Not All Layers Need Tuning: Selective Layer Restoration Recovers Diversity
作者: Bowen Zhang, Meiyi Wang, Harold Soh
分类: cs.CL, cs.AI
发布日期: 2026-02-06
备注: 16 pages, 7 figures, 12 tables
💡 一句话要点
提出选择性层恢复(SLR)方法,解决LLM后训练中生成多样性降低的问题。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 后训练 多样性 模式崩溃 层恢复
📋 核心要点
- 现有LLM后训练方法在提升指令遵循能力的同时,常导致生成多样性降低,出现模式崩溃问题。
- 论文提出选择性层恢复(SLR)方法,通过将特定层恢复到预训练权重,在多样性和质量间取得平衡。
- 实验表明,SLR在多种任务和模型上,均能显著提升输出多样性,同时保持较高的输出质量。
📝 摘要(中文)
大型语言模型(LLM)的后训练能够提升其指令遵循能力和有用性,但通常会降低生成的多样性,导致开放式场景中出现重复性输出,即模式崩溃现象。本文假设模式崩溃可能局限于特定层,并且将精心选择的层恢复到其预训练权重可以恢复多样性,同时保持较高的输出质量。为了验证这一假设并确定要恢复哪些层,本文设计了一个代理任务——约束随机字符(CRC),该任务具有显式的有效性集和自然的多样性目标。CRC上的结果揭示了跨恢复范围的清晰的多样性-有效性权衡,并确定了在质量损失最小的情况下增加多样性的配置。基于这些发现,本文提出了一种无需训练的方法——选择性层恢复(SLR),该方法将后训练模型中选定的层恢复到其预训练权重,从而产生一个具有相同架构和参数数量的混合模型,且不会产生额外的推理成本。在三个不同的任务(创意写作、开放式问答和多步推理)和三个不同的模型系列(Llama、Qwen和Gemma)中,SLR能够持续且显著地提高输出多样性,同时保持较高的输出质量。
🔬 方法详解
问题定义:大型语言模型在经过后训练(post-training)后,虽然在指令遵循和有用性方面有所提升,但常常会牺牲生成文本的多样性,导致模型在开放式生成任务中产生重复性的内容,即所谓的“模式崩溃”。现有的后训练方法缺乏对模型不同层功能差异的考虑,一刀切地更新所有层,可能是导致多样性下降的原因。
核心思路:论文的核心思路是,LLM的不同层可能负责不同的功能,而模式崩溃可能只发生在特定的层。因此,通过选择性地将某些层恢复到其预训练状态,可以在不牺牲模型性能的前提下,恢复生成文本的多样性。这种方法避免了重新训练整个模型,从而降低了计算成本。
技术框架:SLR方法主要包含以下几个步骤:1) 使用后训练的模型进行初步生成;2) 通过代理任务(CRC)确定需要恢复的层。CRC任务旨在评估不同层恢复策略对多样性和有效性的影响;3) 将选定的层恢复到其预训练权重,构建混合模型;4) 使用混合模型进行最终生成。整个过程无需额外的训练。
关键创新:SLR的关键创新在于其选择性地恢复模型层,而不是像传统方法那样对所有层进行统一处理。这种方法充分利用了LLM不同层具有不同功能的特性,从而能够在多样性和质量之间取得更好的平衡。此外,SLR是一种无需训练的方法,避免了高昂的计算成本。
关键设计:论文设计了一个名为“约束随机字符”(CRC)的代理任务,用于评估不同层恢复策略对多样性和有效性的影响。CRC任务要求模型生成满足特定约束条件的随机字符序列,并定义了相应的多样性和有效性指标。通过在CRC任务上进行实验,可以确定哪些层对多样性影响最大,以及恢复哪些层可以在不显著降低有效性的前提下最大化多样性。具体的层选择策略和恢复比例需要根据具体的模型和任务进行调整。
🖼️ 关键图片


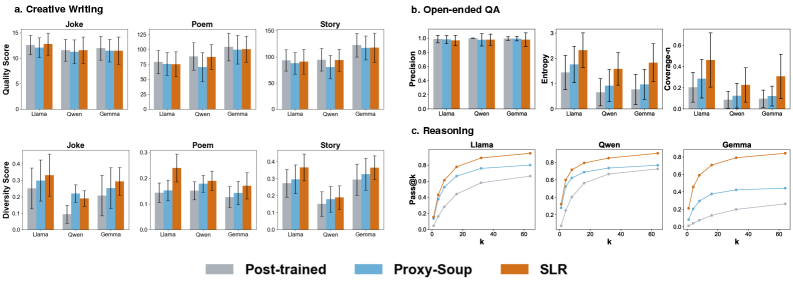
📊 实验亮点
实验结果表明,SLR方法在创意写作、开放式问答和多步推理等任务上,以及Llama、Qwen和Gemma等不同模型系列中,均能显著提高生成文本的多样性,同时保持较高的输出质量。具体的多样性提升幅度和质量损失程度取决于具体的任务和模型,但总体趋势是SLR能够在多样性和质量之间取得良好的平衡。
🎯 应用场景
该研究成果可应用于各种需要高生成多样性的自然语言处理任务,例如创意写作、故事生成、对话系统和开放式问答。通过恢复模型的多样性,可以避免生成重复、单调的内容,从而提升用户体验和应用价值。此外,该方法无需重新训练模型,具有很高的实用性。
📄 摘要(原文)
Post-training improves instruction-following and helpfulness of large language models (LLMs) but often reduces generation diversity, which leads to repetitive outputs in open-ended settings, a phenomenon known as mode collapse. Motivated by evidence that LLM layers play distinct functional roles, we hypothesize that mode collapse can be localized to specific layers and that restoring a carefully chosen range of layers to their pre-trained weights can recover diversity while maintaining high output quality. To validate this hypothesis and decide which layers to restore, we design a proxy task -- Constrained Random Character(CRC) -- with an explicit validity set and a natural diversity objective. Results on CRC reveal a clear diversity-validity trade-off across restoration ranges and identify configurations that increase diversity with minimal quality loss. Based on these findings, we propose Selective Layer Restoration (SLR), a training-free method that restores selected layers in a post-trained model to their pre-trained weights, yielding a hybrid model with the same architecture and parameter count, incurring no additional inference cost. Across three different tasks (creative writing, open-ended question answering, and multi-step reasoning) and three different model families (Llama, Qwen, and Gemma), we find SLR can consistently and substantially improve output diversity while maintaining high output quality.