LongR: Unleashing Long-Context Reasoning via Reinforcement Learning with Dense Utility Rewards
作者: Bowen Ping, Zijun Chen, Yiyao Yu, Tingfeng Hui, Junchi Yan, Baobao Chang
分类: cs.CL
发布日期: 2026-02-05
💡 一句话要点
LongR:利用强化学习与密集效用奖励,释放长文本推理能力
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 长文本推理 强化学习 密度奖励 信息增益 大型语言模型
📋 核心要点
- 现有方法在长文本推理中依赖稀疏奖励,难以有效指导复杂的推理过程。
- LongR提出动态“思考-阅读”机制,结合上下文密度奖励,量化文档效用。
- 实验表明,LongR在多个长文本基准测试中显著提升性能,并增强了多种强化学习算法。
📝 摘要(中文)
强化学习已成为驱动大型语言模型(LLM)推理的关键。这种能力在长文本场景中同样至关重要,例如长对话理解和结构化数据分析,其挑战不仅在于消耗token,还在于执行严格的推理。现有工作主要集中在数据合成或架构更改上,但最近的研究表明,仅仅依靠稀疏的、仅基于结果的奖励收效甚微,因为这种粗略的信号通常不足以有效地指导复杂的长文本推理。为了解决这个问题,我们提出了LongR,一个统一的框架,通过整合动态的“思考-阅读”机制(将推理与文档查阅交织在一起)以及基于相对信息增益的上下文密度奖励(用于量化相关文档的效用)来增强长文本性能。实验表明,LongR在LongBench v2上实现了9%的提升,并在RULER和InfiniteBench上实现了持续的改进,证明了其在处理大量上下文方面的强大效率。此外,LongR始终如一地提高了各种强化学习算法(例如,DAPO,GSPO)的性能。最后,我们进行了深入分析,以研究推理链长度对效率的影响以及模型对干扰的鲁棒性。
🔬 方法详解
问题定义:论文旨在解决大型语言模型在长文本场景下进行有效推理的问题。现有方法,如仅依赖稀疏奖励的强化学习,无法充分指导模型在长文本中进行复杂的推理和信息检索,导致性能受限。痛点在于奖励信号不足以区分相关信息和干扰信息,模型难以学习到有效的推理策略。
核心思路:LongR的核心思路是将推理过程与文档查阅过程交织在一起,形成一个动态的“思考-阅读”循环。同时,引入上下文密度奖励,基于相对信息增益来量化文档的效用,从而为强化学习提供更密集、更具指导性的奖励信号。这样可以帮助模型更好地识别和利用长文本中的相关信息,提高推理的准确性和效率。
技术框架:LongR框架包含以下主要模块:1) “思考”模块:利用LLM进行推理,并决定下一步需要查阅的文档。2) “阅读”模块:根据“思考”模块的决策,从长文本上下文中检索相关文档。3) 奖励模块:基于相对信息增益计算上下文密度奖励,评估检索到的文档的效用。4) 强化学习算法:利用密度奖励优化LLM的推理策略。整个流程是一个循环迭代的过程,模型在推理过程中不断查阅文档,并根据奖励信号调整策略。
关键创新:LongR最重要的技术创新点在于引入了上下文密度奖励,它不同于传统的稀疏奖励,能够更细粒度地评估文档的效用,从而为强化学习提供更有效的指导。此外,动态的“思考-阅读”机制也使得模型能够更灵活地利用长文本信息,避免了信息过载的问题。
关键设计:上下文密度奖励基于相对信息增益计算,具体来说,它衡量了在给定当前上下文的情况下,检索到的文档能够提供多少额外的信息。损失函数采用标准的强化学习损失函数,例如DAPO或GSPO。网络结构方面,LongR可以与各种LLM结合使用,无需对LLM的架构进行修改。
🖼️ 关键图片


📊 实验亮点
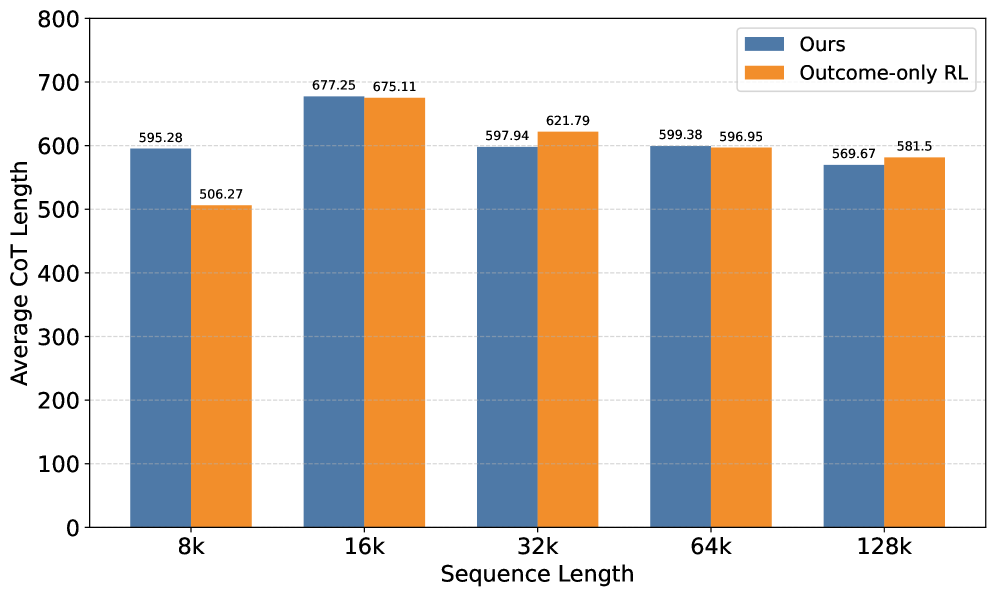
LongR在LongBench v2上实现了9%的性能提升,并在RULER和InfiniteBench上取得了持续的改进。实验结果表明,LongR能够有效地处理长文本上下文,并显著提高LLM的推理能力。此外,LongR还能够与多种强化学习算法兼容,进一步证明了其通用性和有效性。
🎯 应用场景
LongR具有广泛的应用前景,包括长对话理解、结构化数据分析、法律文档审查、医学报告解读等需要处理大量上下文信息的场景。该研究可以提升LLM在这些领域的应用效果,提高工作效率,并为未来的长文本推理研究提供新的思路。
📄 摘要(原文)
Reinforcement Learning has emerged as a key driver for LLM reasoning. This capability is equally pivotal in long-context scenarios--such as long-dialogue understanding and structured data analysis, where the challenge extends beyond consuming tokens to performing rigorous deduction. While existing efforts focus on data synthesis or architectural changes, recent work points out that relying solely on sparse, outcome-only rewards yields limited gains, as such coarse signals are often insufficient to effectively guide the complex long-context reasoning. To address this, we propose LongR, a unified framework that enhances long-context performance by integrating a dynamic "Think-and-Read" mechanism, which interleaves reasoning with document consultation, with a contextual density reward based on relative information gain to quantify the utility of the relevant documents. Empirically, LongR achieves a 9% gain on LongBench v2 and consistent improvements on RULER and InfiniteBench, demonstrating robust efficiency in navigating extensive contexts. Furthermore, LongR consistently enhances performance across diverse RL algorithms (e.g., DAPO, GSPO). Finally, we conduct in-depth analyses to investigate the impact of reasoning chain length on efficiency and the model's robustness against distractors.