Improve Large Language Model Systems with User Logs
作者: Changyue Wang, Weihang Su, Qingyao Ai, Yiqun Liu
分类: cs.CL, cs.AI
发布日期: 2026-02-06
🔗 代码/项目: GITHUB
💡 一句话要点
提出UNO框架,利用用户日志提升大语言模型系统性能
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 用户日志 持续学习 反馈优化 认知差距
📋 核心要点
- 现有大语言模型系统难以有效利用用户日志中蕴含的丰富反馈信息,受限于日志的非结构化和噪声。
- UNO框架通过提炼日志为半结构化数据,并利用查询反馈驱动的聚类管理数据异质性,量化认知差距。
- 实验表明,UNO在有效性和效率上均优于RAG和基于内存的基线方法,实现了显著的性能提升。
📝 摘要(中文)
大规模训练数据和模型参数长期以来推动着大语言模型(LLMs)的进步,但这种模式正日益受到高质量数据稀缺和计算成本收益递减的限制。因此,最近的工作越来越关注从真实部署中的持续学习,其中用户交互日志提供了丰富的真实人类反馈和程序知识。然而,由于用户日志的非结构化和噪声性质,从中学习具有挑战性。原始LLM系统通常难以区分有用的反馈信号和嘈杂的用户行为,并且用户日志收集和模型优化之间的差异(例如,离策略优化问题)进一步加剧了这个问题。为此,我们提出了UNO(User log-driveN Optimization),一个统一的框架,用于利用用户日志改进LLM系统(LLMsys)。UNO首先将日志提炼成半结构化的规则和偏好对,然后采用查询和反馈驱动的聚类来管理数据异质性,最后量化模型先验知识与日志数据之间的认知差距。这种评估指导LLMsys自适应地过滤掉噪声反馈,并构建不同的模块来处理从用户日志中提取的主要和反思性经验,从而改进未来的响应。大量实验表明,UNO实现了最先进的有效性和效率,显著优于检索增强生成(RAG)和基于内存的基线。
🔬 方法详解
问题定义:论文旨在解决如何有效利用用户日志来持续改进大语言模型系统的问题。现有方法,如直接使用原始日志进行训练,容易受到日志中噪声和非结构化数据的影响,导致模型性能下降。此外,用户日志的收集和模型优化之间存在差异,导致离策略优化问题,进一步加剧了学习的难度。
核心思路:UNO的核心思路是将用户日志提炼成更结构化和有用的信息,并根据模型自身的知识状态自适应地利用这些信息。通过将日志转化为半结构化的规则和偏好对,可以更容易地提取有用的反馈信号。同时,通过量化模型先验知识与日志数据之间的认知差距,可以指导模型更有选择性地学习,避免受到噪声的影响。
技术框架:UNO框架包含以下几个主要模块:1) 日志提炼:将原始用户日志转化为半结构化的规则和偏好对。2) 数据聚类:采用查询和反馈驱动的聚类方法,将日志数据划分为不同的簇,以管理数据异质性。3) 认知差距量化:量化模型先验知识与日志数据之间的差距,用于指导后续的学习过程。4) 自适应学习:根据认知差距,自适应地过滤噪声反馈,并构建不同的模块来处理从用户日志中提取的主要和反思性经验。
关键创新:UNO的关键创新在于其统一的框架,能够有效地将非结构化的用户日志转化为可用于模型优化的信息。特别是,认知差距量化的引入,使得模型能够更有选择性地学习,避免受到噪声的影响。此外,查询和反馈驱动的聚类方法能够有效地管理数据异质性,提高学习效率。
关键设计:论文中没有详细描述具体的参数设置、损失函数或网络结构。但是,可以推断,日志提炼模块可能涉及到自然语言处理技术,如实体识别、关系抽取等。数据聚类模块可能采用基于距离或密度的聚类算法。认知差距量化模块可能涉及到计算模型输出与日志数据之间的相似度或差异度。自适应学习模块可能采用强化学习或元学习的方法,根据认知差距动态调整学习策略。
🖼️ 关键图片
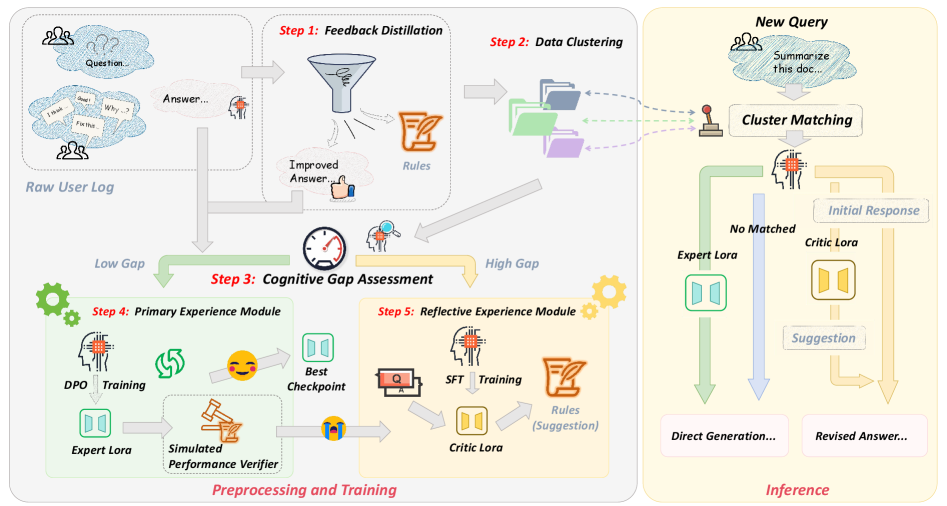

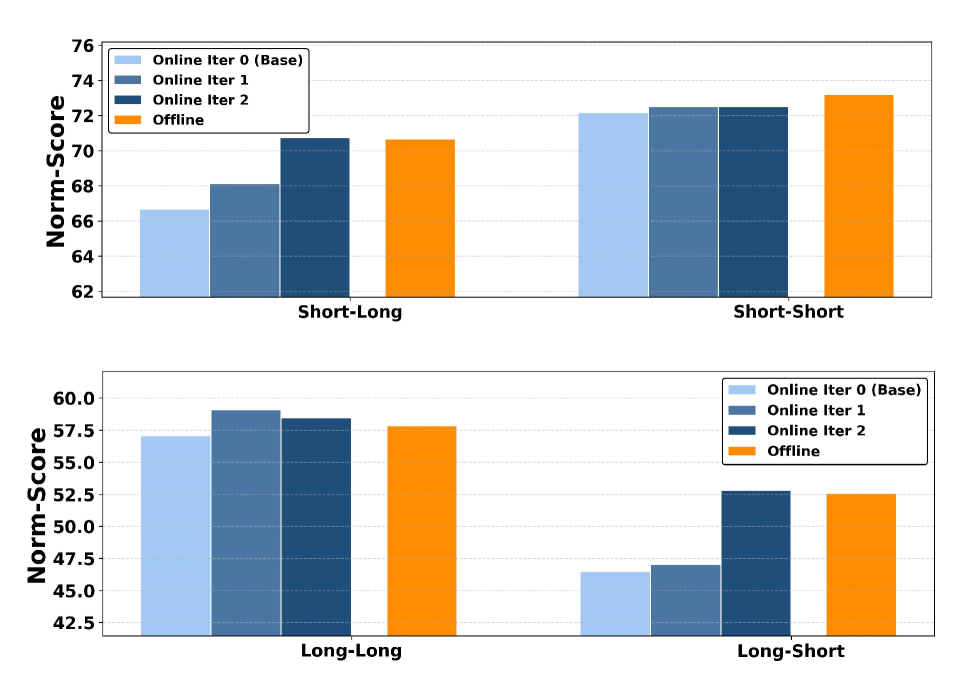
📊 实验亮点
实验结果表明,UNO框架在多个数据集上均取得了显著的性能提升,超越了RAG和基于内存的基线方法。具体而言,UNO在某些指标上实现了超过10%的相对提升,证明了其在利用用户日志改进大语言模型系统方面的有效性。代码已开源。
