Multi-Token Prediction via Self-Distillation
作者: John Kirchenbauer, Abhimanyu Hans, Brian Bartoldson, Micah Goldblum, Ashwinee Panda, Tom Goldstein
分类: cs.CL, cs.LG
发布日期: 2026-02-05
备注: 8 pages and 5 figures in the main body
💡 一句话要点
提出基于自蒸馏的多Token预测方法,加速语言模型推理。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 语言模型 推理加速 自蒸馏 多Token预测 在线学习
📋 核心要点
- 现有加速语言模型推理的技术,如推测解码,需要训练辅助推测模型,并构建和部署复杂的推理流程。
- 本文提出一种基于自蒸馏的策略,将单Token预测模型转化为多Token预测模型,无需额外的辅助模型或特殊推理代码。
- 实验表明,在GSM8K数据集上,该方法在精度损失小于5%的情况下,解码速度平均提升超过3倍。
📝 摘要(中文)
本文提出了一种新的方法,通过简单的在线蒸馏目标,将预训练的自回归语言模型从慢速的单Token预测模型转换为快速的独立多Token预测模型,从而加速语言模型推理。最终模型保留了与预训练初始检查点完全相同的实现,无需添加任何辅助验证器或其他专用推理代码即可部署。在GSM8K数据集上,该方法生成的模型平均解码速度提高了3倍以上,而相对于单Token解码性能,准确率下降小于5%。
🔬 方法详解
问题定义:现有加速语言模型推理的方法,例如推测解码,通常需要额外的模型(推测模型)和复杂的推理流程。这增加了部署和维护的复杂性,并且可能引入额外的延迟。本文旨在解决如何在不引入额外模型和复杂流程的情况下,加速自回归语言模型的推理速度。
核心思路:本文的核心思路是利用自蒸馏技术,让模型自身学习预测多个Token,从而将原本的单Token预测模型转化为多Token预测模型。通过在线蒸馏,模型在训练过程中同时学习预测下一个Token和多个Token,从而提高推理速度。
技术框架:该方法使用在线蒸馏框架。具体而言,模型在训练时,既要预测下一个Token(标准自回归训练),也要预测多个Token。预测多个Token的目标是通过蒸馏损失来实现的,即让多Token预测的结果尽可能接近单Token预测的结果。这样,模型就可以在推理时直接预测多个Token,而无需额外的辅助模型。
关键创新:该方法最关键的创新在于它能够将单Token预测模型转化为多Token预测模型,而无需任何额外的辅助模型或复杂的推理流程。这使得该方法易于部署和维护,并且可以有效地提高推理速度。此外,自蒸馏的方式避免了对额外数据的需求。
关键设计:关键的设计包括:1) 使用在线蒸馏,允许模型在训练过程中同时学习单Token和多Token预测;2) 设计合适的蒸馏损失函数,使得多Token预测的结果尽可能接近单Token预测的结果;3) 探索不同的多Token预测策略,例如固定长度预测和可变长度预测;4) 仔细调整训练参数,以平衡精度和速度之间的权衡。
🖼️ 关键图片
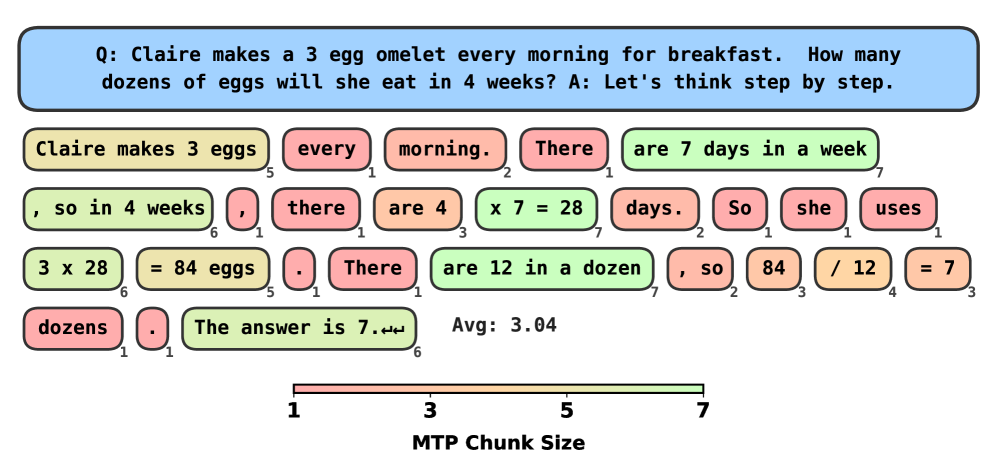


📊 实验亮点
实验结果表明,在GSM8K数据集上,该方法生成的模型在精度损失小于5%的情况下,解码速度平均提升超过3倍。这意味着在保持模型性能基本不变的情况下,推理速度得到了显著提升。该方法在加速效果和模型复杂度之间取得了良好的平衡。
🎯 应用场景
该研究成果可广泛应用于各种需要加速语言模型推理的场景,例如对话系统、机器翻译、文本生成等。通过提高推理速度,可以降低延迟,提升用户体验,并降低计算成本。该方法尤其适用于资源受限的设备,例如移动设备和嵌入式系统,因为其无需额外的辅助模型。
📄 摘要(原文)
Existing techniques for accelerating language model inference, such as speculative decoding, require training auxiliary speculator models and building and deploying complex inference pipelines. We consider a new approach for converting a pretrained autoregressive language model from a slow single next token prediction model into a fast standalone multi-token prediction model using a simple online distillation objective. The final model retains the exact same implementation as the pretrained initial checkpoint and is deployable without the addition of any auxiliary verifier or other specialized inference code. On GSM8K, our method produces models that can decode more than $3\times$ faster on average at $<5\%$ drop in accuracy relative to single token decoding performance.