Stop Rewarding Hallucinated Steps: Faithfulness-Aware Step-Level Reinforcement Learning for Small Reasoning Models
作者: Shuo Nie, Hexuan Deng, Chao Wang, Ruiyu Fang, Xuebo Liu, Shuangyong Song, Yu Li, Min Zhang, Xuelong Li
分类: cs.CL
发布日期: 2026-02-05
🔗 代码/项目: GITHUB
💡 一句话要点
提出FaithRL,解决小模型推理中中间步骤的幻觉问题,提升推理可靠性
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 小型推理模型 思维链 幻觉 强化学习 真实性 步骤级监督 开放域问答
📋 核心要点
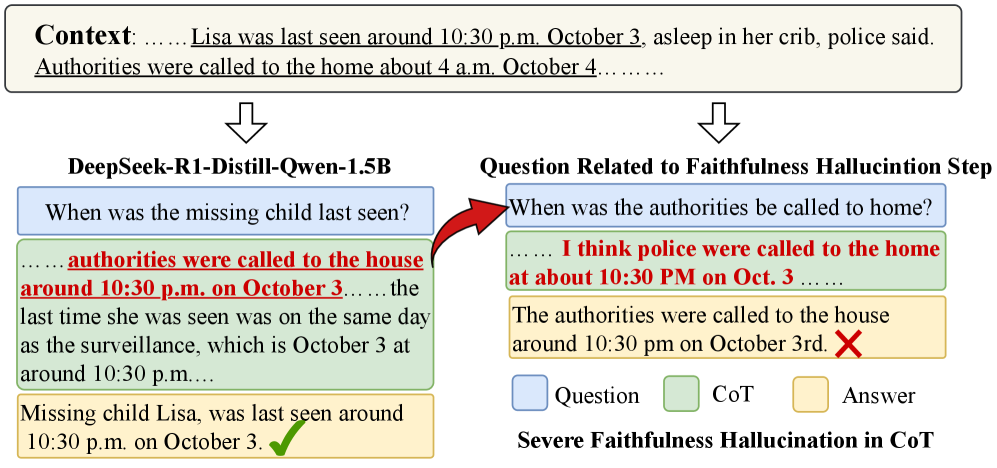
- 小型推理模型在资源受限场景下进行CoT推理至关重要,但中间推理步骤易出现幻觉。
- FaithRL通过过程奖励模型提供步骤级真实性奖励,并使用截断重采样生成对比信号。
- 实验表明FaithRL能有效减少CoT和最终答案中的幻觉,提升推理的真实性和可靠性。
📝 摘要(中文)
随着大型语言模型变得更小更高效,小型推理模型(SRM)对于在资源受限的环境中实现思维链(CoT)推理至关重要。然而,SRM容易产生幻觉,尤其是在中间推理步骤中。现有的基于在线强化学习的缓解方法依赖于基于结果的奖励或粗粒度的CoT评估,这可能会在最终答案正确时无意中强化不真实的推理。为了解决这些局限性,我们提出了Faithfulness-Aware Step-Level Reinforcement Learning (FaithRL),通过来自过程奖励模型的显式真实性奖励引入步骤级监督,以及一种隐式的截断重采样策略,该策略从真实的prefix生成对比信号。在多个SRM和开放域问答基准上的实验表明,FaithRL始终减少CoT和最终答案中的幻觉,从而实现更真实和可靠的推理。
🔬 方法详解
问题定义:论文旨在解决小型推理模型(SRM)在思维链(CoT)推理过程中,中间步骤容易产生幻觉的问题。现有方法,如基于结果的强化学习,仅关注最终答案的正确性,忽略了中间推理步骤的真实性,可能导致模型学习到不真实的推理路径。这种“奖励幻觉步骤”的现象降低了推理过程的可信度。
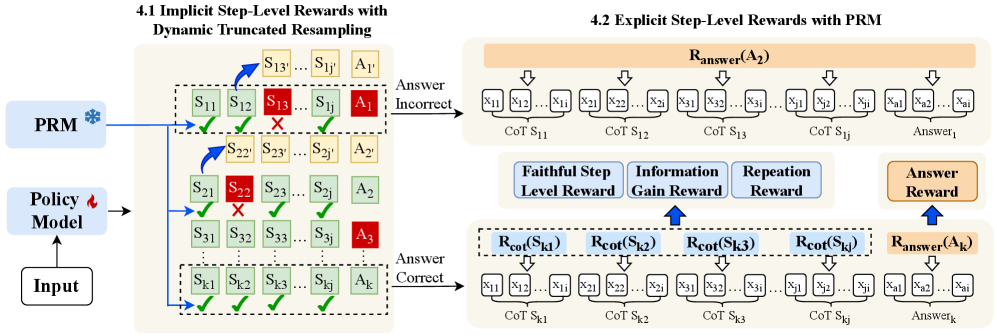
核心思路:FaithRL的核心思路是通过引入步骤级别的真实性监督,显式地奖励真实的推理步骤,惩罚不真实的推理步骤。同时,利用截断重采样策略,从真实的前缀生成对比信号,进一步增强模型对真实推理的辨别能力。通过这种方式,FaithRL能够引导模型学习更可信的推理路径,减少幻觉的产生。
技术框架:FaithRL的整体框架包括以下几个主要模块:1) 小型推理模型(SRM):作为推理的主体,负责生成CoT推理过程。2) 过程奖励模型:用于评估每个推理步骤的真实性,并给出相应的奖励。3) 强化学习模块:利用过程奖励和对比信号,更新SRM的策略,使其更倾向于生成真实的推理步骤。4) 截断重采样模块:从真实的推理前缀中采样,生成对比样本,用于增强模型的辨别能力。
关键创新:FaithRL最重要的技术创新在于引入了步骤级别的真实性监督。与现有方法仅关注最终结果不同,FaithRL能够对每个推理步骤进行评估,并根据其真实性给出相应的奖励。这种细粒度的监督能够更有效地引导模型学习真实的推理路径,减少幻觉的产生。此外,截断重采样策略也是一个创新点,它能够从真实的前缀中生成对比样本,进一步增强模型的辨别能力。
