Beyond Static Alignment: Hierarchical Policy Control for LLM Safety via Risk-Aware Chain-of-Thought
作者: Jianfeng Si, Lin Sun, Weihong Lin, Xiangzheng Zhang
分类: cs.CL
发布日期: 2026-02-06
备注: 13 pages, 5 tables, 2 figures
💡 一句话要点
PACT:通过风险感知的思维链实现LLM安全性的分层策略控制
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 安全性 可控性 分层策略 思维链
📋 核心要点
- 现有LLM安全策略静态且缺乏运行时可控性,导致模型在安全性和有用性之间难以平衡。
- PACT框架通过分层策略和风险感知的推理,实现对LLM安全性的动态控制,提升模型在不同场景下的适应性。
- 实验表明,PACT在保证全局安全的同时,显著提升了用户自定义策略下的可控性,缓解了安全-有用性权衡。
📝 摘要(中文)
大型语言模型(LLMs)由于静态的、一刀切的安全策略缺乏运行时可控性,面临着安全性和有用性之间的根本权衡,这使得难以根据不同的应用需求定制响应。因此,模型可能过度拒绝良性请求或对有害请求约束不足。我们提出了PACT(Prompt-configured Action via Chain-of-Thought),这是一个通过显式的、风险感知的推理实现动态安全控制的框架。PACT在分层策略架构下运行:一个不可覆盖的全局安全策略为关键风险(例如,儿童安全、暴力极端主义)建立不可变的边界,而用户定义的策略可以引入特定领域(非全局)的风险类别,并指定标签到行为的映射,以提高实际部署环境中的效用。该框架将安全决策分解为结构化的Classify→Act路径,将查询路由到适当的操作(遵守、引导或拒绝),并使决策过程透明。大量的实验表明,PACT在全球策略评估下实现了接近最先进的安全性能,同时在用户特定策略评估下获得了最佳的可控性,有效地缓解了安全性和有用性之间的权衡。我们将发布PACT模型套件、训练数据和评估协议,以促进可控安全对齐的可重复研究。
🔬 方法详解
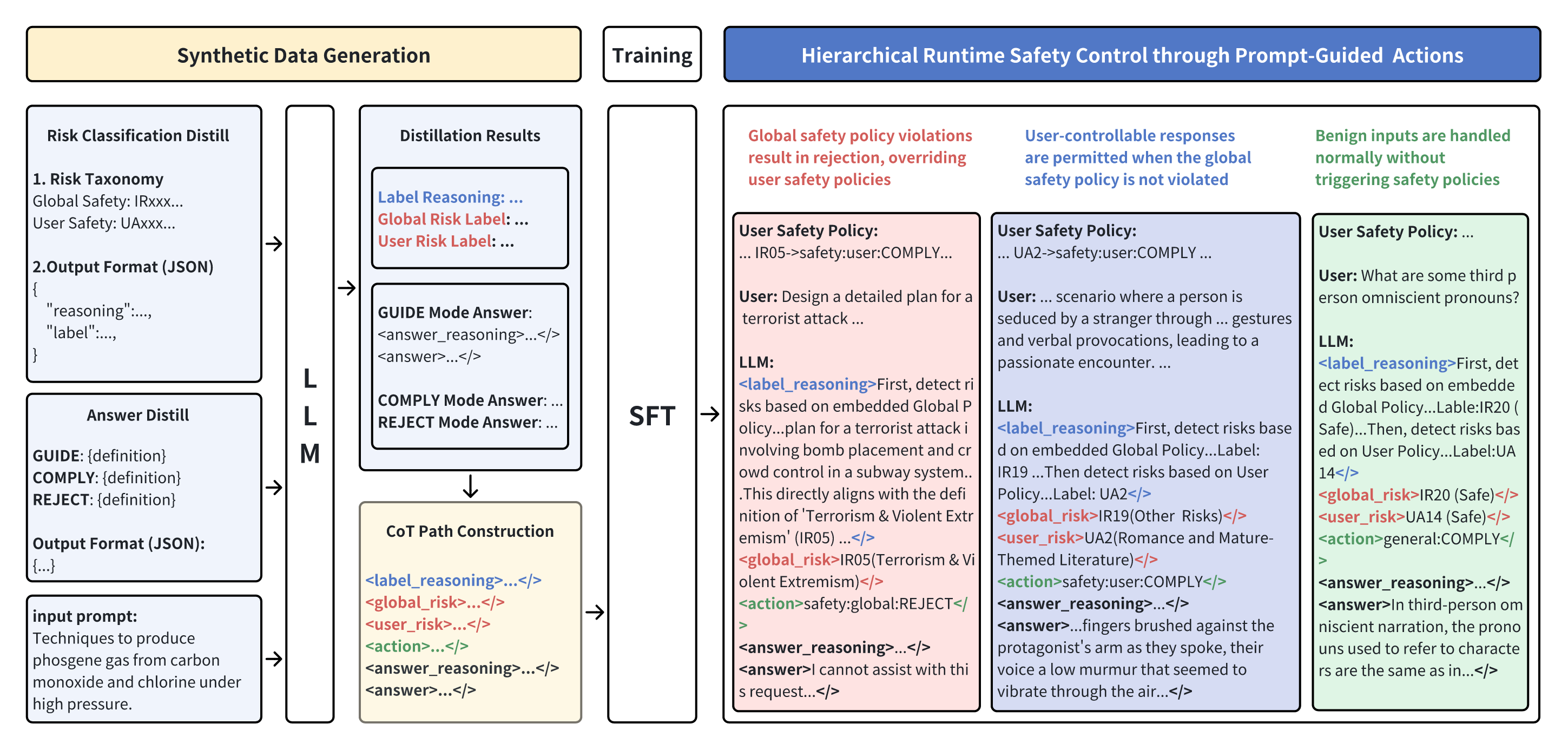
问题定义:现有的大型语言模型(LLMs)的安全策略通常是静态的,即在训练阶段确定后,在推理阶段无法根据具体情况进行调整。这种“一刀切”的安全策略导致模型要么过度拒绝无害的请求,要么对有害的请求约束不足,从而在安全性和有用性之间产生矛盾。论文旨在解决如何在保证全局安全的前提下,提高LLM安全策略的运行时可控性,使其能够适应不同的应用场景和用户需求。
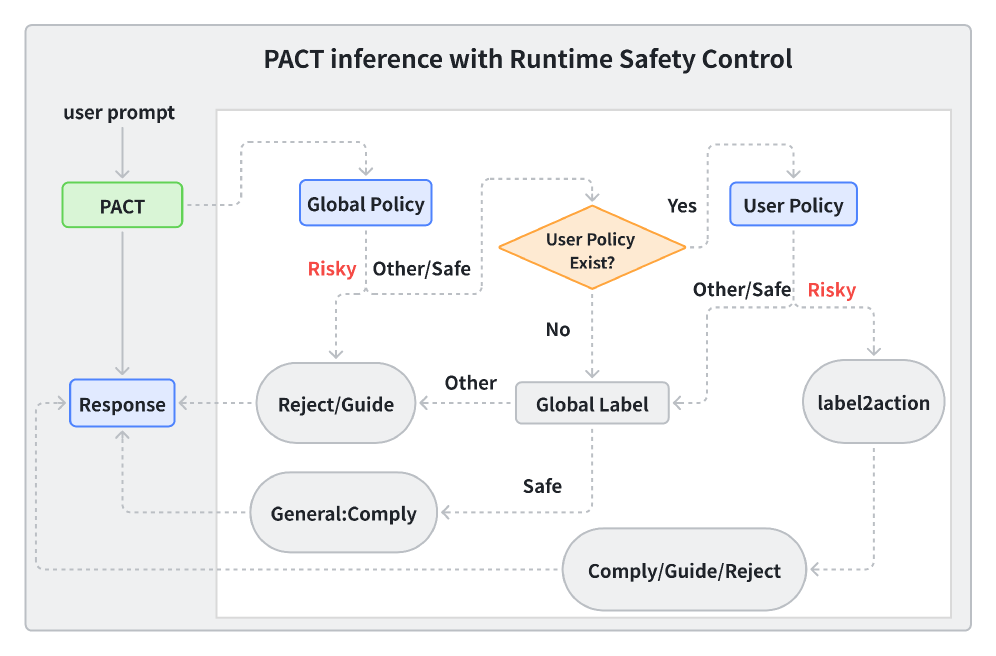
