RRAttention: Dynamic Block Sparse Attention via Per-Head Round-Robin Shifts for Long-Context Inference
作者: Siran Liu, Guoxia Wang, Sa Wang, Jinle Zeng, HaoYang Xie, Siyu Lou, JiaBin Yang, DianHai Yu, Haifeng Wang, Chao Yang
分类: cs.CL
发布日期: 2026-02-05
💡 一句话要点
RRAttention:通过轮询移位实现动态块稀疏注意力,加速长文本推理。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 长文本处理 稀疏注意力 动态注意力 轮询采样 语言模型
📋 核心要点
- 现有动态稀疏注意力方法在效率和性能间存在权衡,如预处理需求、缺乏全局评估或违反查询独立性。
- RRAttention通过头部轮询采样策略,在保持查询独立性的同时,实现高效的全局模式发现和步幅级别聚合。
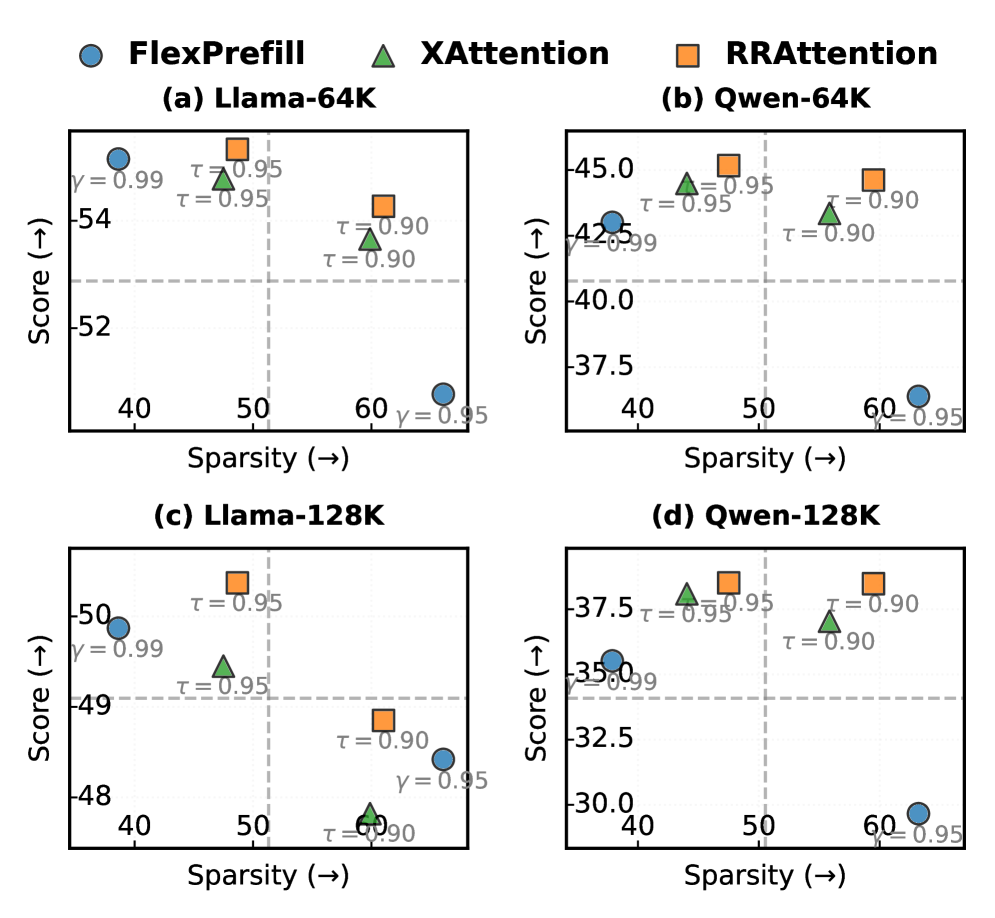
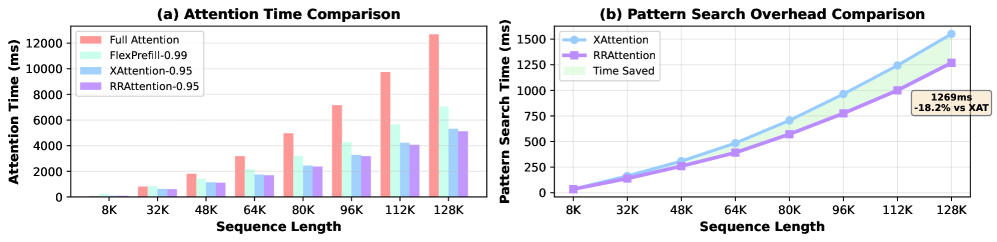
- 实验表明,RRAttention在计算量减半的情况下,恢复了超过99%的完整注意力性能,并实现了显著的加速。
📝 摘要(中文)
注意力机制的平方复杂度是大型语言模型处理长上下文的关键瓶颈。动态稀疏注意力方法虽然能根据输入自适应地提高效率,但面临着根本性的权衡:需要预处理、缺乏全局评估、违反查询独立性或产生高计算开销。我们提出了RRAttention,一种新颖的动态稀疏注意力方法,通过头部轮询(RR)采样策略同时实现所有理想属性。通过在每个步幅内的注意力头之间旋转查询采样位置,RRAttention保持了查询独立性,同时实现了步幅级别聚合的高效全局模式发现。我们的方法将复杂度从$O(L^2)$降低到$O(L^2/S^2)$,并采用自适应Top-$τ$选择以获得最佳稀疏性。在自然语言理解(HELMET)和多模态视频理解(Video-MME)上的大量实验表明,RRAttention恢复了超过99%的完整注意力性能,同时仅计算一半的注意力块,在128K上下文长度下实现了2.4倍的加速,并优于现有的动态稀疏注意力方法。
🔬 方法详解
问题定义:现有注意力机制在处理长文本时面临平方级别的计算复杂度,导致效率瓶颈。动态稀疏注意力方法旨在解决这个问题,但往往需要在预处理、全局评估、查询独立性和计算开销之间进行权衡。例如,一些方法需要预处理步骤来确定重要的注意力块,另一些方法可能无法充分利用全局信息,或者会引入额外的计算负担。
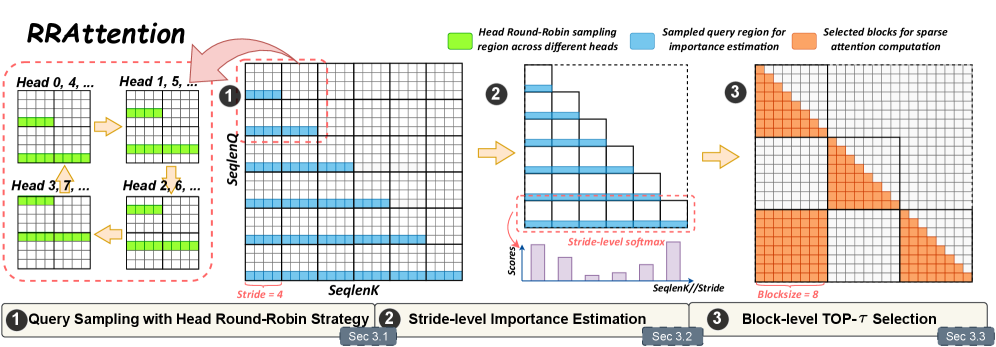
核心思路:RRAttention的核心思路是通过头部轮询(Round-Robin)采样策略,在不同的注意力头之间轮流采样查询位置,从而实现动态稀疏注意力。这种设计允许模型在保持查询独立性的同时,有效地探索全局上下文信息。通过步幅级别的聚合,RRAttention能够捕捉长距离依赖关系,并降低计算复杂度。
技术框架:RRAttention的整体框架包括以下几个主要步骤:1) 将输入序列划分为步幅(stride);2) 在每个步幅内,不同的注意力头轮流采样不同的查询位置;3) 对采样后的查询和键进行注意力计算,得到稀疏的注意力矩阵;4) 对步幅内的注意力结果进行聚合,得到最终的输出。该框架的关键在于头部轮询采样策略,它保证了每个查询位置都有机会被不同的注意力头关注到。
关键创新:RRAttention最重要的技术创新点在于其头部轮询采样策略。与传统的静态稀疏注意力方法不同,RRAttention的采样位置是动态变化的,并且由不同的注意力头负责。这种设计使得模型能够自适应地关注不同的上下文信息,从而提高了模型的表达能力。此外,RRAttention还采用了自适应Top-$τ$选择,进一步提高了稀疏性和效率。
