LinguistAgent: A Reflective Multi-Model Platform for Automated Linguistic Annotation
作者: Bingru Li
分类: cs.CL, cs.AI, cs.MA
发布日期: 2026-02-05
🔗 代码/项目: GITHUB
💡 一句话要点
LinguistAgent:一个用于自动语言学标注的反射式多模型平台
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 语言学标注 大型语言模型 反射式多模型 隐喻识别 自动化标注
📋 核心要点
- 人工标注成本高昂,尤其在隐喻识别等复杂语义任务中,成为人文社科研究的瓶颈。
- LinguistAgent 采用反射式多模型架构,通过双代理工作流模拟同行评审,实现自动标注。
- LinguistAgent 支持提示工程、检索增强生成和微调等多种范式,并在隐喻识别任务上验证了其有效性。
📝 摘要(中文)
数据标注在人文社会科学领域仍然是一个重要的瓶颈,特别是对于诸如隐喻识别等复杂的语义任务。虽然大型语言模型(LLMs)展现出潜力,但LLMs的理论能力与其对研究人员的实际效用之间仍然存在显著差距。本文介绍LinguistAgent,一个集成的、用户友好的平台,它利用反射式多模型架构来自动化语言学标注。该系统实现了一个双代理工作流程,包括一个标注者和一个审查者,以模拟专业的同行评审过程。LinguistAgent支持跨三种范式的比较实验:提示工程(零/少样本)、检索增强生成和微调。我们以隐喻识别任务为例,展示了LinguistAgent的有效性,并提供了针对人工黄金标准的实时token级别评估(精确率、召回率和F1分数)。该应用和代码已在https://github.com/Bingru-Li/LinguistAgent上发布。
🔬 方法详解
问题定义:论文旨在解决人文社科领域中复杂语义任务(如隐喻识别)的数据标注瓶颈问题。现有方法依赖大量人工标注,成本高、效率低,而直接使用大型语言模型(LLMs)的效果往往不尽如人意,无法满足研究人员的实际需求。
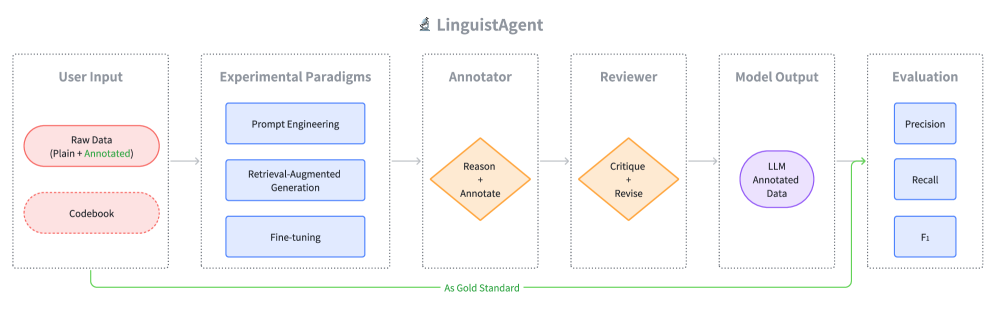
核心思路:论文的核心思路是构建一个反射式多模型平台,通过模拟专业的同行评审过程,利用双代理工作流(标注者和审查者)来提高自动标注的质量和可靠性。这种设计旨在弥合LLMs的理论能力与实际应用之间的差距。
技术框架:LinguistAgent 平台包含以下主要模块:1) 数据输入模块:接收待标注的文本数据。2) 标注者代理:利用LLMs进行初步的语言学标注。3) 审查者代理:对标注者代理的结果进行审查和修正,模拟同行评审。4) 评估模块:根据人工黄金标准,实时评估标注结果的质量(精确率、召回率、F1分数)。5) 实验模块:支持多种实验范式,包括提示工程、检索增强生成和微调。
关键创新:LinguistAgent 的关键创新在于其反射式多模型架构和双代理工作流。通过引入审查者代理,系统能够对标注结果进行自我反思和改进,从而提高标注的准确性和一致性。此外,该平台支持多种实验范式,方便研究人员比较不同方法的性能。
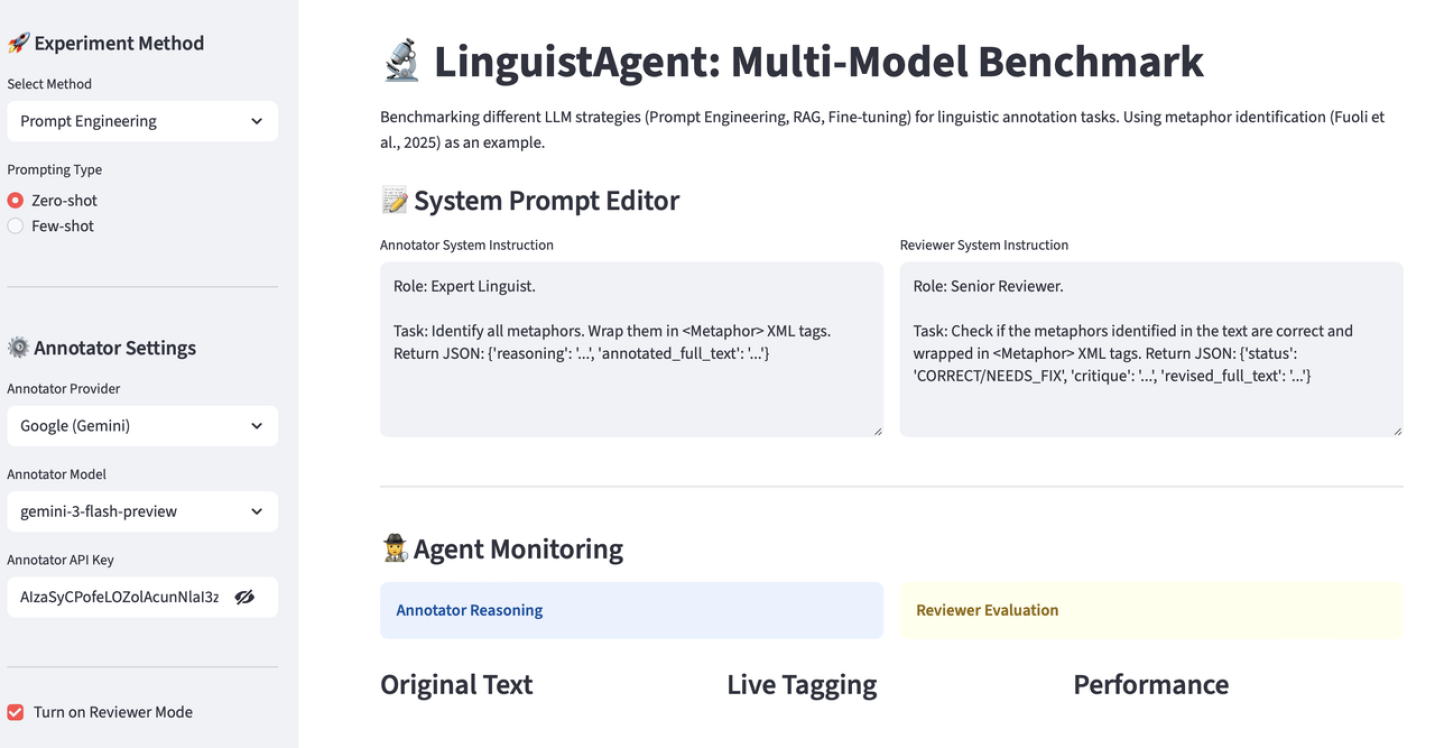
