Do Prompts Guarantee Safety? Mitigating Toxicity from LLM Generations through Subspace Intervention
作者: Himanshu Singh, Ziwei Xu, A. V. Subramanyam, Mohan Kankanhalli
分类: cs.CL, cs.CR
发布日期: 2026-02-06
💡 一句话要点
提出基于子空间干预的LLM解毒方法,有效降低生成文本中的毒性。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 毒性检测 子空间干预 文本生成 安全性 解毒 表示学习 自然语言处理
📋 核心要点
- 大型语言模型存在生成有毒内容的风险,现有方法难以在安全性和流畅性之间取得平衡。
- 该论文提出一种子空间干预策略,通过抑制模型表示中的毒性模式来降低生成文本的毒性。
- 实验表明,该方法在降低毒性的同时,保持了文本的流畅性,优于现有基线方法。
📝 摘要(中文)
大型语言模型(LLMs)是强大的文本生成器,但即使在给定看似无害的提示时,也可能产生有毒或有害的内容。这构成了一个严重的安全挑战,并可能导致现实世界的危害。毒性通常是微妙的且依赖于上下文的,因此难以在token级别或通过粗略的句子级别信号进行检测。此外,减轻毒性的努力常常面临安全性和生成文本的连贯性或流畅性之间的权衡。在这项工作中,我们提出了一种有针对性的子空间干预策略,用于识别和抑制底层模型表示中的隐藏毒性模式,同时保留生成安全流畅内容的能力。在RealToxicityPrompts上,与现有基线相比,我们的方法实现了强大的缓解性能,并且对推理复杂性的影响最小。在多个LLM上,我们的方法将最先进的解毒系统的毒性降低了8-20%,同时保持了相当的流畅性。通过广泛的定量和定性分析,我们表明我们的方法实现了有效的毒性降低,而不会损害生成性能,并且始终优于现有基线。
🔬 方法详解
问题定义:大型语言模型(LLMs)在生成文本时,即使输入无害的提示,也可能产生有毒或有害的内容。现有的解毒方法通常难以在降低毒性和保持生成文本的流畅性和连贯性之间取得平衡。此外,毒性检测本身就是一个难题,因为毒性往往是微妙的,并且依赖于上下文信息。
核心思路:该论文的核心思路是通过干预LLM的内部表示空间,来抑制模型中与毒性相关的隐藏模式。具体来说,该方法旨在识别并抑制模型在生成过程中激活的、与毒性相关的子空间,从而在不影响模型整体生成能力的前提下,降低生成文本的毒性。
技术框架:该方法主要包含以下几个阶段:1) 毒性子空间识别:利用已知的有毒数据,分析模型在生成有毒文本时的内部表示,从而识别出与毒性相关的子空间。2) 子空间干预:在模型生成过程中,对激活的毒性子空间进行抑制,从而降低生成有毒文本的概率。3) 生成文本评估:评估生成文本的毒性和流畅性,以验证方法的有效性。
关键创新:该方法的关键创新在于提出了基于子空间干预的解毒策略。与传统的基于规则或基于分类器的解毒方法不同,该方法直接干预模型的内部表示,从而更有效地抑制毒性模式。此外,该方法能够在降低毒性的同时,保持生成文本的流畅性。
关键设计:论文中可能涉及的关键设计包括:1) 如何定义和识别毒性子空间(例如,使用主成分分析或奇异值分解);2) 如何进行子空间干预(例如,通过投影或正则化);3) 如何平衡毒性降低和流畅性保持(例如,通过调整干预强度)。具体的参数设置、损失函数和网络结构等技术细节需要在论文中进一步查找。
🖼️ 关键图片


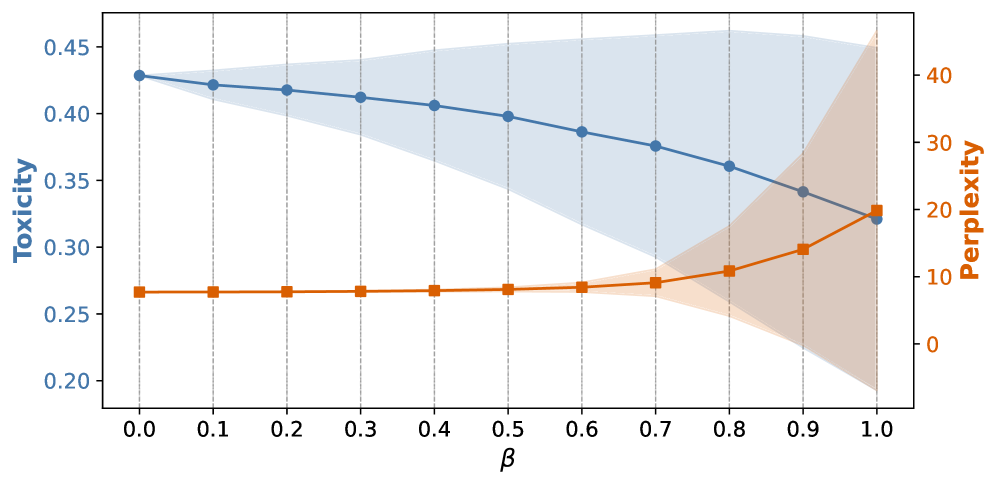
📊 实验亮点
该方法在RealToxicityPrompts数据集上取得了显著的性能提升,与现有基线方法相比,在多个LLM上将最先进的解毒系统的毒性降低了8-20%,同时保持了相当的流畅性。实验结果表明,该方法能够有效降低生成文本的毒性,且不会显著影响生成质量,优于现有基线方法。
🎯 应用场景
该研究成果可应用于各种需要使用大型语言模型生成文本的场景,例如聊天机器人、内容创作、代码生成等。通过降低生成文本的毒性,可以提高用户体验,避免潜在的法律风险,并促进人工智能技术的健康发展。该技术还有助于构建更安全、更可靠的人工智能系统。
📄 摘要(原文)
Large Language Models (LLMs) are powerful text generators, yet they can produce toxic or harmful content even when given seemingly harmless prompts. This presents a serious safety challenge and can cause real-world harm. Toxicity is often subtle and context-dependent, making it difficult to detect at the token level or through coarse sentence-level signals. Moreover, efforts to mitigate toxicity often face a trade-off between safety and the coherence, or fluency of the generated text. In this work, we present a targeted subspace intervention strategy for identifying and suppressing hidden toxic patterns from underlying model representations, while preserving overall ability to generate safe fluent content. On the RealToxicityPrompts, our method achieves strong mitigation performance compared to existing baselines, with minimal impact on inference complexity. Across multiple LLMs, our approach reduces toxicity of state-of-the-art detoxification systems by 8-20%, while maintaining comparable fluency. Through extensive quantitative and qualitative analyses, we show that our approach achieves effective toxicity reduction without impairing generative performance, consistently outperforming existing baselines.