关键设计:RRAttention的关键设计包括:1) 步幅大小的选择:步幅大小决定了模型的感受野和计算复杂度。较小的步幅可以捕捉更细粒度的信息,但会增加计算量;较大的步幅则相反。2) Top-$τ$的选择:Top-$τ$决定了注意力矩阵的稀疏程度。较小的$τ$可以提高稀疏性,但可能会损失一些重要的信息;较大的$τ$则相反。3) 损失函数的设计:可以使用标准的交叉熵损失函数进行训练。此外,还可以引入一些正则化项,以鼓励模型学习到更稀疏的注意力模式。
🖼️ 关键图片
📊 实验亮点
实验结果表明,RRAttention在自然语言理解(HELMET)和多模态视频理解(Video-MME)任务上取得了显著的性能提升。在128K上下文长度下,RRAttention实现了2.4倍的加速,同时恢复了超过99%的完整注意力性能。此外,RRAttention还优于现有的动态稀疏注意力方法,证明了其有效性和优越性。
🎯 应用场景
RRAttention具有广泛的应用前景,尤其适用于需要处理长文本序列的任务,如机器翻译、文本摘要、问答系统和视频理解。该方法可以显著降低计算成本,提高推理速度,使得大型语言模型能够更好地应用于资源受限的场景。此外,RRAttention的动态稀疏特性使其能够更好地适应不同的输入序列,提高模型的鲁棒性和泛化能力。
📄 摘要(原文)
The quadratic complexity of attention mechanisms poses a critical bottleneck for large language models processing long contexts. While dynamic sparse attention methods offer input-adaptive efficiency, they face fundamental trade-offs: requiring preprocessing, lacking global evaluation, violating query independence, or incurring high computational overhead. We present RRAttention, a novel dynamic sparse attention method that simultaneously achieves all desirable properties through a head \underline{r}ound-\underline{r}obin (RR) sampling strategy. By rotating query sampling positions across attention heads within each stride, RRAttention maintains query independence while enabling efficient global pattern discovery with stride-level aggregation. Our method reduces complexity from $O(L^2)$ to $O(L^2/S^2)$ and employs adaptive Top-$τ$ selection for optimal sparsity. Extensive experiments on natural language understanding (HELMET) and multimodal video comprehension (Video-MME) demonstrate that RRAttention recovers over 99\% of full attention performance while computing only half of the attention blocks, achieving 2.4$\times$ speedup at 128K context length and outperforming existing dynamic sparse attention methods.