Generating Data-Driven Reasoning Rubrics for Domain-Adaptive Reward Modeling
作者: Kate Sanders, Nathaniel Weir, Sapana Chaudhary, Kaj Bostrom, Huzefa Rangwala
分类: cs.CL, cs.AI
发布日期: 2026-02-06
💡 一句话要点
提出数据驱动的推理评估准则,提升领域自适应奖励建模效果
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 推理验证 奖励建模 数据驱动 错误分类 领域自适应
📋 核心要点
- 现有大型语言模型在推理验证中,尤其是在长文本和专业领域,难以准确识别错误。
- 论文提出一种数据驱动方法,自动构建细粒度的推理错误分类体系,提升LLM的错误检测能力。
- 实验表明,该方法在技术领域错误识别方面优于基线,并能提升强化学习训练模型的任务准确率。
📝 摘要(中文)
大型语言模型(LLM)在推理输出验证方面面临挑战,尤其是在长输出、需要专业知识的领域以及缺乏可验证奖励的问题中,难以可靠地识别思维过程中的错误。本文提出了一种数据驱动的方法,自动构建高度细粒度的推理错误分类体系,以增强LLM在未见推理轨迹上的错误检测能力。研究结果表明,利用这些错误分类体系(即“评估准则”)的分类方法,在编码、数学和化学工程等技术领域,相比基线方法表现出更强的错误识别能力。这些评估准则可用于构建更强大的LLM-as-judge奖励函数,通过强化学习训练推理模型。实验结果表明,与通过通用LLM-as-judge训练的模型相比,这些奖励函数有潜力将模型在困难领域上的任务准确率提高+45%,并接近通过可验证奖励训练的模型的性能,同时仅使用20%的黄金标签。通过本文的方法,我们将奖励评估准则的使用从评估定性模型行为扩展到评估定量模型正确性,从而使模型能够在没有完整黄金标签数据集的情况下解决复杂的技术问题,而黄金标签的获取通常成本高昂。
🔬 方法详解
