Can Post-Training Transform LLMs into Causal Reasoners?
作者: Junqi Chen, Sirui Chen, Chaochao Lu
分类: cs.CL, cs.AI, cs.LG
发布日期: 2026-02-06
🔗 代码/项目: GITHUB
💡 一句话要点
通过后训练将大语言模型转化为因果推理器
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 因果推理 大语言模型 后训练 数据集 鲁棒性
📋 核心要点
- 现有大语言模型在因果推理方面能力有限,缺乏对后训练如何提升这些能力的深入研究。
- 论文提出通过有针对性的后训练,使较小的LLM能够进行有竞争力的因果推理,提升泛化性和鲁棒性。
- 实验结果表明,适当的后训练能显著提升LLM的因果推理能力,甚至超越更大的模型,并在真实条件下表现出强大的性能。
📝 摘要(中文)
因果推断对于决策至关重要,但对于非专业人士来说仍然具有挑战性。虽然大型语言模型(LLM)在该领域展现出潜力,但其精确的因果估计能力仍然有限,并且后训练对这些能力的影响尚未得到充分探索。本文研究了后训练在多大程度上可以提高LLM的因果推理能力。我们引入了CauGym,这是一个包含七个核心因果任务的综合数据集,用于训练和五个不同的测试集。使用该数据集,我们系统地评估了五种后训练方法:SFT、DPO、KTO、PPO和GRPO。在五个领域内和四个现有基准测试中,我们的实验表明,适当的后训练使较小的LLM能够进行有竞争力的因果推理,通常超过更大的模型。我们的14B参数模型在CaLM基准测试中实现了93.5%的准确率,而OpenAI o3的准确率为55.4%。此外,经过后训练的LLM在诸如分布偏移和噪声数据等真实条件下表现出强大的泛化性和鲁棒性。总而言之,这些发现提供了第一个系统的证据,表明有针对性的后训练可以产生可靠且鲁棒的基于LLM的因果推理器。我们的数据和GRPO模型可在https://github.com/OpenCausaLab/CauGym获取。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)在因果推理方面能力不足的问题。现有方法要么依赖于非常大的模型,要么缺乏在真实世界条件下的鲁棒性。因此,如何通过更有效的方法,例如后训练,来提升LLM的因果推理能力,同时保持模型的规模和鲁棒性,是本文要解决的核心问题。
核心思路:论文的核心思路是通过有针对性的后训练来提升LLM的因果推理能力。作者认为,通过在专门设计的因果推理数据集上进行后训练,可以使LLM更好地学习因果关系,从而提高其在因果推理任务中的表现。这种方法旨在利用LLM的预训练知识,并通过后训练进行微调,使其更擅长因果推理。
技术框架:论文的技术框架主要包括以下几个部分:1) 构建一个名为CauGym的综合数据集,包含七个核心因果任务用于训练和五个不同的测试集。2) 选择五种后训练方法(SFT、DPO、KTO、PPO和GRPO)进行评估。3) 在CauGym数据集上对LLM进行后训练。4) 在五个领域内和四个现有基准测试中评估后训练后的LLM的因果推理能力。5) 分析实验结果,评估不同后训练方法的效果和LLM的鲁棒性。
关键创新:论文的关键创新点在于:1) 系统地研究了后训练对LLM因果推理能力的影响。2) 构建了一个全面的因果推理数据集CauGym,用于训练和评估LLM。3) 提出了GRPO(未知)方法,并在实验中取得了较好的效果。4) 证明了通过适当的后训练,较小的LLM可以达到甚至超过大型模型的因果推理能力。
关键设计:论文的关键设计包括:1) CauGym数据集的设计,涵盖了多种因果推理任务,旨在全面评估LLM的因果推理能力。2) 五种后训练方法的选择,旨在比较不同后训练方法的效果。3) 实验评估的设计,包括领域内和领域外测试,以及在真实世界条件下的鲁棒性测试。具体的参数设置、损失函数和网络结构等技术细节在论文中可能有所描述,但摘要中未提及。
