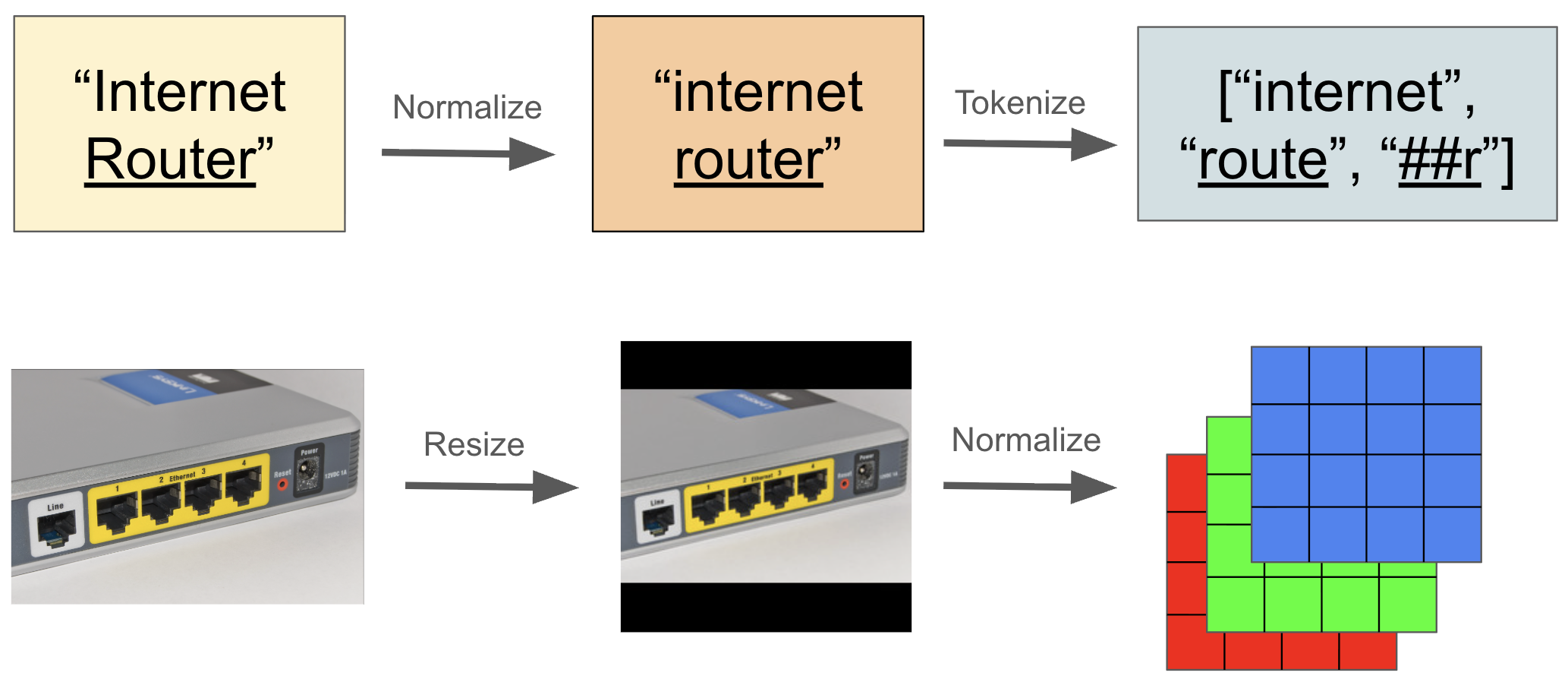
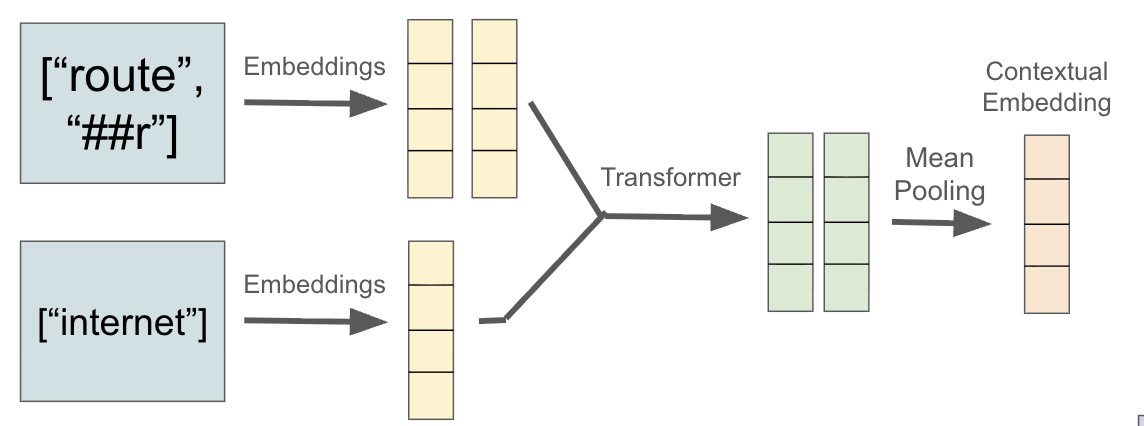
技术框架:该框架主要包含以下几个模块:1) 文本编码模块:使用CLIP的文本编码器对歧义文本进行编码,并利用双通道提示(语义提示和照片提示)来丰富文本嵌入。2) 图像编码模块:使用CLIP的图像编码器对候选图像进行编码,并应用测试时增强来提高图像嵌入的鲁棒性。3) 相似度计算模块:计算文本嵌入和图像嵌入之间的余弦相似度。4) 决策模块:选择与歧义文本相似度最高的图像作为正确答案。
关键创新:论文的关键创新在于双通道文本提示策略,它结合了基于WordNet同义词的语义提示和基于照片的提示,能够更全面地捕捉歧义词的语义信息。此外,论文还探索了图像增强技术在视觉词义消歧中的应用。
关键设计:双通道提示的具体实现方式是:语义通道使用WordNet同义词作为提示,照片通道使用与图像相关的描述性词语作为提示。这两个通道的提示信息被集成到CLIP的文本编码器中,以生成更丰富的文本嵌入。图像增强采用了一系列常见的图像变换操作,如旋转、缩放、裁剪等,以提高图像嵌入的鲁棒性。
🖼️ 关键图片

📊 实验亮点
实验结果表明,通过双通道文本提示,模型在SemEval-2023 VWSD数据集上的MRR从0.7227提升到0.7590,命中率从0.5810提升到0.6220。消融实验验证了双通道提示的有效性,并表明精确的CLIP对齐提示对于视觉词义消歧至关重要。图像增强带来的收益相对较小。
🎯 应用场景
该研究成果可应用于智能问答系统、搜索引擎、机器翻译等领域,提升这些系统在处理歧义语言时的准确性和可靠性。通过结合视觉信息,可以更有效地理解用户的意图,从而提供更精准的服务。未来,该方法可以扩展到其他自然语言处理任务中,例如文本摘要、情感分析等。
📄 摘要(原文)
Ambiguity poses persistent challenges in natural language understanding for large language models (LLMs). To better understand how lexical ambiguity can be resolved through the visual domain, we develop an interpretable Visual Word Sense Disambiguation (VWSD) framework. The model leverages CLIP to project ambiguous language and candidate images into a shared multimodal space. We enrich textual embeddings using a dual-channel ensemble of semantic and photo-based prompts with WordNet synonyms, while image embeddings are refined through robust test-time augmentations. We then use cosine similarity to determine the image that best aligns with the ambiguous text. When evaluated on the SemEval-2023 VWSD dataset, enriching the embeddings raises the MRR from 0.7227 to 0.7590 and the Hit Rate from 0.5810 to 0.6220. Ablation studies reveal that dual-channel prompting provides strong, low-latency performance, whereas aggressive image augmentation yields only marginal gains. Additional experiments with WordNet definitions and multilingual prompt ensembles further suggest that noisy external signals tend to dilute semantic specificity, reinforcing the effectiveness of precise, CLIP-aligned prompts for visual word sense disambiguation.