compar:IA: The French Government's LLM arena to collect French-language human prompts and preference data
作者: Lucie Termignon, Simonas Zilinskas, Hadrien Pélissier, Aurélien Barrot, Nicolas Chesnais, Elie Gavoty
分类: cs.CL, cs.AI
发布日期: 2026-02-06
备注: 18 pages, 7 figures, preprint
💡 一句话要点
compar:IA:法国政府构建法语LLM评测平台,收集人类prompt和偏好数据
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 人机交互 法语 偏好学习 数据收集 开源平台 数字公共服务
📋 核心要点
- 现有大型语言模型在非英语语境下表现欠佳,缺乏针对性训练数据和人类偏好对齐数据。
- compar:IA平台旨在收集大规模法语prompt和偏好数据,通过盲配对比较实现用户无约束的评价。
- 已收集超过60万prompt和25万投票,89%为法语数据,并开放数据集及法语模型排行榜。
📝 摘要(中文)
大型语言模型(LLMs)在非英语语言中的性能、文化契合度和安全鲁棒性通常有所降低,部分原因是英语在预训练数据和人类偏好对齐数据中占据主导地位。诸如基于人类反馈的强化学习(RLHF)和直接偏好优化(DPO)等训练方法需要人类偏好数据,但对于英语以外的许多语言来说,这些数据仍然稀缺且大多为非公开数据。为了解决这一差距,我们推出了compar:IA,这是一个在法国政府内部开发的开源数字公共服务,旨在从主要讲法语的普通大众中收集大规模的人类偏好数据。该平台使用盲配对比较界面来捕获不受约束的真实prompt和用户判断,涵盖各种语言模型,同时保持较低的参与摩擦和保护隐私的自动过滤。截至2026年2月7日,compar:IA已收集超过60万个自由格式prompt和25万个偏好投票,其中约89%的数据为法语。我们以开放许可发布三个互补数据集——对话、投票和反应——并提供初步分析,包括法语语言模型排行榜和用户互动模式。除了法语环境之外,compar:IA正在发展成为一项国际数字公共产品,为多语言模型训练、评估和人机交互研究提供可重用的基础设施。
🔬 方法详解
问题定义:现有大型语言模型在非英语语言,特别是法语上的表现不佳,主要原因是缺乏高质量的法语预训练数据和人类偏好数据。现有的RLHF和DPO等方法依赖于大量的人类偏好数据,而这些数据在法语等语言中非常稀缺,且通常不对外公开。这导致模型在法语环境下的文化适应性和安全性存在问题。
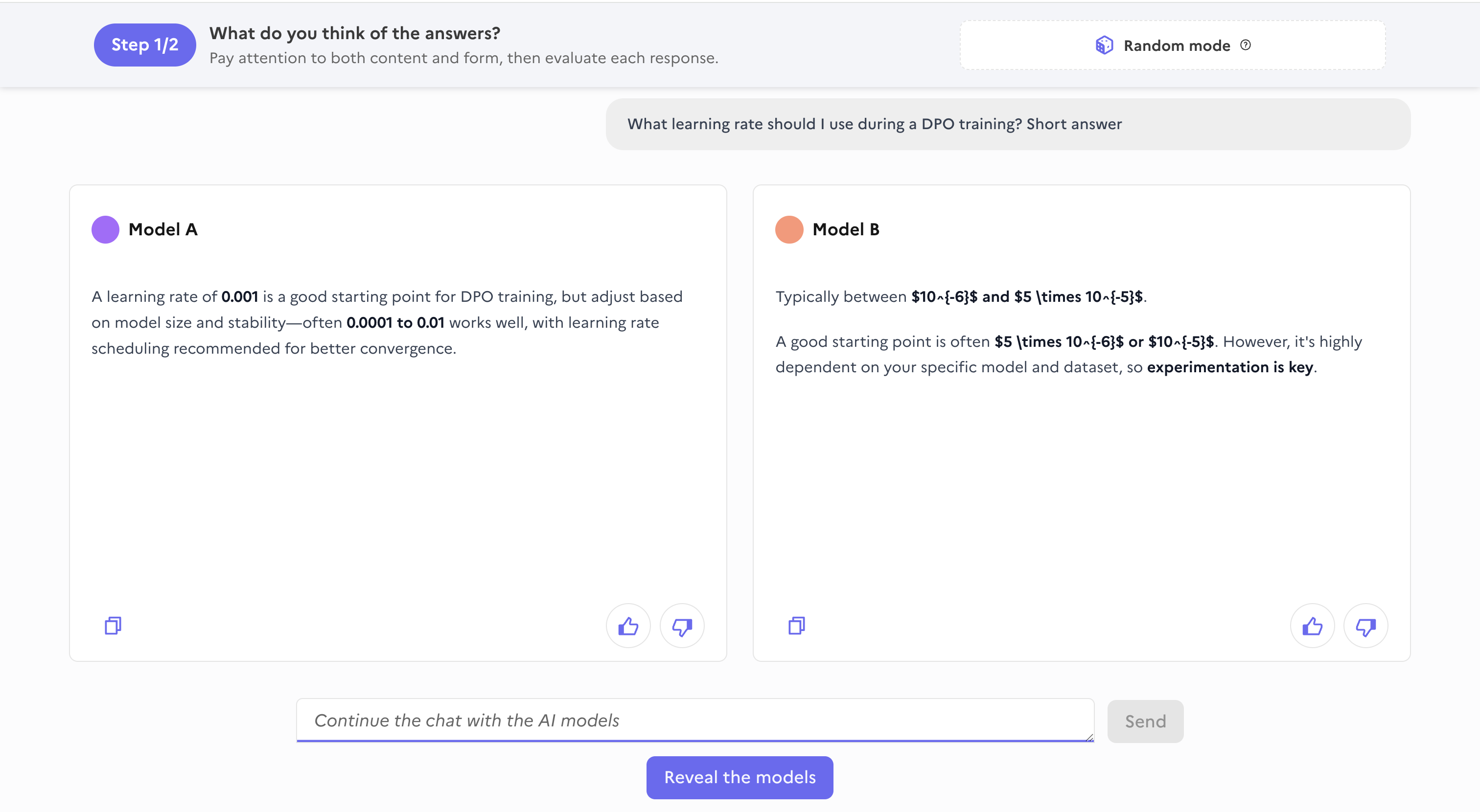
核心思路:compar:IA的核心思路是构建一个开放的、易于参与的平台,鼓励法语使用者提供真实的prompt和对不同语言模型的偏好反馈。通过盲配对比较的方式,用户可以在不了解模型身份的情况下,对两个模型的输出进行比较,从而获得更客观的偏好数据。这种方式降低了用户参与的门槛,并能有效收集到大规模的真实数据。
技术框架:compar:IA平台主要包含以下几个模块:1) Prompt收集模块:允许用户自由输入法语prompt。2) 模型输出模块:将prompt发送给多个不同的语言模型,获取模型的输出结果。3) 盲配对比较模块:将两个模型的输出结果呈现给用户,用户选择更偏好的一个。4) 数据过滤模块:自动过滤低质量或包含敏感信息的数据,保护用户隐私。5) 数据发布模块:以开放许可发布收集到的prompt、投票和用户反应等数据。
关键创新:compar:IA的关键创新在于其作为一个数字公共服务,旨在解决非英语语言模型训练数据稀缺的问题。它通过开放的平台和盲配对比较的方式,降低了用户参与的门槛,并能有效收集到大规模的真实数据。此外,该平台还注重用户隐私保护,通过自动过滤机制,避免敏感信息的泄露。
关键设计:平台采用用户友好的界面设计,降低用户参与的难度。盲配对比较的设计避免了用户对特定模型的先验认知带来的偏差。数据过滤模块采用多种策略,包括关键词过滤、内容审查等,以确保数据的质量和安全性。平台还提供API接口,方便研究人员使用收集到的数据进行模型训练和评估。
