DSB: Dynamic Sliding Block Scheduling for Diffusion LLMs
作者: Lizhuo Luo, Shenggui Li, Yonggang Wen, Tianwei Zhang
分类: cs.CL
发布日期: 2026-02-05
🔗 代码/项目: GITHUB
💡 一句话要点
提出动态滑动块调度(DSB)方法,提升Diffusion LLM的生成质量和效率。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: Diffusion LLM 动态调度 块推理 文本生成 KV-cache 并行解码 语义难度
📋 核心要点
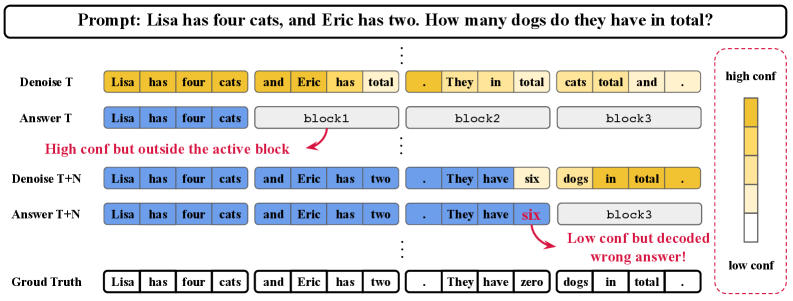
- 现有固定块大小的调度方法在Diffusion LLM中存在对语义难度不敏感的问题,导致生成质量和效率下降。
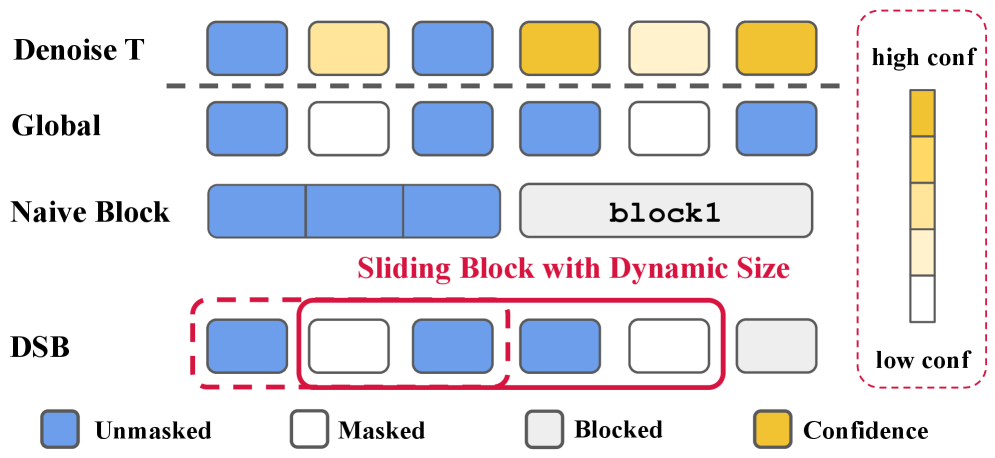
- 提出动态滑动块(DSB)调度方法,通过动态调整块大小来适应语义难度,无需额外训练。
- 实验结果表明,DSB及其缓存机制DSB Cache能显著提升Diffusion LLM的生成质量和推理效率。
📝 摘要(中文)
扩散大语言模型(dLLMs)作为文本生成的一种有前景的替代方案正在兴起,其特点是原生支持并行解码。在实践中,块推理对于避免全局双向解码中的顺序错位和提高输出质量至关重要。然而,广泛使用的固定、预定义的块(朴素)调度对语义难度不敏感,使其成为质量和效率的次优策略:它可能迫使对不确定的位置过早提交,同时延迟块边界附近容易确定的位置。在这项工作中,我们分析了朴素块调度的局限性,并揭示了动态调整调度以适应语义难度对于可靠和高效推理的重要性。受此启发,我们提出了一种动态滑动块(DSB)方法,这是一种无需训练的块调度方法,它使用具有动态大小的滑动块来克服朴素块的刚性。为了进一步提高效率,我们引入了DSB Cache,这是一种为DSB量身定制的无需训练的KV-cache机制。跨多个模型和基准的广泛实验表明,DSB与DSB Cache相结合,始终如一地提高了dLLM的生成质量和推理效率。
🔬 方法详解
问题定义:现有的Diffusion LLM在进行块推理时,通常采用固定大小的块调度策略。这种策略忽略了文本中不同位置的语义难度差异,导致在容易确定的位置上延迟决策,而在难以确定的位置上过早提交,从而影响生成质量和效率。现有方法的痛点在于无法根据文本内容动态调整块的大小,导致次优的推理性能。
核心思路:论文的核心思路是根据文本的语义难度动态调整块的大小。具体来说,对于容易确定的位置,可以采用较大的块,快速生成;对于难以确定的位置,则采用较小的块,进行更精细的推理。通过这种动态调整,可以避免过早提交错误决策,并加速整体生成过程。
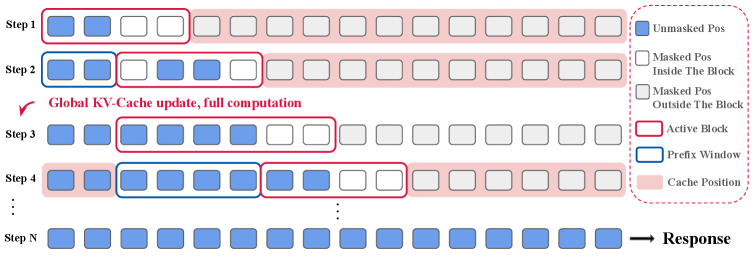
技术框架:DSB方法的核心是一个滑动块,其大小可以根据文本的语义难度动态调整。整体流程如下:1. 初始化滑动块的位置和大小。2. 在当前滑动块内进行推理。3. 根据推理结果,评估当前滑动块的语义难度。4. 根据语义难度,动态调整滑动块的大小。5. 将滑动块移动到下一个位置,重复步骤2-4,直到生成完整的文本。为了进一步提高效率,论文还提出了DSB Cache,用于缓存中间计算结果,避免重复计算。
关键创新:最重要的技术创新点在于动态调整块大小的策略。与传统的固定块大小方法相比,DSB能够更好地适应文本的语义难度,从而提高生成质量和效率。此外,DSB Cache也是一个重要的创新点,它通过缓存中间计算结果,进一步加速了推理过程。
