OdysseyArena: Benchmarking Large Language Models For Long-Horizon, Active and Inductive Interactions
作者: Fangzhi Xu, Hang Yan, Qiushi Sun, Jinyang Wu, Zixian Huang, Muye Huang, Jingyang Gong, Zichen Ding, Kanzhi Cheng, Yian Wang, Xinyu Che, Zeyi Sun, Jian Zhang, Zhangyue Yin, Haoran Luo, Xuanjing Huang, Ben Kao, Jun Liu, Qika Lin
分类: cs.CL
发布日期: 2026-02-05
备注: 34 pages
🔗 代码/项目: GITHUB
💡 一句话要点
OdysseyArena:用于长时程、主动和归纳交互的大语言模型基准测试
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 自主智能体 归纳推理 长时程规划 基准测试
📋 核心要点
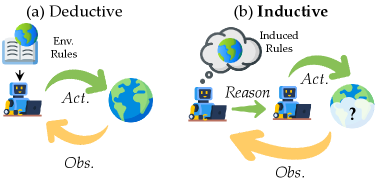
- 现有LLM智能体评估侧重演绎推理,忽略了从经验中学习潜在转移规律的归纳能力,限制了其在复杂环境中的自主发现。
- OdysseyArena通过形式化四个原语,构建长时程、主动和归纳交互环境,重新聚焦智能体评估的重点。
- 实验表明,即使是领先的LLM在OdysseyArena的归纳场景中也表现出不足,揭示了自主发现能力的关键瓶颈。
📝 摘要(中文)
大语言模型(LLMs)的快速发展推动了自主智能体在复杂环境中导航的能力。然而,现有的评估主要采用演绎范式,智能体基于明确提供的规则和静态目标执行任务,且通常规划时程有限。重要的是,这忽略了智能体自主地从经验中发现潜在转移规律的归纳必要性,而这正是实现智能体远见和维持战略连贯性的基石。为了弥合这一差距,我们引入了OdysseyArena,它将智能体评估重新聚焦于长时程、主动和归纳交互。我们形式化并实例化了四个原语,将抽象的转移动态转化为具体的交互环境。在此基础上,我们建立了OdysseyArena-Lite用于标准化基准测试,提供了一组120个任务来衡量智能体的归纳效率和长时程发现能力。更进一步,我们引入了OdysseyArena-Challenge,以压力测试智能体在极端交互时程(例如,> 200步)中的稳定性。对15+个领先LLM的广泛实验表明,即使是最前沿的模型也表现出在归纳场景中的不足,这表明了在复杂环境中追求自主发现的一个关键瓶颈。
🔬 方法详解
问题定义:现有的大语言模型智能体评估主要集中在演绎推理上,即给定明确的规则和目标,智能体执行任务。这种方法忽略了智能体自主地从经验中学习环境动态(即状态转移规律)的能力,而这种归纳能力对于智能体在复杂、未知的环境中进行长期规划和决策至关重要。现有评估方法的痛点在于无法有效衡量智能体在真实世界中进行自主探索和学习的能力。
核心思路:OdysseyArena的核心思路是将智能体评估的重点从演绎推理转移到归纳推理,即评估智能体在与环境交互的过程中,能否有效地学习和利用环境的动态规律。通过构建一系列需要智能体主动探索和学习才能完成的任务,OdysseyArena旨在衡量智能体的归纳效率和长时程发现能力。这种设计使得评估更加贴近真实世界的应用场景,能够更全面地反映智能体的智能水平。
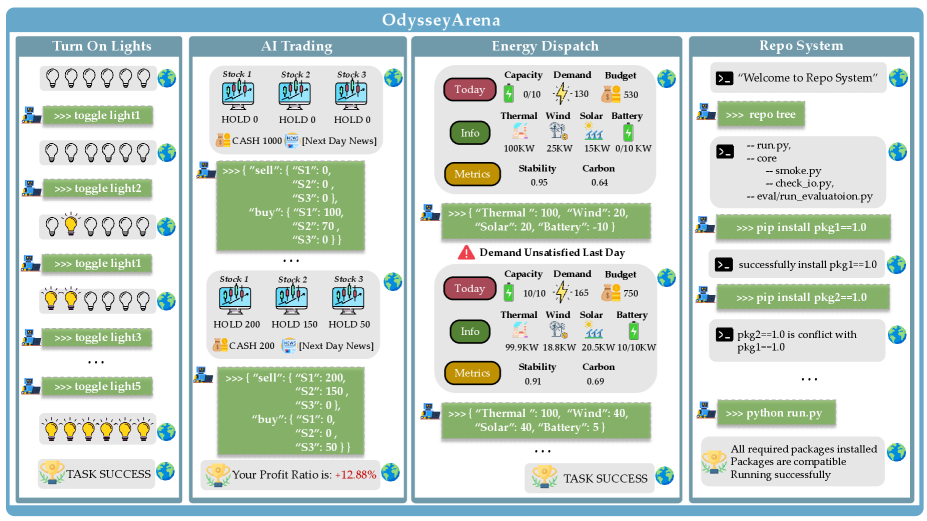
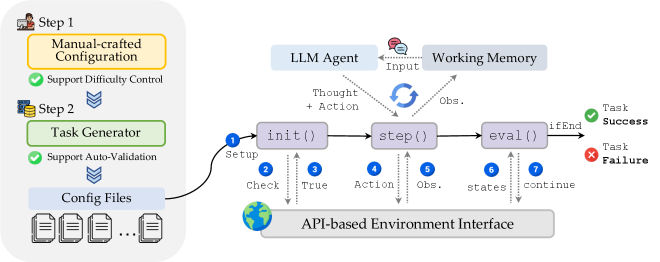
技术框架:OdysseyArena包含两个主要部分:OdysseyArena-Lite和OdysseyArena-Challenge。OdysseyArena-Lite用于标准化基准测试,包含120个任务,旨在衡量智能体的归纳效率和长时程发现能力。OdysseyArena-Challenge则用于压力测试智能体在极端交互时程(例如,> 200步)中的稳定性。整个框架基于四个原语构建,这些原语将抽象的转移动态转化为具体的交互环境,为智能体提供可交互的学习环境。
关键创新:OdysseyArena最重要的技术创新点在于其对智能体评估范式的转变,从传统的演绎推理转向了更具挑战性的归纳推理。与现有方法相比,OdysseyArena更加强调智能体自主学习和探索的能力,能够更真实地反映智能体在复杂环境中的表现。此外,OdysseyArena还提供了一个标准化的基准测试平台,方便研究人员进行比较和分析。
