DFlash: Block Diffusion for Flash Speculative Decoding
作者: Jian Chen, Yesheng Liang, Zhijian Liu
分类: cs.CL
发布日期: 2026-02-05
💡 一句话要点
DFlash:提出基于块扩散的Flash推测解码框架,加速LLM推理。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 推测解码 扩散模型 并行生成 模型加速
📋 核心要点
- 现有推测解码方法依赖自回归草稿,仍存在顺序依赖,限制了加速效果。
- DFlash采用轻量级块扩散模型并行生成草稿token,提高草稿生成效率。
- 实验表明,DFlash在多种模型和任务上实现了显著加速,优于现有方法。
📝 摘要(中文)
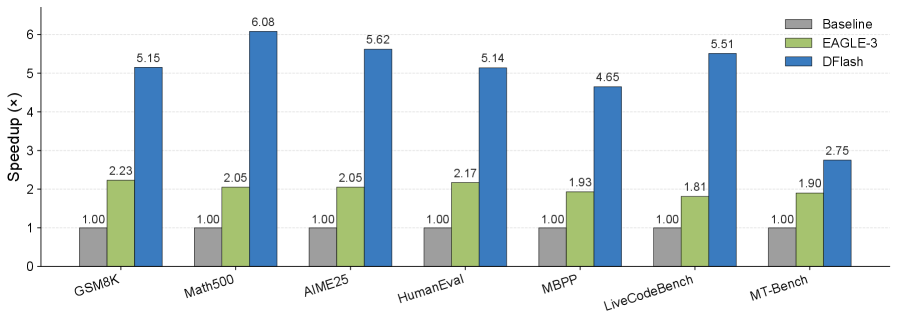
自回归大型语言模型(LLMs)性能强大,但其固有的顺序解码方式导致高推理延迟和GPU利用率低。推测解码通过使用快速草稿模型来缓解这一瓶颈,目标LLM并行验证其输出;然而,现有方法仍然依赖于自回归草稿,这仍然是顺序的,限制了实际加速。扩散LLM通过实现并行生成提供了一个有希望的替代方案,但目前的扩散模型通常不如自回归模型。在本文中,我们介绍DFlash,一个推测解码框架,它采用轻量级块扩散模型进行并行草稿。通过在单个前向传递中生成草稿token,并将草稿模型建立在从目标模型中提取的上下文特征上,DFlash能够以高质量的输出和更高的接受率实现高效的草稿。实验表明,DFlash在一系列模型和任务中实现了超过6倍的无损加速,比最先进的推测解码方法EAGLE-3高出2.5倍的加速。
🔬 方法详解
问题定义:现有的大型语言模型(LLMs)推理速度慢,特别是自回归模型,因为它们需要按顺序生成每个token。推测解码旨在通过使用一个较小的“草稿”模型来预测目标模型的输出,然后并行验证这些预测,从而加速推理。然而,现有的推测解码方法仍然依赖于自回归的草稿模型,这限制了它们可以实现的加速效果。
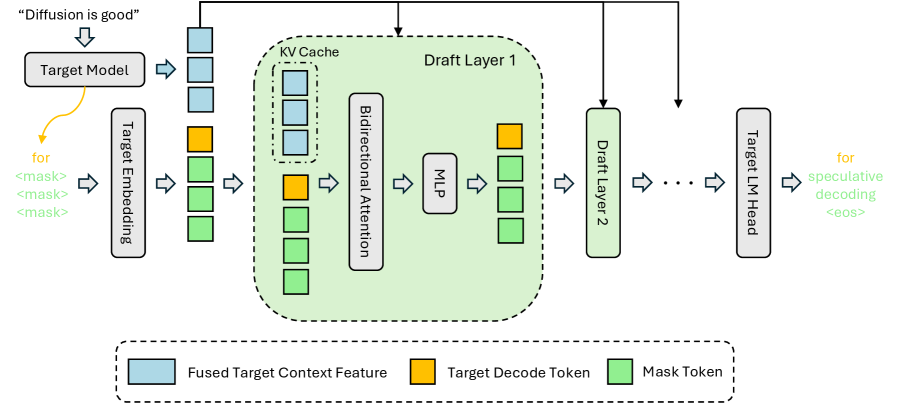
核心思路:DFlash的核心思想是利用扩散模型并行生成草稿token。扩散模型能够一次性生成多个token,从而避免了自回归模型的顺序依赖。此外,DFlash通过将草稿模型建立在从目标模型提取的上下文特征上,来提高草稿的质量和接受率。
技术框架:DFlash框架包含两个主要组件:目标LLM和一个轻量级的块扩散草稿模型。首先,目标LLM处理输入序列并提取上下文特征。然后,这些特征被输入到块扩散草稿模型中,该模型并行生成一个token块作为草稿。最后,目标LLM并行验证草稿token。被接受的token被添加到输出序列中,而未被接受的token被目标LLM的实际输出替换。
关键创新:DFlash的关键创新在于使用块扩散模型进行并行草稿生成。与传统的自回归草稿模型相比,扩散模型能够显著提高草稿生成的速度。此外,通过将草稿模型建立在目标模型的上下文特征上,DFlash能够生成更高质量的草稿,从而提高接受率并减少目标模型的计算量。
关键设计:DFlash中的块扩散模型采用轻量级架构,以确保快速生成草稿。具体来说,该模型使用Transformer块,并针对扩散过程进行了优化。损失函数包括一个扩散损失和一个重建损失,以确保生成的草稿既准确又与目标模型的输出一致。此外,DFlash还采用了一种自适应块大小策略,根据目标模型的置信度动态调整生成的token数量。
🖼️ 关键图片
📊 实验亮点
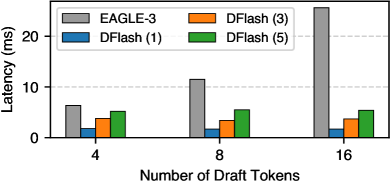
实验结果表明,DFlash在各种模型和任务上实现了显著的加速。例如,在Llama-2 7B模型上,DFlash实现了超过6倍的无损加速,并且比最先进的推测解码方法EAGLE-3高出2.5倍的加速。此外,DFlash在不同的模型大小和任务上都表现出良好的泛化能力。
🎯 应用场景
DFlash可应用于各种需要快速LLM推理的场景,例如实时对话系统、机器翻译、文本摘要和代码生成。通过显著提高推理速度,DFlash可以降低部署LLM的成本,并使其更易于在资源受限的环境中使用。未来,DFlash可以与其他加速技术相结合,进一步提高LLM的推理效率。
📄 摘要(原文)
Autoregressive large language models (LLMs) deliver strong performance but require inherently sequential decoding, leading to high inference latency and poor GPU utilization. Speculative decoding mitigates this bottleneck by using a fast draft model whose outputs are verified in parallel by the target LLM; however, existing methods still rely on autoregressive drafting, which remains sequential and limits practical speedups. Diffusion LLMs offer a promising alternative by enabling parallel generation, but current diffusion models typically underperform compared with autoregressive models. In this paper, we introduce DFlash, a speculative decoding framework that employs a lightweight block diffusion model for parallel drafting. By generating draft tokens in a single forward pass and conditioning the draft model on context features extracted from the target model, DFlash enables efficient drafting with high-quality outputs and higher acceptance rates. Experiments show that DFlash achieves over 6x lossless acceleration across a range of models and tasks, delivering up to 2.5x higher speedup than the state-of-the-art speculative decoding method EAGLE-3.