Cost-Aware Model Selection for Text Classification: Multi-Objective Trade-offs Between Fine-Tuned Encoders and LLM Prompting in Production
作者: Alberto Andres Valdes Gonzalez
分类: cs.CL
发布日期: 2026-02-06
备注: 26 pages, 12 figures. Empirical benchmark comparing fine-tuned encoders and LLM prompting for text classification under cost and latency constraints
💡 一句话要点
针对文本分类,提出一种考虑成本的多目标模型选择方法,平衡微调编码器与LLM Prompting。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 文本分类 模型选择 多目标优化 大型语言模型 微调 成本效益 Pareto前沿
📋 核心要点
- 现有文本分类模型选择主要关注预测性能,忽略了生产环境中的运营成本和延迟等约束。
- 提出一种多目标模型选择方法,综合考虑预测性能、推理延迟和货币成本,实现三者之间的权衡。
- 实验表明,微调的encoder模型在保证甚至超越LLM分类性能的同时,显著降低了成本和延迟。
📝 摘要(中文)
大型语言模型(LLM),如GPT-4o和Claude Sonnet 4.5,在开放式推理和生成语言任务中表现出强大的能力,从而被广泛应用于各种NLP应用。然而,对于具有固定标签空间的结构化文本分类问题,模型选择通常仅由预测性能驱动,而忽略了生产系统中遇到的运营约束。本文系统地比较了两种用于文本分类的对比范式:零样本和少样本prompt-based大型语言模型,以及完全微调的encoder-only架构。我们在四个标准基准(IMDB、SST-2、AG News和DBPedia)上评估了这些方法,测量预测质量(macro F1)、推理延迟和货币成本。我们将模型评估定义为一个多目标决策问题,并使用Pareto前沿投影和反映不同部署方案的参数化效用函数来分析权衡。结果表明,来自BERT系列的微调encoder-based模型实现了有竞争力的,通常是卓越的分类性能,同时以比零样本和少样本LLM prompting低一到两个数量级的成本和延迟运行。