EuroLLM-22B: Technical Report
作者: Miguel Moura Ramos, Duarte M. Alves, Hippolyte Gisserot-Boukhlef, João Alves, Pedro Henrique Martins, Patrick Fernandes, José Pombal, Nuno M. Guerreiro, Ricardo Rei, Nicolas Boizard, Amin Farajian, Mateusz Klimaszewski, José G. C. de Souza, Barry Haddow, François Yvon, Pierre Colombo, Alexandra Birch, André F. T. Martins
分类: cs.CL, cs.AI, cs.LG
发布日期: 2026-02-05
💡 一句话要点
EuroLLM-22B:为欧洲公民需求从头训练的多语言大语言模型
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 多语言模型 欧洲语言 自然语言处理 指令调优
📋 核心要点
- 现有开放大语言模型对欧洲语言的支持不足,导致欧洲公民的需求未被充分满足,这是核心问题。
- EuroLLM-22B通过从头训练一个覆盖多种欧洲语言的大型语言模型来解决这一问题,旨在提升模型在欧洲语言上的性能。
- EuroLLM-22B在多语言基准测试中表现出强大的推理、指令遵循和翻译能力,性能与同等规模的模型相当。
📝 摘要(中文)
本报告介绍了EuroLLM-22B,一个从头开始训练的大型语言模型,旨在满足欧洲公民的需求,覆盖所有24种欧盟官方语言以及11种其他语言。 EuroLLM旨在解决现有开放大型语言模型中欧洲语言代表性不足和服务不足的问题。 我们全面概述了EuroLLM-22B的开发过程,包括分词器设计、架构规范、数据过滤和训练程序。 在广泛的多语言基准测试中,EuroLLM-22B在推理、指令遵循和翻译方面表现出强大的性能,达到了与同等规模模型相媲美的结果。 为了支持未来的研究,我们发布了我们的基础模型和指令调优模型、我们的多语言网络预训练数据和更新的EuroBlocks指令数据集,以及我们的预训练和评估代码库。
🔬 方法详解
问题定义:现有的大型语言模型在欧洲语言上的表现不佳,无法很好地服务于欧洲公民的需求。主要痛点在于欧洲语言的数据量不足,导致模型在这些语言上的能力较弱。
核心思路:EuroLLM-22B的核心思路是从头开始训练一个专门针对欧洲语言的大型语言模型,通过收集和清洗大量欧洲语言数据,提升模型在这些语言上的性能。这样可以避免依赖现有模型,从而更好地控制模型的语言能力。
技术框架:EuroLLM-22B的整体框架包括数据收集与过滤、分词器设计、模型架构选择、预训练和指令调优等阶段。首先,收集涵盖24种欧盟官方语言和11种其他语言的大量文本数据,并进行过滤和清洗。然后,设计一个能够有效处理多种欧洲语言的分词器。接下来,选择合适的模型架构进行预训练,并在预训练的基础上进行指令调优,以提升模型在特定任务上的性能。
关键创新:EuroLLM-22B的关键创新在于其专注于欧洲语言,并从头开始训练模型。这与以往依赖现有模型进行微调的方法不同,能够更好地控制模型的语言能力,并针对欧洲语言进行优化。此外,该项目还发布了多语言网络预训练数据和指令数据集,为后续研究提供了宝贵的资源。
