A Systematic Evaluation of Large Language Models for PTSD Severity Estimation: The Role of Contextual Knowledge and Modeling Strategies
作者: Panagiotis Kaliosis, Adithya V Ganesan, Oscar N. E. Kjell, Whitney Ringwald, Scott Feltman, Melissa A. Carr, Dimitris Samaras, Camilo Ruggero, Benjamin J. Luft, Roman Kotov, Andrew H. Schwartz
分类: cs.CL
发布日期: 2026-02-05
备注: 18 pages, 3 figures, 5 tables
💡 一句话要点
系统评估大型语言模型在创伤后应激障碍严重程度评估中的作用,着重上下文知识和建模策略的影响。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 创伤后应激障碍 精神健康评估 上下文知识 建模策略
📋 核心要点
- 现有方法在利用大型语言模型评估精神健康状况时,对影响其准确性的因素了解有限,缺乏系统性评估。
- 本研究通过系统地改变上下文知识和建模策略,探究这些因素对LLM评估PTSD严重程度的影响,旨在提升评估准确性。
- 实验结果表明,提供详细的结构定义和叙述背景、增加推理努力以及集成监督模型与零样本LLM可以显著提高评估准确性。
📝 摘要(中文)
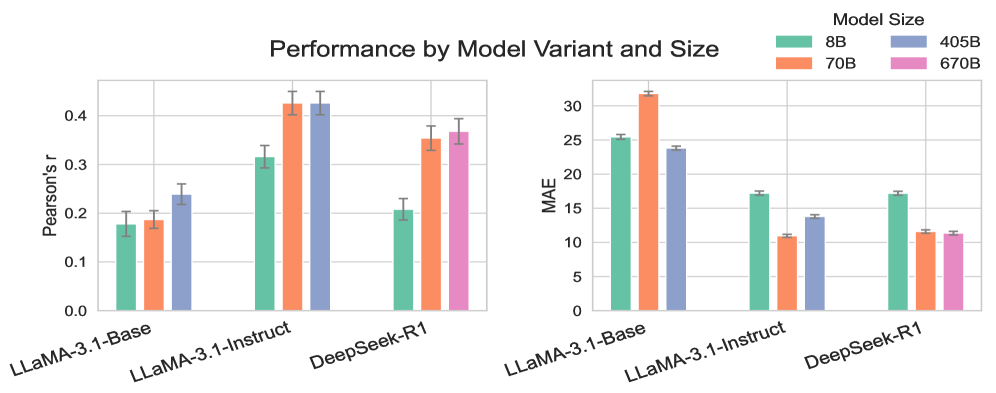
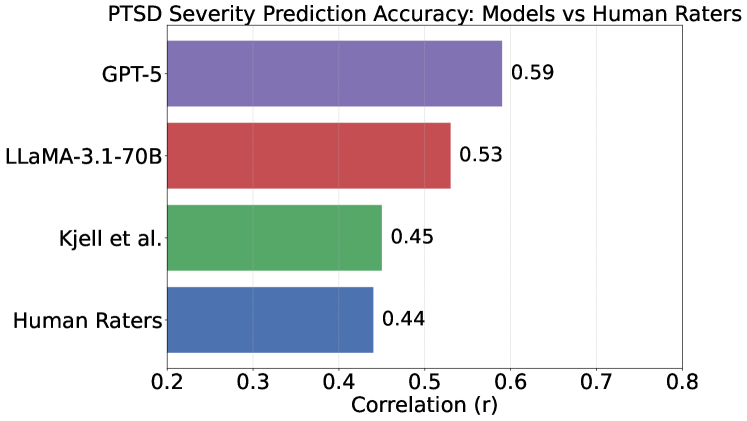
本研究利用来自1437人的自然语言叙述和自述PTSD严重程度评分的临床数据集,全面评估了11个最先进的LLM的性能,旨在探究影响LLM评估精神健康状况准确性的因素。通过系统地改变(i)上下文知识,如子量表定义、分布摘要和访谈问题,以及(ii)建模策略,包括零样本与少样本学习、推理努力程度、模型大小、结构化子量表与直接标量预测、输出重缩放和九种集成方法,研究发现:(a)当提供详细的结构定义和叙述背景时,LLM最为准确;(b)增加推理努力可以提高估计准确性;(c)开源模型(Llama、Deepseek)的性能在超过70B参数后趋于稳定,而闭源模型(o3-mini、gpt-5)的性能随着新一代模型而提高;(d)将监督模型与零样本LLM集成可以获得最佳性能。总而言之,结果表明,上下文知识和建模策略的选择对于部署LLM以准确评估精神健康至关重要。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)在评估创伤后应激障碍(PTSD)严重程度时的准确性问题。现有方法缺乏对影响LLM性能的关键因素的系统性评估,例如上下文知识和建模策略的选择,导致评估结果不稳定且难以解释。
核心思路:论文的核心思路是通过系统地控制和改变上下文知识(如子量表定义、分布摘要、访谈问题)和建模策略(如零样本/少样本学习、推理努力程度、模型大小、输出重缩放等),来研究这些因素对LLM评估PTSD严重程度的影响。通过这种方式,可以识别出哪些因素对LLM的准确性至关重要,并为实际部署提供指导。
技术框架:研究采用了一个包含1437名个体自然语言叙述和自述PTSD严重程度评分的临床数据集。研究流程包括:1) 选择11个最先进的LLM(包括开源和闭源模型);2) 系统地改变上下文知识和建模策略;3) 使用不同的LLM进行PTSD严重程度评估;4) 分析评估结果,确定影响LLM准确性的关键因素;5) 尝试不同的集成方法,以进一步提高评估性能。
关键创新:论文的关键创新在于对影响LLM在PTSD严重程度评估中性能的因素进行了系统性的评估。以往研究通常只关注单一因素或采用较小的模型,而本研究则综合考虑了上下文知识、建模策略、模型大小等多个因素,并使用了大规模的临床数据集和多种LLM。此外,论文还探索了集成监督模型和零样本LLM的方法,进一步提高了评估性能。