🖼️ 关键图片

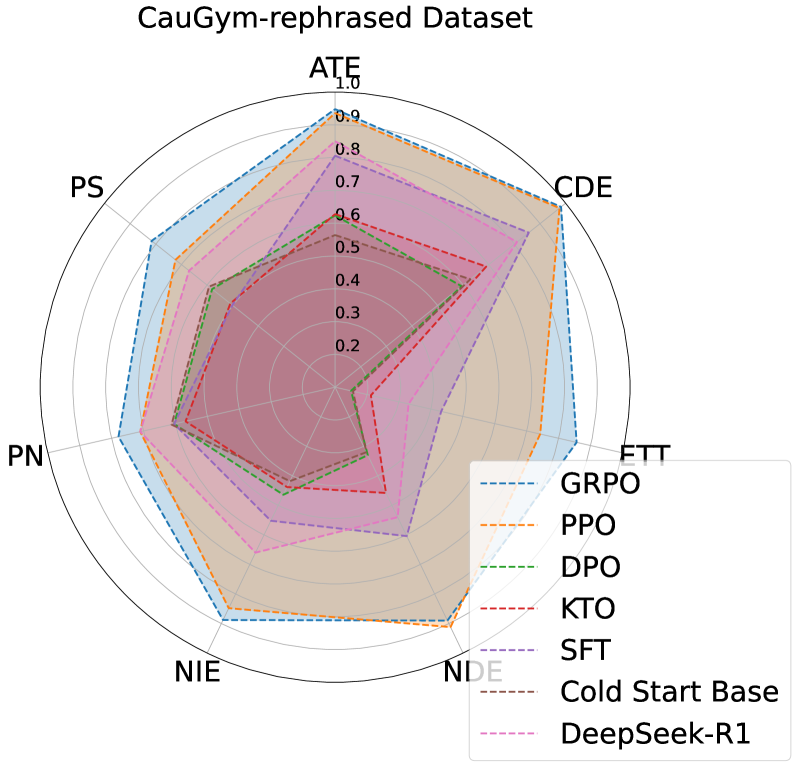

📊 实验亮点
实验结果表明,经过适当后训练的14B参数模型在CaLM基准测试中达到了93.5%的准确率,显著优于OpenAI o3的55.4%。此外,后训练后的LLM在分布偏移和噪声数据等真实条件下表现出强大的泛化性和鲁棒性。这些结果表明,后训练是提升LLM因果推理能力的有效途径,并且可以使较小的模型达到甚至超过大型模型的性能。
🎯 应用场景
该研究成果可应用于多个领域,如医疗诊断、金融风险评估、政策制定等,在这些领域中,因果推理至关重要。通过提升LLM的因果推理能力,可以帮助决策者更好地理解复杂系统中的因果关系,从而做出更明智的决策。未来,该技术有望被集成到各种智能系统中,为人们提供更可靠的因果推理支持。
📄 摘要(原文)
Causal inference is essential for decision-making but remains challenging for non-experts. While large language models (LLMs) show promise in this domain, their precise causal estimation capabilities are still limited, and the impact of post-training on these abilities is insufficiently explored. This paper examines the extent to which post-training can enhance LLMs' capacity for causal inference. We introduce CauGym, a comprehensive dataset comprising seven core causal tasks for training and five diverse test sets. Using this dataset, we systematically evaluate five post-training approaches: SFT, DPO, KTO, PPO, and GRPO. Across five in-domain and four existing benchmarks, our experiments demonstrate that appropriate post-training enables smaller LLMs to perform causal inference competitively, often surpassing much larger models. Our 14B parameter model achieves 93.5% accuracy on the CaLM benchmark, compared to 55.4% by OpenAI o3. Furthermore, the post-trained LLMs exhibit strong generalization and robustness under real-world conditions such as distribution shifts and noisy data. Collectively, these findings provide the first systematic evidence that targeted post-training can produce reliable and robust LLM-based causal reasoners. Our data and GRPO-model are available at https://github.com/OpenCausaLab/CauGym.