Causal Front-Door Adjustment for Robust Jailbreak Attacks on LLMs
作者: Yao Zhou, Zeen Song, Wenwen Qiang, Fengge Wu, Shuyi Zhou, Changwen Zheng, Hui Xiong
分类: cs.CL
发布日期: 2026-02-05
💡 一句话要点
提出CFA²框架,利用因果前门调整实现对LLM的鲁棒越狱攻击
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 越狱攻击 因果推断 前门调整 稀疏自编码器 安全对齐 鲁棒性 对抗攻击
📋 核心要点
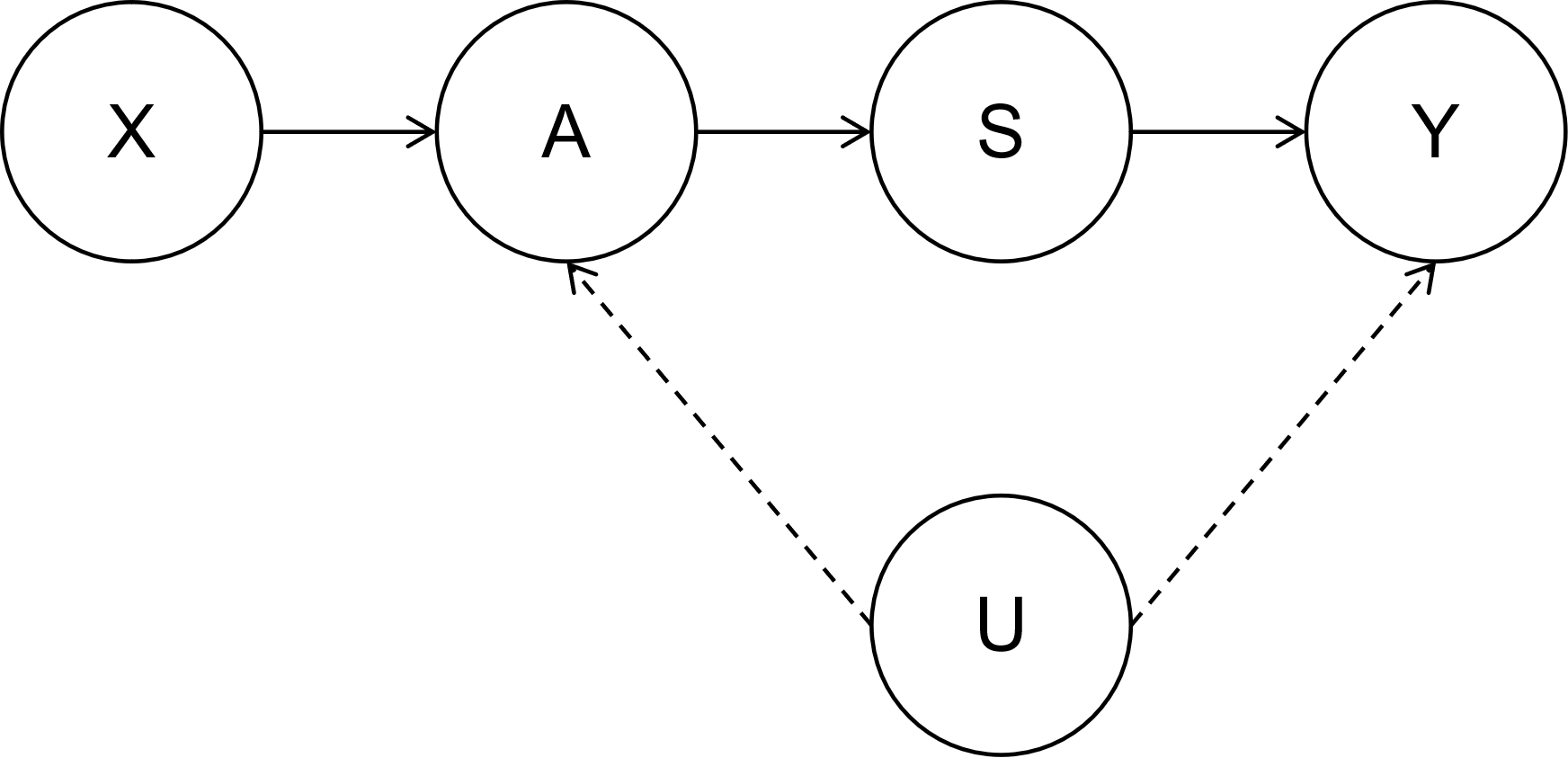
- 大型语言模型(LLM)的安全对齐机制难以直接观测,使得越狱攻击更具挑战。
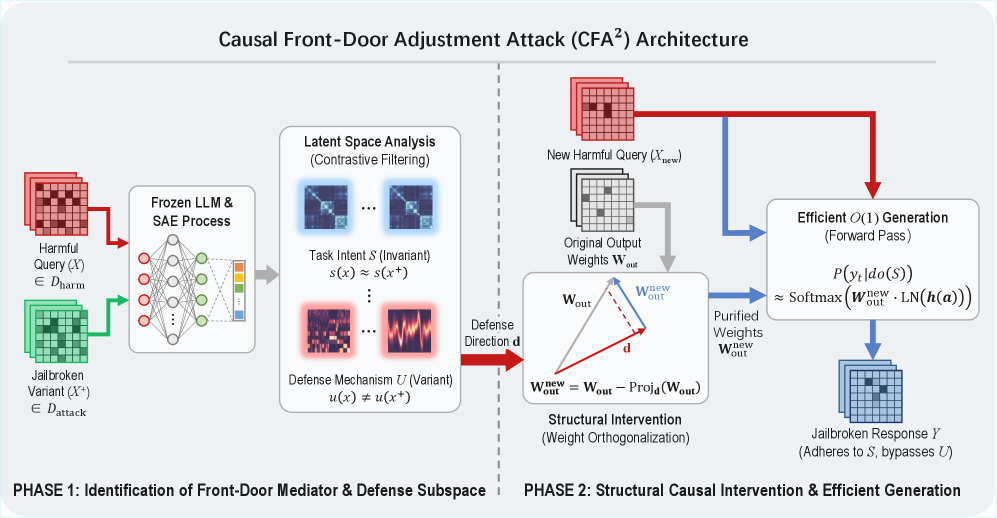
- CFA²框架利用因果前门调整,通过稀疏自编码器剥离防御特征,隔离核心任务意图,实现鲁棒越狱。
- 实验结果表明,CFA²在越狱攻击成功率上达到了当前最优水平,并提供了对越狱过程的机制性解释。
📝 摘要(中文)
大型语言模型(LLM)中的安全对齐机制通常作为潜在的内部状态运行,掩盖了模型固有的能力。基于此,我们从因果角度将安全机制建模为一个未观察到的混淆因素。然后,我们提出了一种因果前门调整攻击(CFA²)来越狱LLM。CFA²是一个利用Pearl的前门准则来切断混淆关联以实现鲁棒越狱的框架。具体来说,我们采用稀疏自编码器(SAE)来物理地剥离与防御相关的特征,从而隔离核心任务意图。我们进一步将计算量大的边缘化操作简化为具有低推理复杂度的确定性干预。实验表明,CFA²实现了最先进的攻击成功率,同时提供了对越狱过程的机制性解释。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)的越狱攻击问题,即绕过LLM的安全对齐机制,使其生成有害或不当内容。现有方法通常难以有效且鲁棒地攻击LLM,因为安全机制作为潜在的内部状态运行,难以直接干预。现有方法缺乏对越狱过程的机制性理解。
核心思路:论文的核心思路是将LLM的安全机制建模为一个未观察到的混淆因素,并利用Pearl的因果前门调整准则来切断混淆关联,从而实现鲁棒的越狱攻击。通过剥离与防御相关的特征,隔离核心任务意图,可以更有效地绕过安全机制。
技术框架:CFA²框架包含以下主要模块:1) 因果建模:将安全机制建模为未观察到的混淆因素。2) 特征剥离:使用稀疏自编码器(SAE)来识别并剥离与防御相关的特征。3) 前门调整:应用Pearl的前门准则,通过干预中间变量来切断混淆关联。4) 确定性干预:将计算量大的边缘化操作简化为具有低推理复杂度的确定性干预。
关键创新:CFA²的关键创新在于:1) 因果视角:首次从因果角度建模LLM的安全机制,为越狱攻击提供了新的理论框架。2) 前门调整:利用Pearl的前门准则,通过干预中间变量来切断混淆关联,实现鲁棒的越狱攻击。3) 稀疏自编码器:使用SAE来物理地剥离防御特征,隔离核心任务意图。