总的来说,我们的研究结果表明,不加区分地使用大型语言模型进行标准文本分类工作负载可能会导致次优的系统级结果。相反,微调的encoder成为结构化NLP管道的强大而高效的组件,而LLM更适合作为混合架构中的补充元素。我们发布所有代码、数据集和评估协议,以支持可重复性和成本意识的NLP系统设计。
🔬 方法详解
问题定义:论文旨在解决文本分类任务中,如何在预测性能、推理延迟和货币成本之间进行权衡的问题。现有方法通常只关注预测性能,而忽略了实际部署中的资源限制,导致系统效率低下。尤其是在生产环境中,高昂的LLM推理成本和延迟是不可忽视的痛点。
核心思路:论文的核心思路是将模型选择视为一个多目标优化问题,通过综合考虑预测性能(Macro F1)、推理延迟和货币成本,找到在不同约束条件下最优的模型配置。通过Pareto前沿分析,可以清晰地展现不同模型在多个目标上的权衡关系,从而帮助用户根据实际需求做出明智的选择。
技术框架:论文的整体框架包括以下几个步骤:1) 选择代表性的文本分类数据集(IMDB, SST-2, AG News, DBPedia);2) 评估两种主要的模型范式:零样本/少样本LLM prompting和微调的encoder模型(BERT系列);3) 测量每个模型的预测性能、推理延迟和货币成本;4) 使用Pareto前沿分析和参数化效用函数,分析不同模型在多个目标上的权衡关系;5) 提供代码、数据集和评估协议,以支持可重复性和成本意识的NLP系统设计。
关键创新:论文的关键创新在于将成本意识引入到文本分类模型的选择过程中,并将其形式化为一个多目标优化问题。通过比较LLM prompting和微调encoder模型,揭示了在标准文本分类任务中,过度依赖LLM可能导致系统效率低下的问题。强调了在实际应用中,需要综合考虑多个目标,选择最适合特定场景的模型。
关键设计:论文的关键设计包括:1) 使用Macro F1作为预测性能的指标;2) 精确测量每个模型的推理延迟和货币成本;3) 使用Pareto前沿分析,可视化不同模型在多个目标上的权衡关系;4) 设计参数化效用函数,以反映不同部署方案下的偏好。具体的参数设置和模型结构沿用了BERT等经典模型的设计,重点在于评估和比较不同模型的性能和成本。
🖼️ 关键图片
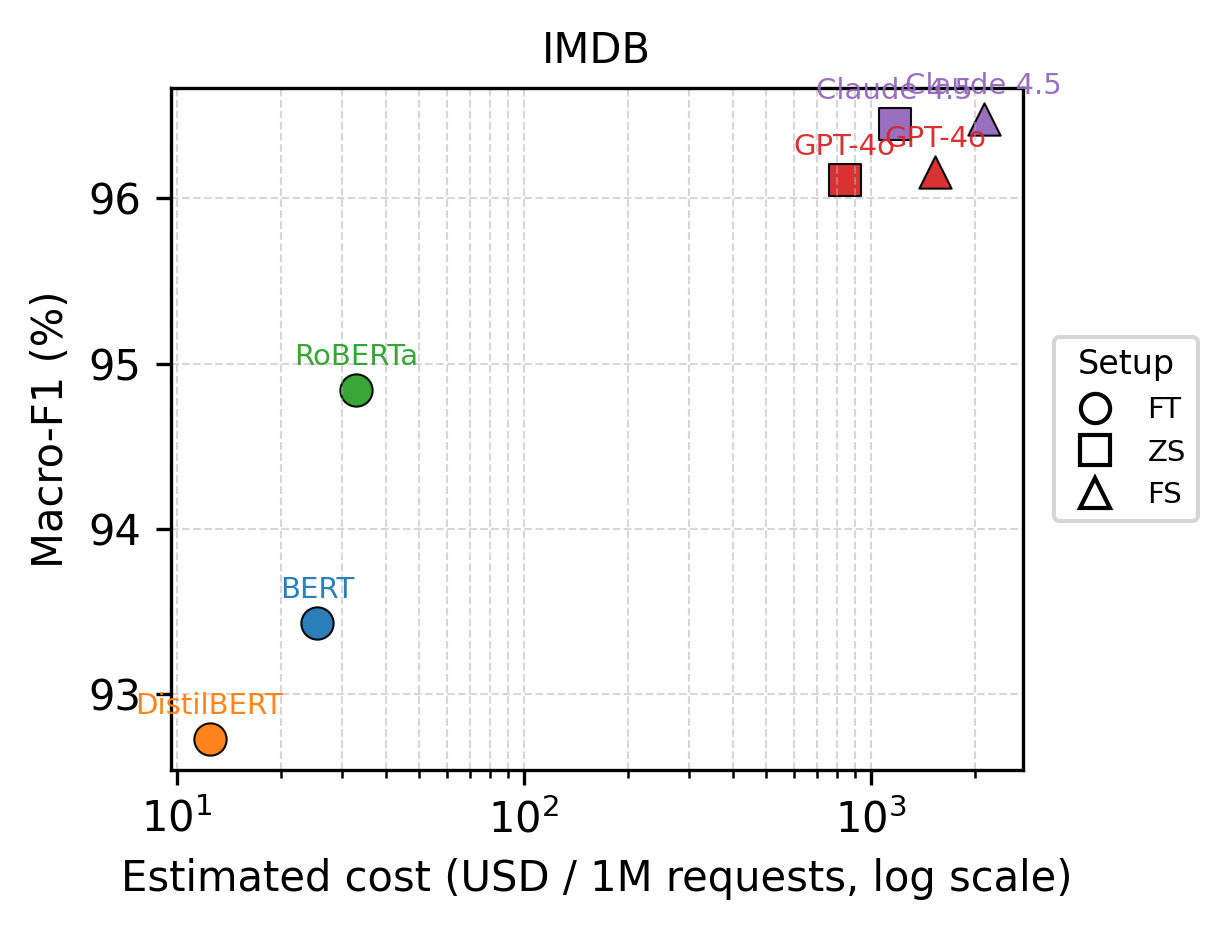
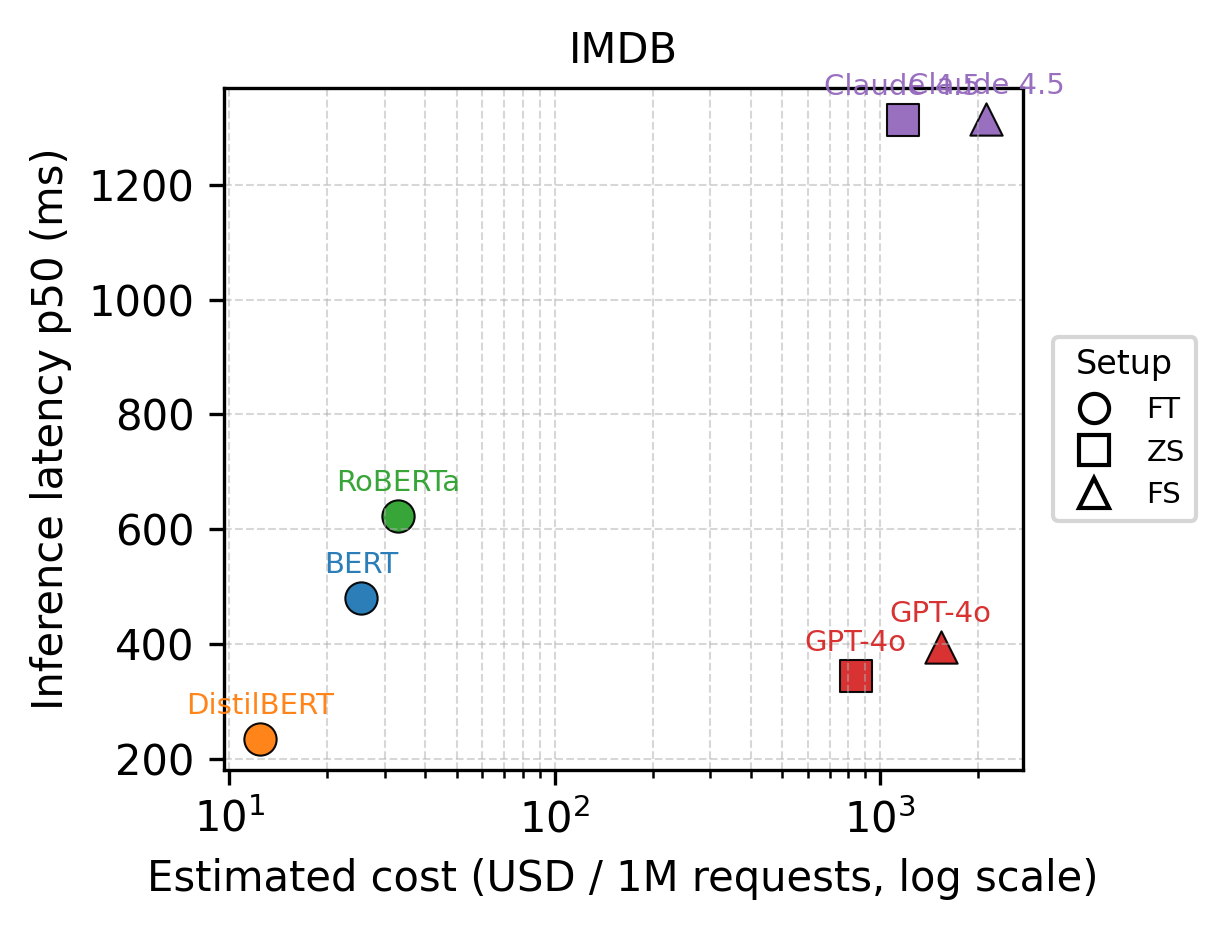