🎯 应用场景
该研究成果可应用于各种基于大语言模型的智能对话系统、问答系统和推荐系统。通过持续学习用户交互日志,系统能够不断改进其响应质量和用户体验。例如,在智能客服领域,系统可以根据用户的反馈不断优化其回复策略,提高问题解决率和用户满意度。此外,该方法还可以用于个性化推荐,根据用户的历史行为和偏好,提供更精准的推荐结果。
📄 摘要(原文)
Scaling training data and model parameters has long driven progress in large language models (LLMs), but this paradigm is increasingly constrained by the scarcity of high-quality data and diminishing returns from rising computational costs. As a result, recent work is increasing the focus on continual learning from real-world deployment, where user interaction logs provide a rich source of authentic human feedback and procedural knowledge. However, learning from user logs is challenging due to their unstructured and noisy nature. Vanilla LLM systems often struggle to distinguish useful feedback signals from noisy user behavior, and the disparity between user log collection and model optimization (e.g., the off-policy optimization problem) further strengthens the problem. To this end, we propose UNO (User log-driveN Optimization), a unified framework for improving LLM systems (LLMsys) with user logs. UNO first distills logs into semi-structured rules and preference pairs, then employs query-and-feedback-driven clustering to manage data heterogeneity, and finally quantifies the cognitive gap between the model's prior knowledge and the log data. This assessment guides the LLMsys to adaptively filter out noisy feedback and construct different modules for primary and reflective experiences extracted from user logs, thereby improving future responses. Extensive experiments show that UNO achieves state-of-the-art effectiveness and efficiency, significantly outperforming Retrieval Augmented Generation (RAG) and memory-based baselines. We have open-sourced our code at https://github.com/bebr2/UNO .