关键设计:OdysseyArena的关键设计包括四个原语的设计,这些原语旨在模拟真实世界中常见的交互模式,例如资源管理、路径规划等。任务的设计需要智能体进行长时程的规划和决策,并且需要智能体不断地从经验中学习和改进。此外,OdysseyArena还提供了一套评估指标,用于衡量智能体的归纳效率、长时程发现能力和稳定性。
🖼️ 关键图片
📊 实验亮点
实验结果表明,即使是最前沿的大语言模型在OdysseyArena的归纳场景中也表现出明显的不足,这表明当前LLM在自主发现和长期规划方面存在瓶颈。具体来说,模型在需要进行长时程推理和主动探索的任务中表现较差,表明其在学习和利用环境动态规律方面存在局限性。这些结果突出了OdysseyArena作为评估和改进LLM智能体的重要工具的价值。
🎯 应用场景
OdysseyArena的研究成果可应用于开发更智能、更自主的机器人和智能体,使其能够在复杂、未知的环境中执行任务。例如,在自动驾驶领域,智能体需要不断地从驾驶经验中学习和适应新的交通状况;在智能家居领域,智能体需要根据用户的行为习惯进行个性化服务。此外,该研究还有助于推动通用人工智能的发展,使机器能够像人类一样进行自主学习和推理。
📄 摘要(原文)
The rapid advancement of Large Language Models (LLMs) has catalyzed the development of autonomous agents capable of navigating complex environments. However, existing evaluations primarily adopt a deductive paradigm, where agents execute tasks based on explicitly provided rules and static goals, often within limited planning horizons. Crucially, this neglects the inductive necessity for agents to discover latent transition laws from experience autonomously, which is the cornerstone for enabling agentic foresight and sustaining strategic coherence. To bridge this gap, we introduce OdysseyArena, which re-centers agent evaluation on long-horizon, active, and inductive interactions. We formalize and instantiate four primitives, translating abstract transition dynamics into concrete interactive environments. Building upon this, we establish OdysseyArena-Lite for standardized benchmarking, providing a set of 120 tasks to measure an agent's inductive efficiency and long-horizon discovery. Pushing further, we introduce OdysseyArena-Challenge to stress-test agent stability across extreme interaction horizons (e.g., > 200 steps). Extensive experiments on 15+ leading LLMs reveal that even frontier models exhibit a deficiency in inductive scenarios, identifying a critical bottleneck in the pursuit of autonomous discovery in complex environments. Our code and data are available at https://github.com/xufangzhi/Odyssey-Arena