KV-CoRE: Benchmarking Data-Dependent Low-Rank Compressibility of KV-Caches in LLMs
作者: Jian Chen, Zhuoran Wang, Jiayu Qin, Ming Li, Meng Wang, Changyou Chen, Yin Chen, Qizhen Weng, Yirui Liu
分类: cs.CL
发布日期: 2026-02-05
💡 一句话要点
KV-CoRE:一种评估LLM中KV-Cache数据依赖性低秩可压缩性的基准方法
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: KV-cache压缩 低秩近似 奇异值分解 大型语言模型 数据依赖性 模型优化 性能评估
📋 核心要点
- 现有KV-cache压缩方法忽略了KV-cache的数据依赖性及其在不同层间的差异。
- 提出KV-CoRE,一种基于SVD的无梯度、增量式方法,用于量化KV-cache的低秩可压缩性。
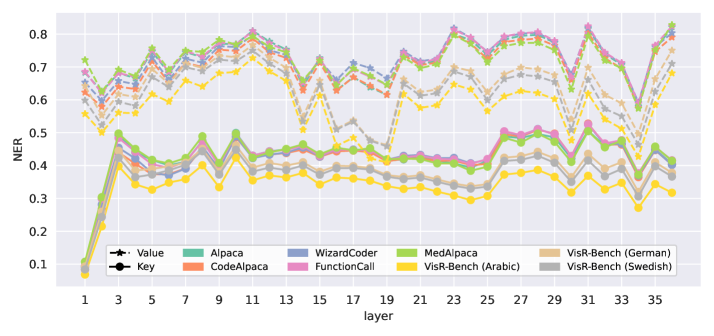
- 通过大规模实验,揭示了可压缩性与模型架构、训练数据和语言覆盖范围之间的关系,并验证了归一化有效秩与性能下降的相关性。
📝 摘要(中文)
大型语言模型在自回归解码过程中依赖KV-cache来避免冗余计算,但随着上下文长度的增长,读写缓存会迅速饱和GPU内存带宽。目前的研究主要集中在KV-cache压缩,但大多数方法忽略了KV-cache的数据依赖性以及其在不同层之间的变化。本文提出KV-CoRE(基于秩评估的KV-cache可压缩性),这是一种基于SVD的方法,用于量化KV-cache的数据依赖性低秩可压缩性。KV-CoRE计算Frobenius范数下的最优低秩近似,并且由于其无梯度和增量的特性,能够实现高效的数据集级别、层级别的评估。通过这种方法,我们分析了跨越五个英语领域和十六种语言的多个模型和数据集,揭示了将可压缩性与模型架构、训练数据和语言覆盖范围联系起来的系统模式。作为分析的一部分,我们采用归一化有效秩作为可压缩性的度量标准,并表明它与压缩下的性能下降密切相关。我们的研究建立了一个原则性的评估框架,以及LLM中kv-cache可压缩性的第一个大规模基准,为动态的、数据感知的压缩和以数据为中心的模型开发提供了见解。
🔬 方法详解
问题定义:论文旨在解决大型语言模型中KV-cache的压缩问题。现有的KV-cache压缩方法通常忽略了KV-cache本身的数据依赖性,以及这种数据依赖性在不同模型层之间的变化。这种忽略导致了压缩策略的次优,无法充分利用KV-cache的潜在可压缩性,从而限制了模型性能的提升。
核心思路:论文的核心思路是利用奇异值分解(SVD)来分析KV-cache的低秩结构,从而量化其数据依赖性的可压缩性。通过计算KV-cache在Frobenius范数下的最优低秩近似,可以评估不同层、不同数据集下KV-cache的潜在压缩率。这种方法能够捕捉KV-cache中蕴含的结构信息,为后续的动态压缩策略提供指导。
技术框架:KV-CoRE的整体框架包括以下几个主要步骤:1) 收集不同模型和数据集的KV-cache数据;2) 对每个KV-cache矩阵进行奇异值分解(SVD);3) 计算不同秩下的低秩近似,并评估其与原始矩阵的Frobenius范数误差;4) 使用归一化有效秩作为可压缩性的度量标准;5) 分析可压缩性与模型架构、训练数据和语言覆盖范围之间的关系。该框架是增量的,可以逐层进行评估,且无需梯度计算。
关键创新:论文的关键创新在于提出了KV-CoRE,一种基于SVD的、数据驱动的KV-cache可压缩性评估方法。与现有方法相比,KV-CoRE能够显式地量化KV-cache的数据依赖性,并揭示其在不同层和数据集上的变化。此外,KV-CoRE是无梯度的,计算效率高,适用于大规模的KV-cache分析。
关键设计:KV-CoRE的关键设计包括:1) 使用奇异值分解(SVD)来提取KV-cache的低秩结构;2) 采用Frobenius范数作为低秩近似的误差度量;3) 使用归一化有效秩作为可压缩性的指标,该指标能够反映压缩后的性能下降程度。论文没有涉及具体的网络结构或损失函数的设计,而是侧重于对现有模型的KV-cache进行分析和评估。
🖼️ 关键图片


📊 实验亮点
实验结果表明,KV-cache的可压缩性与模型架构、训练数据和语言覆盖范围密切相关。研究发现,归一化有效秩与压缩后的性能下降具有很强的相关性,这为选择合适的压缩策略提供了依据。该研究构建了首个大规模的KV-cache可压缩性基准,为后续研究提供了参考。
🎯 应用场景
该研究成果可应用于大型语言模型的部署和优化,尤其是在资源受限的环境下。通过动态地调整KV-cache的压缩率,可以在保证模型性能的同时,显著降低内存占用和计算成本。此外,该研究还可以指导数据中心模型开发,帮助设计更易于压缩的模型架构和训练策略。
📄 摘要(原文)
Large language models rely on kv-caches to avoid redundant computation during autoregressive decoding, but as context length grows, reading and writing the cache can quickly saturate GPU memory bandwidth. Recent work has explored KV-cache compression, yet most approaches neglect the data-dependent nature of kv-caches and their variation across layers. We introduce KV-CoRE KV-cache Compressibility by Rank Evaluation), an SVD-based method for quantifying the data-dependent low-rank compressibility of kv-caches. KV-CoRE computes the optimal low-rank approximation under the Frobenius norm and, being gradient-free and incremental, enables efficient dataset-level, layer-wise evaluation. Using this method, we analyze multiple models and datasets spanning five English domains and sixteen languages, uncovering systematic patterns that link compressibility to model architecture, training data, and language coverage. As part of this analysis, we employ the Normalized Effective Rank as a metric of compressibility and show that it correlates strongly with performance degradation under compression. Our study establishes a principled evaluation framework and the first large-scale benchmark of kv-cache compressibility in LLMs, offering insights for dynamic, data-aware compression and data-centric model development.