关键设计:LinguistAgent 的关键设计包括:1) 提示工程:针对不同的语言学任务,设计有效的提示语,引导LLMs进行标注。2) 检索增强生成:利用外部知识库,为LLMs提供更丰富的上下文信息,提高标注的准确性。3) 微调:使用特定领域的标注数据,对LLMs进行微调,使其更适应特定的语言学任务。具体的参数设置、损失函数和网络结构等技术细节在论文中未详细描述,属于未知信息。
🖼️ 关键图片

📊 实验亮点
LinguistAgent 在隐喻识别任务上进行了实验验证,结果表明,通过反射式多模型架构和双代理工作流,该平台能够有效提高自动标注的质量。论文提供了实时token级别的精确率、召回率和F1分数,并与人工黄金标准进行了对比,但具体的性能数据和提升幅度在摘要中未明确给出,属于未知信息。
🎯 应用场景
LinguistAgent 可应用于各种人文社科领域的语言学标注任务,如隐喻识别、情感分析、论证挖掘等。该平台能够显著降低人工标注的成本和时间,提高研究效率。未来,LinguistAgent 有望成为语言学研究人员的重要工具,促进相关领域的发展。
📄 摘要(原文)
Data annotation remains a significant bottleneck in the Humanities and Social Sciences, particularly for complex semantic tasks such as metaphor identification. While Large Language Models (LLMs) show promise, a significant gap remains between the theoretical capability of LLMs and their practical utility for researchers. This paper introduces LinguistAgent, an integrated, user-friendly platform that leverages a reflective multi-model architecture to automate linguistic annotation. The system implements a dual-agent workflow, comprising an Annotator and a Reviewer, to simulate a professional peer-review process. LinguistAgent supports comparative experiments across three paradigms: Prompt Engineering (Zero/Few-shot), Retrieval-Augmented Generation, and Fine-tuning. We demonstrate LinguistAgent's efficacy using the task of metaphor identification as an example, providing real-time token-level evaluation (Precision, Recall, and $F_1$ score) against human gold standards. The application and codes are released on https://github.com/Bingru-Li/LinguistAgent.