Consensus-Aligned Neuron Efficient Fine-Tuning Large Language Models for Multi-Domain Machine Translation
作者: Shuting Jiang, Ran Song, Yuxin Huang, Yan Xiang, Yantuan Xian, Shengxiang Gao, Zhengtao Yu
分类: cs.CL
发布日期: 2026-02-05
备注: Accepted by AAAI 2026
💡 一句话要点
提出共识对齐神经元高效微调方法,提升大语言模型在多领域机器翻译中的性能
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多领域机器翻译 大语言模型 参数高效微调 神经元选择 互信息
📋 核心要点
- 现有MDMT方法在领域自适应上存在不足,如领域偏移、参数干扰和泛化能力有限。
- 论文提出一种神经元高效微调框架,通过选择和更新共识对齐的神经元,提升翻译性能。
- 实验结果表明,该方法在多个翻译领域优于现有参数高效微调方法,达到SOTA水平。
📝 摘要(中文)
多领域机器翻译(MDMT)旨在构建一个能够翻译各种领域内容的统一模型。尽管大型语言模型(LLM)展示了令人印象深刻的机器翻译能力,但领域自适应仍然是LLM面临的挑战。现有的MDMT方法,如上下文学习和参数高效微调,通常受到领域偏移、参数干扰和泛化能力有限的影响。本文提出了一种神经元高效的MDMT微调框架,该框架识别并更新LLM中对齐共识的神经元。这些神经元通过最大化神经元行为和领域特征之间的互信息来选择,使LLM能够捕获通用的翻译模式和领域特定的细微差别。然后,我们的方法在这些神经元的指导下微调LLM,有效地减轻了参数干扰和领域特定的过拟合。在十个德语-英语和中文-英语翻译领域中,对三个LLM进行的全面实验表明,我们的方法在已见和未见领域始终优于强大的PEFT基线,实现了最先进的性能。
🔬 方法详解
问题定义:多领域机器翻译旨在构建一个能够处理不同领域文本的统一模型。现有方法,如上下文学习和参数高效微调(PEFT),在处理领域偏移、参数干扰和泛化能力方面存在局限性。领域偏移导致模型在特定领域表现不佳,参数干扰使得不同领域的知识相互影响,而泛化能力不足则限制了模型在新领域的应用。
核心思路:论文的核心思路是识别并微调LLM中对齐共识的神经元。这些神经元被认为能够同时捕获通用翻译模式和领域特定信息。通过选择性地更新这些神经元,可以减少参数干扰,并提高模型在特定领域的性能和泛化能力。这种方法旨在在模型容量和领域适应性之间取得平衡。
技术框架:该框架主要包含两个阶段:神经元选择和微调。在神经元选择阶段,通过计算神经元行为和领域特征之间的互信息来选择共识对齐的神经元。互信息越高,表明该神经元与领域特征的相关性越强。在微调阶段,使用选择的神经元作为指导,对LLM进行微调。微调过程旨在更新这些神经元的权重,使其更好地适应特定领域的翻译任务。
关键创新:该方法最重要的创新点在于提出了共识对齐神经元的概念,并利用互信息来选择这些神经元。与传统的微调方法不同,该方法不是更新所有参数,而是只更新与领域特征相关的神经元,从而提高了微调的效率和效果。这种选择性更新策略可以减少参数干扰,并提高模型的泛化能力。
关键设计:在神经元选择阶段,需要定义神经元行为和领域特征。神经元行为可以通过神经元的激活值来表示,而领域特征可以通过领域标签或领域相关的词汇来表示。互信息的计算可以使用不同的方法,例如基于熵的方法或基于核密度估计的方法。在微调阶段,可以使用不同的损失函数,例如交叉熵损失或对比损失。此外,还可以使用不同的优化器和学习率策略来优化模型。
🖼️ 关键图片

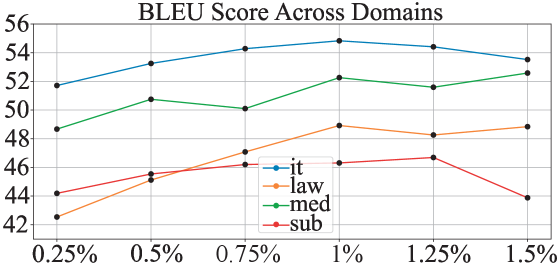

📊 实验亮点
实验结果表明,该方法在十个德语-英语和中文-英语翻译领域中,始终优于强大的参数高效微调(PEFT)基线,并在已见和未见领域均实现了最先进的性能。具体提升幅度未知,但摘要强调了其一致性和优越性,表明该方法在多领域机器翻译任务中具有显著优势。
🎯 应用场景
该研究成果可广泛应用于机器翻译领域,尤其是在需要处理多种领域文本的场景下,例如:跨境电商、多语言客服、国际新闻翻译等。通过提升模型在特定领域的翻译质量,可以提高用户体验,降低翻译成本,并促进跨文化交流。未来,该方法可以扩展到其他自然语言处理任务,例如文本分类、情感分析等。
📄 摘要(原文)
Multi-domain machine translation (MDMT) aims to build a unified model capable of translating content across diverse domains. Despite the impressive machine translation capabilities demonstrated by large language models (LLMs), domain adaptation still remains a challenge for LLMs. Existing MDMT methods such as in-context learning and parameter-efficient fine-tuning often suffer from domain shift, parameter interference and limited generalization. In this work, we propose a neuron-efficient fine-tuning framework for MDMT that identifies and updates consensus-aligned neurons within LLMs. These neurons are selected by maximizing the mutual information between neuron behavior and domain features, enabling LLMs to capture both generalizable translation patterns and domain-specific nuances. Our method then fine-tunes LLMs guided by these neurons, effectively mitigating parameter interference and domain-specific overfitting. Comprehensive experiments on three LLMs across ten German-English and Chinese-English translation domains evidence that our method consistently outperforms strong PEFT baselines on both seen and unseen domains, achieving state-of-the-art performance.