关键设计:1) 稀疏自编码器(SAE):用于识别和剥离与防御相关的特征,通过L1正则化鼓励稀疏性,从而选择性地移除特征。2) 确定性干预:通过将边缘化操作简化为确定性干预,降低了计算复杂度,提高了攻击效率。3) 损失函数:SAE的训练损失函数包含重构损失和稀疏性惩罚项,以确保特征剥离的有效性。
🖼️ 关键图片

📊 实验亮点
实验结果表明,CFA²在越狱攻击成功率上达到了当前最优水平,显著优于现有的攻击方法。具体而言,CFA²在多个LLM上实现了更高的攻击成功率,并且具有更强的鲁棒性,能够有效应对不同的防御机制。同时,该研究提供了对越狱过程的机制性解释,有助于理解LLM的安全漏洞。
🎯 应用场景
该研究成果可应用于评估和提升大型语言模型的安全性,帮助开发者发现和修复潜在的安全漏洞。此外,该方法也可用于研究LLM内部的安全机制,从而更好地理解和控制LLM的行为。该研究对于构建更安全、可靠的AI系统具有重要意义。
📄 摘要(原文)
Safety alignment mechanisms in Large Language Models (LLMs) often operate as latent internal states, obscuring the model's inherent capabilities. Building on this observation, we model the safety mechanism as an unobserved confounder from a causal perspective. Then, we propose the \textbf{C}ausal \textbf{F}ront-Door \textbf{A}djustment \textbf{A}ttack ({\textbf{CFA}}$^2$) to jailbreak LLM, which is a framework that leverages Pearl's Front-Door Criterion to sever the confounding associations for robust jailbreaking. Specifically, we employ Sparse Autoencoders (SAEs) to physically strip defense-related features, isolating the core task intent. We further reduce computationally expensive marginalization to a deterministic intervention with low inference complexity. Experiments demonstrate that {CFA}$^2$ achieves state-of-the-art attack success rates while offering a mechanistic interpretation of the jailbreaking process.