Reinforcement World Model Learning for LLM-based Agents
作者: Xiao Yu, Baolin Peng, Ruize Xu, Yelong Shen, Pengcheng He, Suman Nath, Nikhil Singh, Jiangfeng Gao, Zhou Yu
分类: cs.CL
发布日期: 2026-02-05
💡 一句话要点
提出RWML,通过强化世界模型学习提升LLM智能体在文本环境中的决策能力。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: LLM智能体 世界模型 强化学习 自监督学习 文本环境 环境建模 sim-to-real 决策智能
📋 核心要点
- LLM智能体在复杂环境中难以准确预测行为后果和适应环境变化,缺乏有效的世界建模能力是关键瓶颈。
- RWML通过自监督学习,在预训练嵌入空间中对齐模拟和真实环境状态,提升LLM智能体对环境动态的理解和预测能力。
- 实验表明,RWML在ALFWorld和$τ^2$ Bench上显著优于基线模型,并能与专家数据训练的效果相媲美。
📝 摘要(中文)
大型语言模型(LLMs)在以语言为中心的任务中表现出色。然而,在智能体环境中,LLMs常常难以预测行为的后果并适应环境动态,这突显了LLM智能体对世界建模能力的需求。我们提出强化世界模型学习(RWML),这是一种自监督方法,它利用sim-to-real gap奖励,为基于LLM的智能体在文本状态上学习动作条件的世界模型。我们的方法将模型产生的模拟的下一个状态与环境中观察到的实际的下一个状态对齐,从而鼓励内部世界模拟与实际环境动态之间的一致性,对齐发生在预训练的嵌入空间中。与优先考虑token级别保真度(即,重现确切措辞)的下一个状态token预测不同,我们的方法提供了更强大的训练信号,并且在经验上比LLM-as-a-judge更不容易受到奖励黑客攻击。我们在ALFWorld和$τ^2$ Bench上评估了我们的方法,并观察到相对于基础模型有显著的提升,尽管是完全自监督的。当与任务成功奖励相结合时,我们的方法在ALFWorld和$τ^2$ Bench上分别比直接任务成功奖励RL高出6.9和5.7个百分点,同时与专家数据训练的性能相匹配。
🔬 方法详解
问题定义:论文旨在解决LLM智能体在复杂文本环境中进行决策时,由于缺乏对环境动态的准确建模而导致的性能瓶颈。现有方法,如直接预测下一个状态的token,过于注重字面上的匹配,忽略了语义上的等价性,容易导致模型崩溃,并且容易受到奖励机制的攻击。
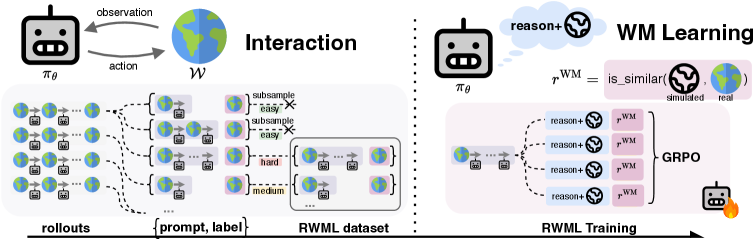
核心思路:RWML的核心思路是通过学习一个动作条件的世界模型,使LLM智能体能够模拟环境的演变,从而更好地预测行为的后果。通过在预训练的嵌入空间中对齐模拟状态和真实状态,RWML鼓励模型学习环境的内在动态,而不是简单地复制文本。
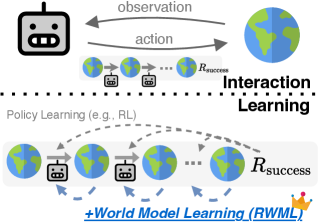
技术框架:RWML的整体框架包含以下几个主要模块:1) LLM智能体:负责根据当前状态选择动作。2) 世界模型:根据当前状态和动作预测下一个状态。3) 环境:根据智能体的动作更新状态。4) 奖励函数:评估智能体的行为。RWML的关键在于世界模型的训练,它通过最小化模拟状态和真实状态在嵌入空间中的距离来实现。
关键创新:RWML最重要的技术创新点在于其自监督的学习方式,它避免了对大量人工标注数据的依赖。通过sim-to-real gap奖励,RWML能够有效地对齐模拟环境和真实环境,从而学习到更准确的世界模型。与传统的token预测方法相比,RWML更加注重语义上的等价性,从而提高了模型的鲁棒性和泛化能力。
关键设计:RWML的关键设计包括:1) 使用预训练的嵌入空间来表示状态,这有助于模型捕捉状态的语义信息。2) 使用sim-to-real gap奖励来对齐模拟状态和真实状态,这鼓励模型学习环境的内在动态。3) 使用强化学习来优化智能体的行为,使其能够更好地利用世界模型进行决策。