问题定义:现有方法,特别是依赖大型语言模型直接进行推理验证的方法,在处理需要专业知识的领域和长推理链时,难以准确识别错误。此外,对于缺乏可验证奖励的问题,奖励函数的构建也面临挑战,导致模型训练效果不佳。获取高质量的标注数据成本高昂,限制了模型在复杂技术问题上的应用。
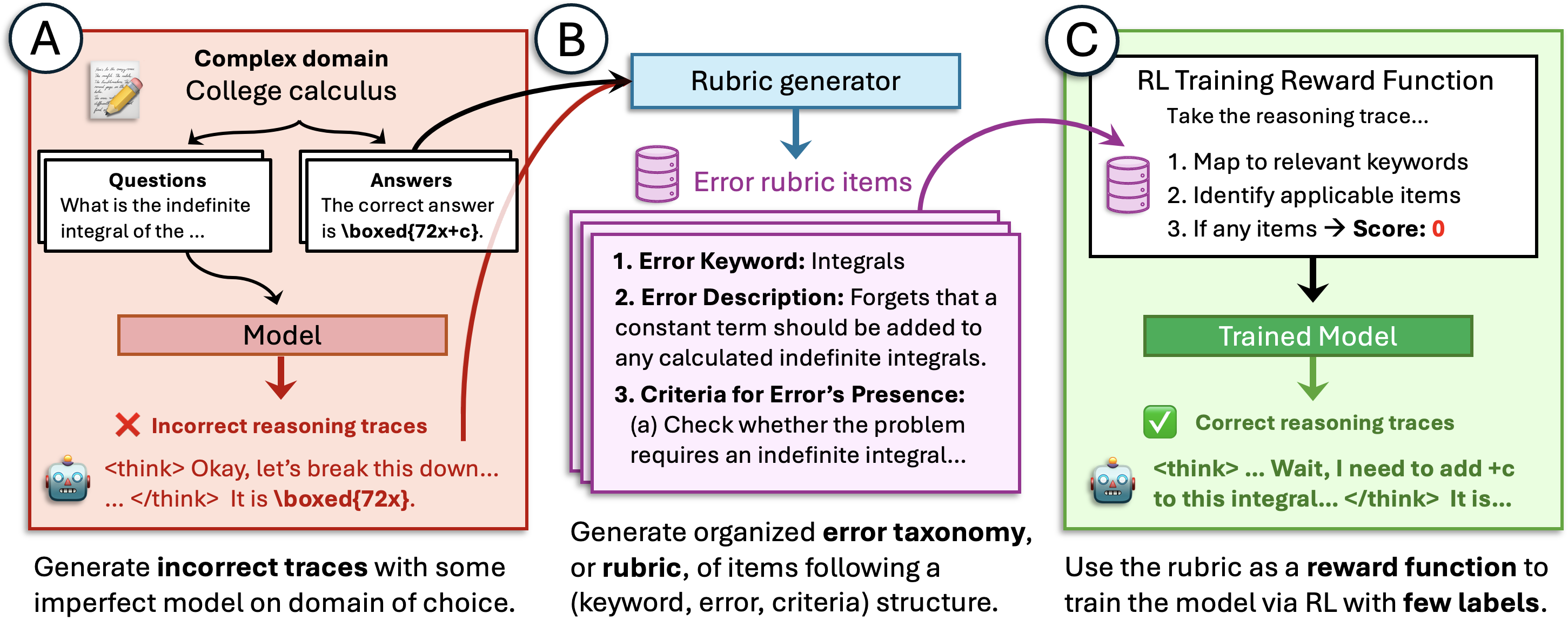
核心思路:本文的核心思路是利用数据驱动的方法,自动构建细粒度的推理错误分类体系(即“评估准则”)。通过对错误类型进行明确的定义和分类,可以帮助LLM更准确地识别推理过程中的错误,从而提升奖励函数的质量,并最终提高模型的推理能力。这种方法避免了对大量人工标注数据的依赖,降低了训练成本。
技术框架:该方法主要包含以下几个阶段:1) 数据收集与预处理:收集推理轨迹数据,并进行清洗和格式化。2) 错误类型定义:基于数据分析,定义一系列细粒度的推理错误类型,构建错误分类体系。3) 模型训练:利用标注数据(可以是少量黄金标签和大量弱标签),训练一个错误分类模型,用于自动识别推理轨迹中的错误。4) 奖励函数构建:基于错误分类模型的输出,构建奖励函数,用于强化学习训练推理模型。5) 模型评估:在测试集上评估模型的推理能力和错误识别能力。
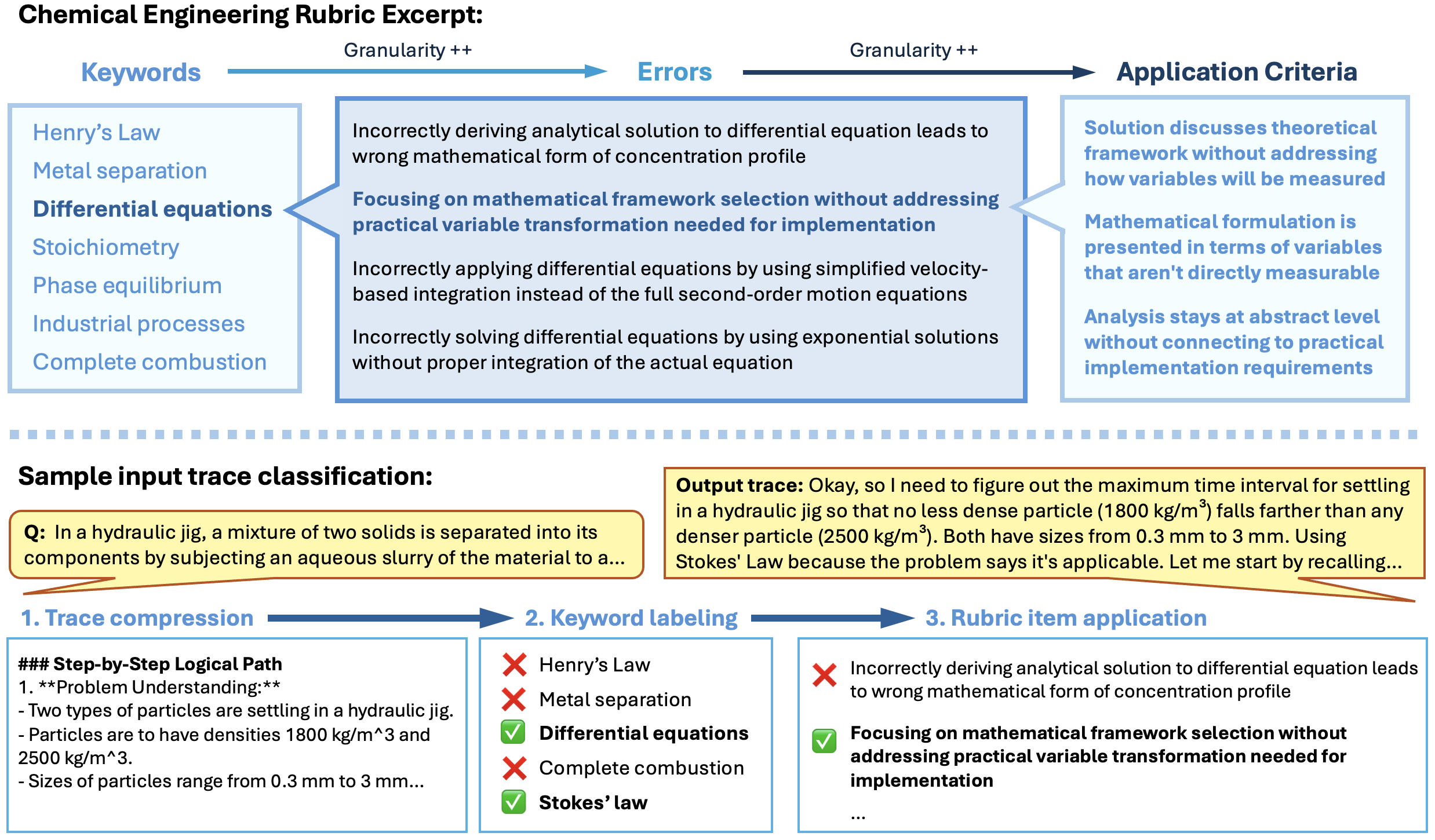
关键创新:该方法最重要的技术创新点在于数据驱动的错误分类体系构建。与传统的基于人工定义的错误分类体系相比,该方法能够更准确地捕捉特定领域的错误模式,并能够随着数据的变化进行自适应调整。此外,该方法将错误分类体系应用于奖励函数构建,实现了从评估定性模型行为到评估定量模型正确性的扩展。
关键设计:错误分类体系的设计是关键。论文可能采用了层次化的错误分类结构,并针对不同领域的特点,设计了不同的错误类型。奖励函数的设计也至关重要,需要平衡奖励的稀疏性和准确性。具体的参数设置、损失函数和网络结构等技术细节在论文中应该有详细描述,但此处未知。
🖼️ 关键图片
📊 实验亮点