关键设计:论文中没有明确说明具体的参数设置、损失函数或网络结构等技术细节。但是,动态调整块大小的策略是关键设计。具体如何评估语义难度,以及如何根据语义难度调整块大小,是DSB方法的核心。
🖼️ 关键图片
📊 实验亮点
实验结果表明,DSB方法在多个模型和基准测试中均取得了显著的性能提升。与传统的固定块大小方法相比,DSB能够提高生成质量,并加速推理过程。具体的数据提升幅度未知,但论文强调了DSB的一致性改进。
🎯 应用场景
该研究成果可应用于各种需要文本生成的场景,例如机器翻译、文本摘要、对话生成等。通过提高生成质量和效率,DSB方法可以提升用户体验,并降低计算成本。未来,该方法有望在自然语言处理领域得到广泛应用,并推动相关技术的发展。
📄 摘要(原文)
Diffusion large language models (dLLMs) have emerged as a promising alternative for text generation, distinguished by their native support for parallel decoding. In practice, block inference is crucial for avoiding order misalignment in global bidirectional decoding and improving output quality. However, the widely-used fixed, predefined block (naive) schedule is agnostic to semantic difficulty, making it a suboptimal strategy for both quality and efficiency: it can force premature commitments to uncertain positions while delaying easy positions near block boundaries. In this work, we analyze the limitations of naive block scheduling and disclose the importance of dynamically adapting the schedule to semantic difficulty for reliable and efficient inference. Motivated by this, we propose Dynamic Sliding Block (DSB), a training-free block scheduling method that uses a sliding block with a dynamic size to overcome the rigidity of the naive block. To further improve efficiency, we introduce DSB Cache, a training-free KV-cache mechanism tailored to DSB. Extensive experiments across multiple models and benchmarks demonstrate that DSB, together with DSB Cache, consistently improves both generation quality and inference efficiency for dLLMs. Code is released at https://github.com/lizhuo-luo/DSB.