关键设计:在上下文知识方面,研究者尝试了提供不同的信息,如子量表定义、分布摘要和访谈问题,以观察这些信息对LLM评估结果的影响。在建模策略方面,研究者比较了零样本和少样本学习、不同的推理努力程度、不同大小的模型以及不同的输出重缩放方法。此外,研究者还尝试了九种不同的集成方法,包括简单的平均和加权平均等。
🖼️ 关键图片

📊 实验亮点
实验结果表明,提供详细的结构定义和叙述背景可以显著提高LLM的评估准确性。增加推理努力也能提升性能。开源模型在超过70B参数后性能趋于稳定,而闭源模型随着新一代模型而提高。最佳性能是通过集成监督模型与零样本LLM实现的,这表明结合不同方法的优势可以进一步提高评估准确性。
🎯 应用场景
该研究成果可应用于心理健康领域,辅助临床医生进行PTSD的诊断和严重程度评估。通过优化LLM的上下文知识和建模策略,可以提高评估的准确性和效率,从而为患者提供更及时和有效的治疗。此外,该研究也为其他精神健康状况的LLM评估提供了借鉴。
📄 摘要(原文)
Large language models (LLMs) are increasingly being used in a zero-shot fashion to assess mental health conditions, yet we have limited knowledge on what factors affect their accuracy. In this study, we utilize a clinical dataset of natural language narratives and self-reported PTSD severity scores from 1,437 individuals to comprehensively evaluate the performance of 11 state-of-the-art LLMs. To understand the factors affecting accuracy, we systematically varied (i) contextual knowledge like subscale definitions, distribution summary, and interview questions, and (ii) modeling strategies including zero-shot vs few shot, amount of reasoning effort, model sizes, structured subscales vs direct scalar prediction, output rescaling and nine ensemble methods. Our findings indicate that (a) LLMs are most accurate when provided with detailed construct definitions and context of the narrative; (b) increased reasoning effort leads to better estimation accuracy; (c) performance of open-weight models (Llama, Deepseek), plateau beyond 70B parameters while closed-weight (o3-mini, gpt-5) models improve with newer generations; and (d) best performance is achieved when ensembling a supervised model with the zero-shot LLMs. Taken together, the results suggest choice of contextual knowledge and modeling strategies is important for deploying LLMs to accurately assess mental health.