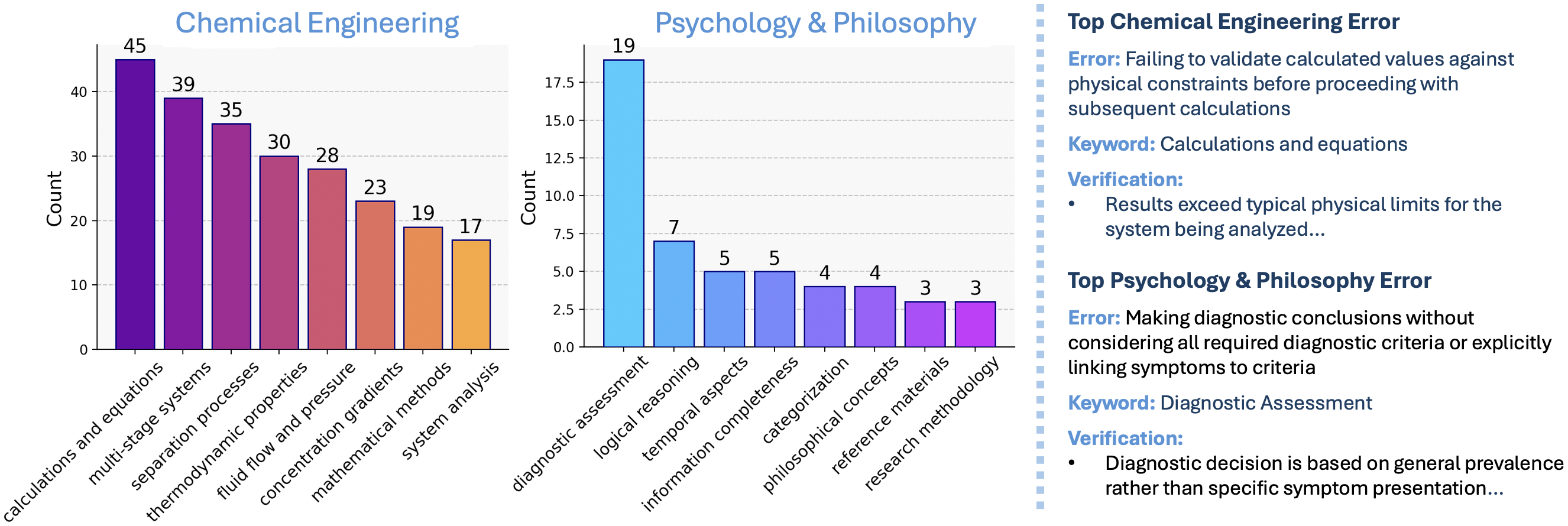
实验结果表明,使用数据驱动的推理评估准则训练的模型,在困难领域上的任务准确率比通过通用LLM-as-judge训练的模型提高了+45%。更重要的是,该方法在仅使用20%的黄金标签的情况下,就能够达到接近通过可验证奖励训练的模型的性能,显著降低了训练成本,验证了该方法的有效性。
🎯 应用场景
该研究成果可应用于教育领域,自动评估学生的作业和考试答案,提供个性化的反馈和指导。在科研领域,可以用于验证研究结果的正确性,提高研究效率。在工业界,可以用于自动化代码审查、数学问题求解和化学工程设计等任务,降低成本,提高效率。未来,该方法有望扩展到更多需要专业知识的领域,例如医疗诊断和金融分析。
📄 摘要(原文)
An impediment to using Large Language Models (LLMs) for reasoning output verification is that LLMs struggle to reliably identify errors in thinking traces, particularly in long outputs, domains requiring expert knowledge, and problems without verifiable rewards. We propose a data-driven approach to automatically construct highly granular reasoning error taxonomies to enhance LLM-driven error detection on unseen reasoning traces. Our findings indicate that classification approaches that leverage these error taxonomies, or "rubrics", demonstrate strong error identification compared to baseline methods in technical domains like coding, math, and chemical engineering. These rubrics can be used to build stronger LLM-as-judge reward functions for reasoning model training via reinforcement learning. Experimental results show that these rewards have the potential to improve models' task accuracy on difficult domains over models trained by general LLMs-as-judges by +45%, and approach performance of models trained by verifiable rewards while using as little as 20% as many gold labels. Through our approach, we extend the usage of reward rubrics from assessing qualitative model behavior to assessing quantitative model correctness on tasks typically learned via RLVR rewards. This extension opens the door for teaching models to solve complex technical problems without a full dataset of gold labels, which are often highly costly to procure.