🖼️ 关键图片
📊 实验亮点
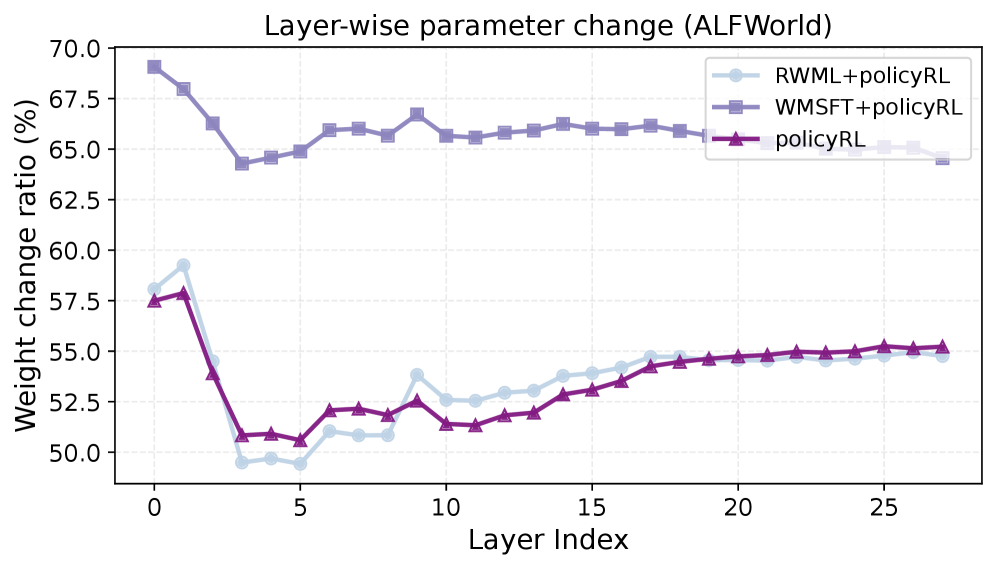
RWML在ALFWorld和$τ^2$ Bench两个文本游戏环境中进行了评估,实验结果表明,RWML显著优于基线模型。在ALFWorld上,RWML比基线模型提升了6.9个百分点,在$τ^2$ Bench上提升了5.7个百分点。更重要的是,RWML的性能与使用专家数据训练的模型相匹配,这表明RWML具有很强的学习能力。
🎯 应用场景
RWML具有广泛的应用前景,可用于开发更智能、更自主的LLM智能体,应用于游戏、机器人控制、对话系统等领域。通过提升LLM智能体对环境的理解和预测能力,RWML可以帮助它们更好地完成复杂任务,并与人类进行更自然的交互。未来,RWML可以进一步扩展到多模态环境,从而支持更丰富的应用场景。
📄 摘要(原文)
Large language models (LLMs) have achieved strong performance in language-centric tasks. However, in agentic settings, LLMs often struggle to anticipate action consequences and adapt to environment dynamics, highlighting the need for world-modeling capabilities in LLM-based agents. We propose Reinforcement World Model Learning (RWML), a self-supervised method that learns action-conditioned world models for LLM-based agents on textual states using sim-to-real gap rewards. Our method aligns simulated next states produced by the model with realized next states observed from the environment, encouraging consistency between internal world simulations and actual environment dynamics in a pre-trained embedding space. Unlike next-state token prediction, which prioritizes token-level fidelity (i.e., reproducing exact wording) over semantic equivalence and can lead to model collapse, our method provides a more robust training signal and is empirically less susceptible to reward hacking than LLM-as-a-judge. We evaluate our method on ALFWorld and $τ^2$ Bench and observe significant gains over the base model, despite being entirely self-supervised. When combined with task-success rewards, our method outperforms direct task-success reward RL by 6.9 and 5.7 points on ALFWorld and $τ^2$ Bench respectively, while matching the performance of expert-data training.