🖼️ 关键图片
📊 实验亮点
compar:IA平台已收集超过60万个自由格式prompt和25万个偏好投票,其中约89%的数据为法语。研究团队发布了包含对话、投票和反应的三个互补数据集,并构建了法语语言模型排行榜。这些数据和排行榜为法语LLM的研究和发展提供了宝贵的资源。
🎯 应用场景
该研究成果可应用于提升法语及其他低资源语言的大型语言模型性能,改善其文化适应性和安全性。收集到的数据可用于RLHF、DPO等训练方法,优化模型输出。该平台的设计思路和技术框架可推广至其他语言,构建多语言模型训练和评估的通用基础设施,促进人机交互研究。
📄 摘要(原文)
Large Language Models (LLMs) often show reduced performance, cultural alignment, and safety robustness in non-English languages, partly because English dominates both pre-training data and human preference alignment datasets. Training methods like Reinforcement Learning from Human Feedback (RLHF) and Direct Preference Optimization (DPO) require human preference data, which remains scarce and largely non-public for many languages beyond English. To address this gap, we introduce compar:IA, an open-source digital public service developed inside the French government and designed to collect large-scale human preference data from a predominantly French-speaking general audience. The platform uses a blind pairwise comparison interface to capture unconstrained, real-world prompts and user judgments across a diverse set of language models, while maintaining low participation friction and privacy-preserving automated filtering. As of 2026-02-07, compar:IA has collected over 600,000 free-form prompts and 250,000 preference votes, with approximately 89% of the data in French. We release three complementary datasets -- conversations, votes, and reactions -- under open licenses, and present initial analyses, including a French-language model leaderboard and user interaction patterns. Beyond the French context, compar:IA is evolving toward an international digital public good, offering reusable infrastructure for multilingual model training, evaluation, and the study of human-AI interaction.