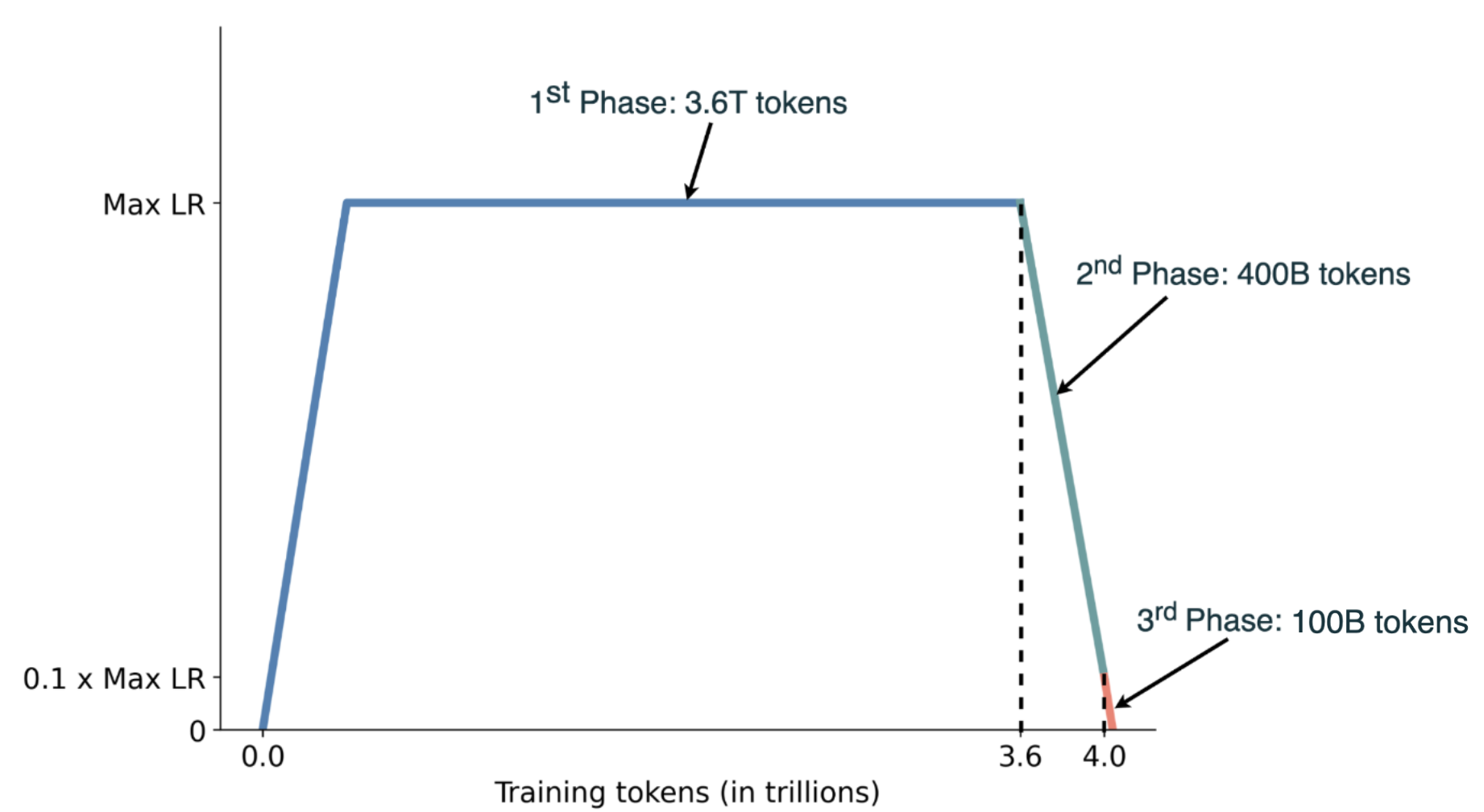
关键设计:论文中提到了分词器设计、架构规范、数据过滤和训练程序,但具体的技术细节没有详细展开。例如,分词器可能采用了某种子词算法来处理多种欧洲语言的形态变化。模型架构的具体选择(例如Transformer的具体配置)以及训练过程中的超参数设置(例如学习率、batch size等)也未在报告中详细说明。损失函数未知。
🖼️ 关键图片
📊 实验亮点
EuroLLM-22B在多语言基准测试中表现出强大的性能,在推理、指令遵循和翻译方面达到了与同等规模模型相媲美的结果。具体性能数据未知,但报告强调了其在多语言任务上的竞争力。该模型及其相关资源(数据、代码)的发布,为后续研究提供了重要的基础。
🎯 应用场景
EuroLLM-22B可应用于多语言机器翻译、跨语言信息检索、多语言内容生成等领域。它能够更好地服务于欧洲公民,促进欧洲不同语言文化之间的交流与合作。未来,该模型可以进一步扩展到更多欧洲语言,并应用于教育、医疗等领域。
📄 摘要(原文)
This report presents EuroLLM-22B, a large language model trained from scratch to support the needs of European citizens by covering all 24 official European Union languages and 11 additional languages. EuroLLM addresses the issue of European languages being underrepresented and underserved in existing open large language models. We provide a comprehensive overview of EuroLLM-22B's development, including tokenizer design, architectural specifications, data filtering, and training procedures. Across a broad set of multilingual benchmarks, EuroLLM-22B demonstrates strong performance in reasoning, instruction following, and translation, achieving results competitive with models of comparable size. To support future research, we release our base and instruction-tuned models, our multilingual web pretraining data and updated EuroBlocks instruction datasets, as well as our pre-training and evaluation codebases.