Quantum Attention by Overlap Interference: Predicting Sequences from Classical and Many-Body Quantum Data
作者: Alessio Pecilli, Matteo Rosati
分类: quant-ph, cs.CL, cs.LG
发布日期: 2026-02-06
备注: 4 + 1 pages, 2 figures
💡 一句话要点
提出基于重叠干涉的量子注意力机制,用于预测经典和量子多体数据序列。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 量子自注意力 量子Transformer 序列预测 量子机器学习 量子动力学建模
📋 核心要点
- 传统Transformer在处理长序列时计算复杂度高,尤其是在嵌入维度较低的情况下。
- 论文提出一种基于量子重叠干涉的自注意力机制(QSA),直接计算Renyi-1/2交叉熵损失。
- 实验表明,QSA能够学习经典数据和量子多体数据的序列预测,为量子动力学建模提供新方法。
📝 摘要(中文)
本文提出了一种自注意力机制的变分量子实现(QSA),它是Transformer和大型语言模型的核心操作。QSA通过形成过去数据的重叠加权组合来预测序列的未来元素。与以往方法不同,QSA通过状态重叠的干涉来实现所需的非线性,并直接返回Renyi-1/2交叉熵损失,作为可观测量的期望值,避免了将幅度编码的预测解码为经典logits的需求。此外,QSA自然地适应了一种受约束的可训练数据嵌入,该嵌入将量子态重叠与数据级相似性联系起来。QSA的门复杂度主要缩放为O(T d^2),而经典方法为O(T^2 d),这表明在序列长度T超过嵌入大小d的实际情况下具有优势。在模拟中,我们展示了基于QSA的量子Transformer学习了经典数据和多体横向场Ising量子轨迹上的序列预测,从而将可训练的注意力机制确立为量子动力学建模的实用原语。
🔬 方法详解
问题定义:现有Transformer模型中的自注意力机制在处理长序列时,计算复杂度较高,尤其是当序列长度远大于嵌入维度时。传统的自注意力机制需要计算所有序列元素之间的相似度,导致复杂度为O(T^2 d),其中T是序列长度,d是嵌入维度。这限制了其在资源受限环境中的应用,例如量子计算平台。
核心思路:本文的核心思路是利用量子态的重叠干涉来实现自注意力机制中的非线性操作,从而降低计算复杂度。通过将数据嵌入到量子态中,并利用量子态的重叠来表示数据之间的相似性,可以避免显式地计算所有元素之间的相似度。此外,论文还利用Renyi-1/2交叉熵损失作为可观测量,直接从量子态中提取损失值,避免了将量子态解码为经典logits的步骤。
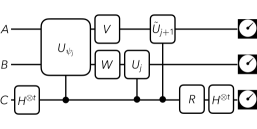
技术框架:QSA(Quantum Self-Attention)的整体框架包括以下几个主要步骤:1) 数据嵌入:将经典或量子数据嵌入到量子态中,并使用可训练的参数来优化嵌入方式。2) 量子自注意力:利用量子态的重叠干涉来计算注意力权重,并对输入序列进行加权求和。3) 损失计算:直接从量子态中提取Renyi-1/2交叉熵损失,作为训练的优化目标。整个框架可以嵌入到量子Transformer中,用于序列预测任务。
关键创新:本文最重要的技术创新点在于利用量子态的重叠干涉来实现自注意力机制中的非线性操作。与传统的自注意力机制相比,QSA避免了显式地计算所有元素之间的相似度,从而降低了计算复杂度。此外,QSA还直接从量子态中提取损失值,避免了将量子态解码为经典logits的步骤,进一步提高了效率。
关键设计:QSA的关键设计包括:1) 数据嵌入方式:论文采用了一种受约束的可训练数据嵌入,将量子态重叠与数据级相似性联系起来。2) 量子态的表示:论文使用量子比特来表示数据,并利用量子门来操作量子态。3) 损失函数:论文使用Renyi-1/2交叉熵损失作为训练的优化目标,该损失可以直接从量子态中提取。
🖼️ 关键图片

📊 实验亮点
实验结果表明,基于QSA的量子Transformer能够学习经典数据和多体横向场Ising量子轨迹上的序列预测。QSA的门复杂度主要缩放为O(T d^2),而经典方法为O(T^2 d),这表明在序列长度T超过嵌入大小d的实际情况下具有优势。这些结果验证了QSA作为量子动力学建模实用原语的有效性。
🎯 应用场景
该研究成果可应用于量子机器学习、量子自然语言处理等领域。例如,可以利用QSA来构建更高效的量子Transformer模型,用于处理长序列数据,如基因序列、蛋白质序列等。此外,该方法还可以应用于量子动力学建模,例如预测量子多体系统的演化轨迹,为量子材料设计和量子器件优化提供新的工具。
📄 摘要(原文)
We propose a variational quantum implementation of self-attention (QSA), the core operation in transformers and large language models, which predicts future elements of a sequence by forming overlap-weighted combinations of past data. At variance with previous approaches, our QSA realizes the required nonlinearity through interference of state overlaps and returns a Renyi-1/2 cross-entropy loss directly as the expectation value of an observable, avoiding the need to decode amplitude-encoded predictions into classical logits. Furthermore, QSA naturally accommodates a constrained, trainable data-embedding that ties quantum state overlaps to data-level similarities. We find a gate complexity dominant scaling O(T d^2) for QSA, versus O(T^2 d) classically, suggesting an advantage in the practical regime where the sequence length T dominates the embedding size d. In simulations, we show that our QSA-based quantum transformer learns sequence prediction on classical data and on many-body transverse-field Ising quantum trajectories, establishing trainable attention as a practical primitive for quantum dynamical modeling.