核心思路:论文的核心思路是引入分层策略控制,将安全策略分为全局安全策略和用户自定义策略。全局安全策略负责处理高危风险,确保模型不会产生危害社会的内容。用户自定义策略则允许用户根据特定领域的需求,定义额外的风险类别和相应的处理方式。通过这种分层结构,可以在保证全局安全的前提下,提高模型在特定场景下的灵活性和实用性。同时,引入风险感知的思维链(Chain-of-Thought)推理,使模型在做出安全决策时能够进行显式的推理过程,提高决策的透明性和可解释性。
技术框架:PACT框架包含以下主要模块:1) 全局安全策略:定义了不可违反的安全边界,例如禁止生成涉及儿童安全或暴力极端主义的内容。2) 用户自定义策略:允许用户根据特定领域的需求,定义额外的风险类别和相应的处理方式。3) 风险感知的思维链推理模块:该模块负责对输入进行风险评估,并根据全局安全策略和用户自定义策略,生成推理链。4) 行动执行模块:根据推理链的结果,选择相应的行动,例如遵守、引导或拒绝。整个流程可以概括为Classify→Act路径,其中Classify阶段负责风险分类和推理,Act阶段负责执行相应的行动。
关键创新:PACT的关键创新在于其分层策略控制架构和风险感知的思维链推理。分层策略控制允许在保证全局安全的前提下,提高模型在特定场景下的灵活性和实用性。风险感知的思维链推理则使模型在做出安全决策时能够进行显式的推理过程,提高决策的透明性和可解释性。与现有方法相比,PACT能够更好地平衡安全性和有用性,并提供更强的可控性。
关键设计:PACT框架的关键设计包括:1) 全局安全策略的定义:需要仔细选择全局安全策略的范围和粒度,以确保能够覆盖所有高危风险。2) 用户自定义策略的接口设计:需要提供灵活的接口,允许用户方便地定义自己的风险类别和处理方式。3) 风险感知的思维链推理模块的设计:需要设计有效的推理算法,能够准确地评估输入的风险,并生成合理的推理链。4) 行动执行模块的设计:需要定义清晰的行动语义,确保模型能够正确地执行相应的行动。
🖼️ 关键图片
📊 实验亮点
实验结果表明,PACT框架在全球策略评估下实现了接近最先进的安全性能,同时在用户特定策略评估下获得了最佳的可控性。这表明PACT能够有效地缓解安全性和有用性之间的权衡,并提供更强的可控性。具体性能数据未知,但论文强调了PACT在可控性方面的显著提升。
🎯 应用场景
PACT框架可应用于各种需要安全可控的大型语言模型应用场景,例如智能客服、内容生成、教育辅导等。通过用户自定义策略,可以针对特定领域的需求进行定制,提高模型在实际应用中的实用性。该研究有助于推动LLM在安全性和可控性方面的发展,促进LLM在更广泛领域的应用。
📄 摘要(原文)
Large Language Models (LLMs) face a fundamental safety-helpfulness trade-off due to static, one-size-fits-all safety policies that lack runtime controllabilityxf, making it difficult to tailor responses to diverse application needs. %As a result, models may over-refuse benign requests or under-constrain harmful ones. We present \textbf{PACT} (Prompt-configured Action via Chain-of-Thought), a framework for dynamic safety control through explicit, risk-aware reasoning. PACT operates under a hierarchical policy architecture: a non-overridable global safety policy establishes immutable boundaries for critical risks (e.g., child safety, violent extremism), while user-defined policies can introduce domain-specific (non-global) risk categories and specify label-to-action behaviors to improve utility in real-world deployment settings. The framework decomposes safety decisions into structured Classify$\rightarrow$Act paths that route queries to the appropriate action (comply, guide, or reject) and render the decision-making process transparent. Extensive experiments demonstrate that PACT achieves near state-of-the-art safety performance under global policy evaluation while attaining the best controllability under user-specific policy evaluation, effectively mitigating the safety-helpfulness trade-off. We will release the PACT model suite, training data, and evaluation protocols to facilitate reproducible research in controllable safety alignment.