关键设计:FaithRL的关键设计包括:1) 过程奖励模型的选择:需要选择一个能够准确评估推理步骤真实性的模型。论文中使用了预训练的语言模型作为过程奖励模型。2) 奖励函数的设置:需要合理设置奖励函数,以平衡最终结果的正确性和中间步骤的真实性。3) 截断重采样的策略:需要选择合适的截断点和采样方法,以生成有效的对比样本。4) 强化学习算法的选择:可以使用常见的强化学习算法,如PPO或Actor-Critic,来更新SRM的策略。
🖼️ 关键图片

📊 实验亮点
实验结果表明,FaithRL在多个小型推理模型和开放域问答基准上都取得了显著的性能提升。例如,在某些基准测试中,FaithRL能够将CoT推理过程中的幻觉率降低10%以上,同时提高最终答案的准确率。与现有的基于结果的强化学习方法相比,FaithRL能够更有效地减少幻觉,并生成更可信的推理过程。
🎯 应用场景
FaithRL可应用于各种需要可信推理的场景,如开放域问答、医疗诊断、金融分析等。通过减少推理过程中的幻觉,提高推理结果的可靠性,有助于提升决策质量,降低风险。未来,该方法可扩展到更复杂的推理任务和更广泛的应用领域,例如机器人导航、智能客服等。
📄 摘要(原文)
As large language models become smaller and more efficient, small reasoning models (SRMs) are crucial for enabling chain-of-thought (CoT) reasoning in resource-constrained settings. However, they are prone to faithfulness hallucinations, especially in intermediate reasoning steps. Existing mitigation methods based on online reinforcement learning rely on outcome-based rewards or coarse-grained CoT evaluation, which can inadvertently reinforce unfaithful reasoning when the final answer is correct. To address these limitations, we propose Faithfulness-Aware Step-Level Reinforcement Learning (FaithRL), introducing step-level supervision via explicit faithfulness rewards from a process reward model, together with an implicit truncated resampling strategy that generates contrastive signals from faithful prefixes. Experiments across multiple SRMs and Open-Book QA benchmarks demonstrate that FaithRL consistently reduces hallucinations in both the CoT and final answers, leading to more faithful and reliable reasoning. Code is available at https://github.com/Easy195/FaithRL.