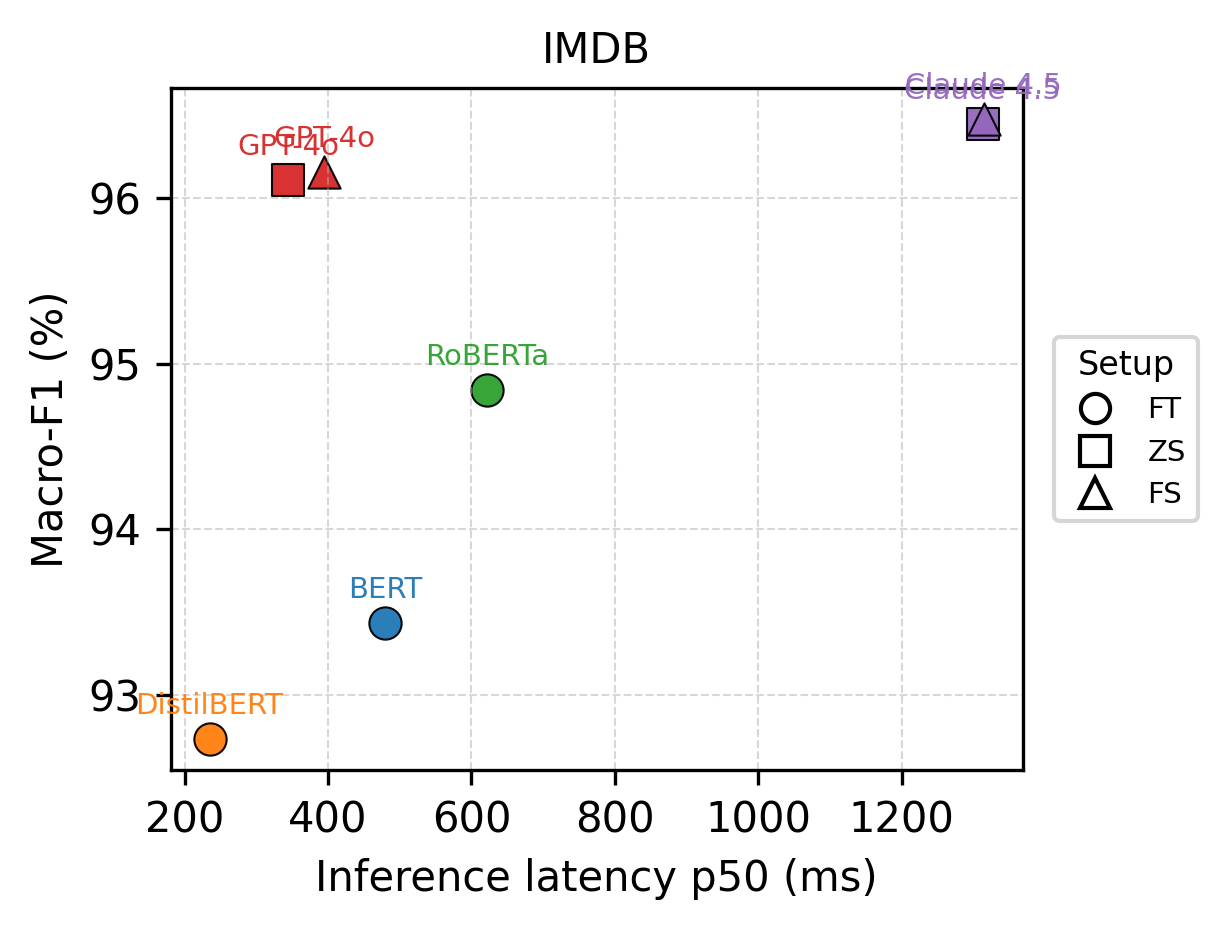
📊 实验亮点
实验结果表明,在四个标准文本分类数据集上,微调的encoder模型(BERT系列)在保证甚至超越LLM分类性能的同时,实现了比零样本/少样本LLM prompting低一到两个数量级的成本和延迟。例如,在某些数据集上,微调BERT模型的Macro F1与LLM相当,但推理成本却大幅降低。
🎯 应用场景
该研究成果可应用于各种需要进行文本分类的场景,例如情感分析、主题分类、垃圾邮件检测等。通过综合考虑预测性能、推理延迟和货币成本,可以帮助企业选择最适合其需求的模型,从而优化资源利用率,降低运营成本,并提高用户体验。该研究对于构建高效、经济的NLP系统具有重要的实际价值和指导意义。
📄 摘要(原文)
Large language models (LLMs) such as GPT-4o and Claude Sonnet 4.5 have demonstrated strong capabilities in open-ended reasoning and generative language tasks, leading to their widespread adoption across a broad range of NLP applications. However, for structured text classification problems with fixed label spaces, model selection is often driven by predictive performance alone, overlooking operational constraints encountered in production systems. In this work, we present a systematic comparison of two contrasting paradigms for text classification: zero- and few-shot prompt-based large language models, and fully fine-tuned encoder-only architectures. We evaluate these approaches across four canonical benchmarks (IMDB, SST-2, AG News, and DBPedia), measuring predictive quality (macro F1), inference latency, and monetary cost. We frame model evaluation as a multi-objective decision problem and analyze trade-offs using Pareto frontier projections and a parameterized utility function reflecting different deployment regimes. Our results show that fine-tuned encoder-based models from the BERT family achieve competitive, and often superior, classification performance while operating at one to two orders of magnitude lower cost and latency compared to zero- and few-shot LLM prompting. Overall, our findings suggest that indiscriminate use of large language models for standard text classification workloads can lead to suboptimal system-level outcomes. Instead, fine-tuned encoders emerge as robust and efficient components for structured NLP pipelines, while LLMs are better positioned as complementary elements within hybrid architectures. We release all code, datasets, and evaluation protocols to support reproducibility and cost-aware NLP system design.