Multi-Task GRPO: Reliable LLM Reasoning Across Tasks
作者: Shyam Sundhar Ramesh, Xiaotong Ji, Matthieu Zimmer, Sangwoong Yoon, Zhiyong Wang, Haitham Bou Ammar, Aurelien Lucchi, Ilija Bogunovic
分类: cs.CL, cs.AI, cs.LG
发布日期: 2026-02-05
备注: Preprint
💡 一句话要点
提出MT-GRPO算法,提升LLM在多任务场景下的可靠推理性能,尤其关注最差任务表现。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多任务学习 大型语言模型 强化学习 策略优化 任务权重调整
📋 核心要点
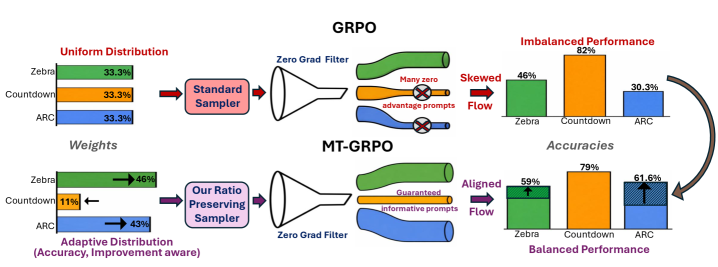
- 现有基于GRPO的多任务LLM训练方法存在任务间性能不平衡问题,部分任务优化停滞。
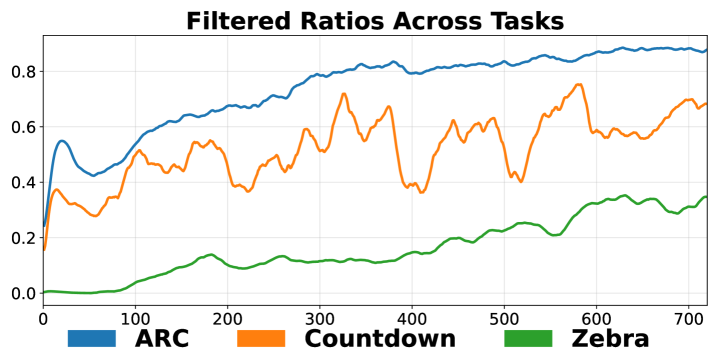
- MT-GRPO通过动态调整任务权重优化最差任务性能,并使用比例保留采样器保证梯度更新。
- 实验表明,MT-GRPO显著提升了最差任务的准确率,并提高了训练效率,优于现有方法。
📝 摘要(中文)
基于GRPO的强化学习后训练被广泛应用于提升大型语言模型在单个推理任务上的性能。然而,实际部署需要模型在不同任务上表现出可靠的性能。直接将GRPO应用于多任务场景通常会导致不平衡的结果,一些任务主导优化过程,而另一些任务则停滞不前。此外,不同任务的prompt产生零优势(从而产生零梯度)的频率差异很大,这进一步扭曲了它们对优化信号的有效贡献。为了解决这些问题,我们提出了一种新的多任务GRPO(MT-GRPO)算法,该算法(i)动态调整任务权重,以显式优化最差任务的性能,并促进跨任务的平衡进展,以及(ii)引入一种比例保留采样器,以确保任务策略梯度反映调整后的权重。在3任务和9任务设置上的实验表明,MT-GRPO在最差任务准确率方面始终优于基线。特别是,MT-GRPO在最差任务性能方面分别比标准GRPO和DAPO实现了16-28%和6%的绝对改进,同时保持了具有竞争力的平均准确率。此外,MT-GRPO在3任务设置中达到50%的最差任务准确率所需的训练步数减少了50%,表明在实现跨任务的可靠性能方面效率显著提高。
🔬 方法详解
问题定义:论文旨在解决多任务学习中,大型语言模型(LLM)在不同任务上性能不均衡的问题。现有方法,如直接应用GRPO,会导致某些任务主导训练,而另一些任务则停滞不前。此外,不同任务的prompt产生零优势的频率不同,影响了优化信号的有效性。
核心思路:MT-GRPO的核心思路是动态调整任务权重,显式地优化最差任务的性能,从而促进所有任务的平衡进展。同时,通过比例保留采样器,确保策略梯度能够反映调整后的权重,避免梯度偏差。
技术框架:MT-GRPO的整体框架基于GRPO(Generalized Policy Optimization),并在其基础上进行了改进。主要包含以下几个模块:1) 动态任务权重调整模块:根据任务的性能动态调整权重,更关注表现较差的任务。2) 比例保留采样器:根据调整后的任务权重,对训练数据进行采样,确保策略梯度能够反映这些权重。3) GRPO优化器:使用GRPO算法更新LLM的策略。
关键创新:MT-GRPO的关键创新在于动态任务权重调整和比例保留采样器。动态任务权重调整能够显式地优化最差任务的性能,避免了某些任务主导训练过程。比例保留采样器则保证了策略梯度能够准确地反映调整后的任务权重,避免了梯度偏差。与现有方法相比,MT-GRPO能够更有效地平衡不同任务的性能。
关键设计:动态任务权重的调整可能基于多种策略,例如,可以采用基于性能的指数加权平均,或者使用更复杂的优化算法来确定最佳权重。比例保留采样器需要仔细设计,以确保采样的效率和准确性。损失函数仍然基于GRPO的损失函数,但需要根据调整后的任务权重进行加权。具体的网络结构取决于所使用的LLM。
🖼️ 关键图片

📊 实验亮点
实验结果表明,MT-GRPO在3任务和9任务设置中,最差任务准确率方面始终优于基线方法。在最差任务性能方面,MT-GRPO分别比标准GRPO和DAPO实现了16-28%和6%的绝对改进,同时保持了具有竞争力的平均准确率。此外,MT-GRPO在3任务设置中达到50%的最差任务准确率所需的训练步数减少了50%,显著提高了训练效率。
🎯 应用场景
MT-GRPO可应用于需要LLM在多个任务上表现出可靠性能的场景,例如智能客服、多领域问答系统、机器人控制等。通过提升最差任务的性能,可以提高系统的整体鲁棒性和用户体验。该研究对于推动LLM在实际应用中的部署具有重要意义。
📄 摘要(原文)
RL-based post-training with GRPO is widely used to improve large language models on individual reasoning tasks. However, real-world deployment requires reliable performance across diverse tasks. A straightforward multi-task adaptation of GRPO often leads to imbalanced outcomes, with some tasks dominating optimization while others stagnate. Moreover, tasks can vary widely in how frequently prompts yield zero advantages (and thus zero gradients), which further distorts their effective contribution to the optimization signal. To address these issues, we propose a novel Multi-Task GRPO (MT-GRPO) algorithm that (i) dynamically adapts task weights to explicitly optimize worst-task performance and promote balanced progress across tasks, and (ii) introduces a ratio-preserving sampler to ensure task-wise policy gradients reflect the adapted weights. Experiments on both 3-task and 9-task settings show that MT-GRPO consistently outperforms baselines in worst-task accuracy. In particular, MT-GRPO achieves 16-28% and 6% absolute improvement on worst-task performance over standard GRPO and DAPO, respectively, while maintaining competitive average accuracy. Moreover, MT-GRPO requires 50% fewer training steps to reach 50% worst-task accuracy in the 3-task setting, demonstrating substantially improved efficiency in achieving reliable performance across tasks.