SciDef: Automating Definition Extraction from Academic Literature with Large Language Models
作者: Filip Kučera, Christoph Mandl, Isao Echizen, Radu Timofte, Timo Spinde
分类: cs.IR, cs.CL
发布日期: 2026-02-05
备注: Under Review - Submitted to SIGIR 2026 Resources Track; 8 pages, 6 figures, 4 tables
🔗 代码/项目: GITHUB
💡 一句话要点
SciDef:提出一种基于大语言模型的学术文献定义自动抽取流程。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 定义抽取 大语言模型 自然语言处理 提示工程 知识图谱 学术文献 信息抽取
📋 核心要点
- 现有方法难以应对海量学术文献中定义抽取的需求,人工提取成本高昂且效率低下。
- SciDef 提出利用大语言模型,结合多步提示和 DSPy 优化,实现定义自动抽取。
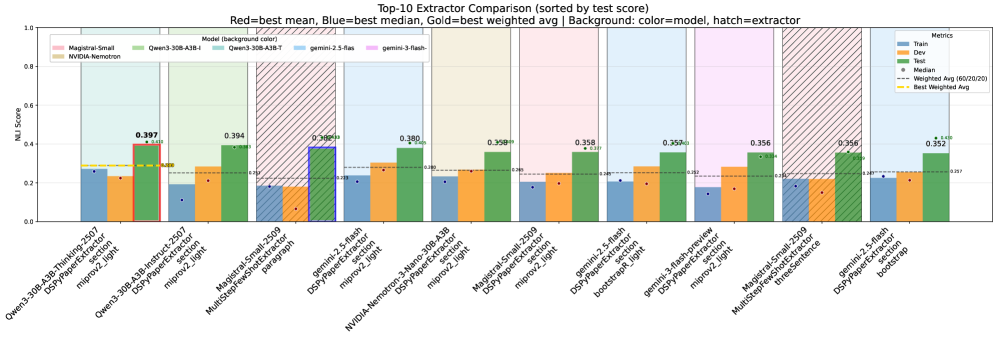
- 实验表明,SciDef 在定义抽取任务上表现良好,能够有效提取科学文献中的定义,准确率达到 86.4%。
📝 摘要(中文)
定义是科学研究的基础,但随着出版物数量的显著增加,收集与关键词相关的定义变得极具挑战性。因此,我们推出了 SciDef,一个基于大语言模型的自动定义抽取流程。我们在 DefExtra 和 DefSim 这两个新的人工提取定义和定义对相似度数据集上测试了 SciDef。通过评估 16 个语言模型在不同提示策略下的表现,我们证明了多步和 DSPy 优化的提示可以提高抽取性能。为了评估抽取效果,我们测试了各种指标,并表明基于 NLI 的方法产生了最可靠的结果。我们表明,大语言模型在很大程度上能够从科学文献中提取定义(占我们测试集中定义的 86.4%);然而,未来的工作不仅应侧重于查找定义,还应侧重于识别相关定义,因为模型往往会过度生成定义。
🔬 方法详解
问题定义:论文旨在解决从海量学术文献中自动抽取定义的问题。现有方法依赖人工,效率低且成本高。此外,如何判断抽取出的定义是否相关也是一个挑战。
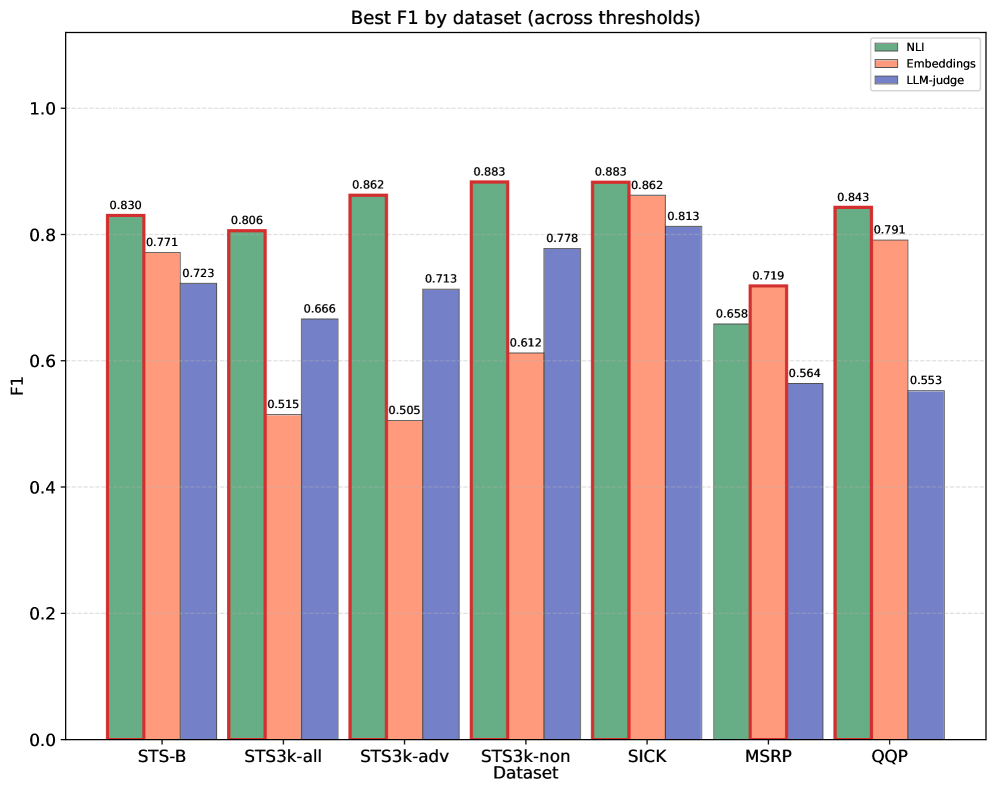
核心思路:论文的核心思路是利用大语言模型强大的文本理解和生成能力,通过精心设计的提示(prompting)策略,引导模型从学术文献中识别并提取定义。同时,利用自然语言推理(NLI)技术来评估抽取定义的质量。
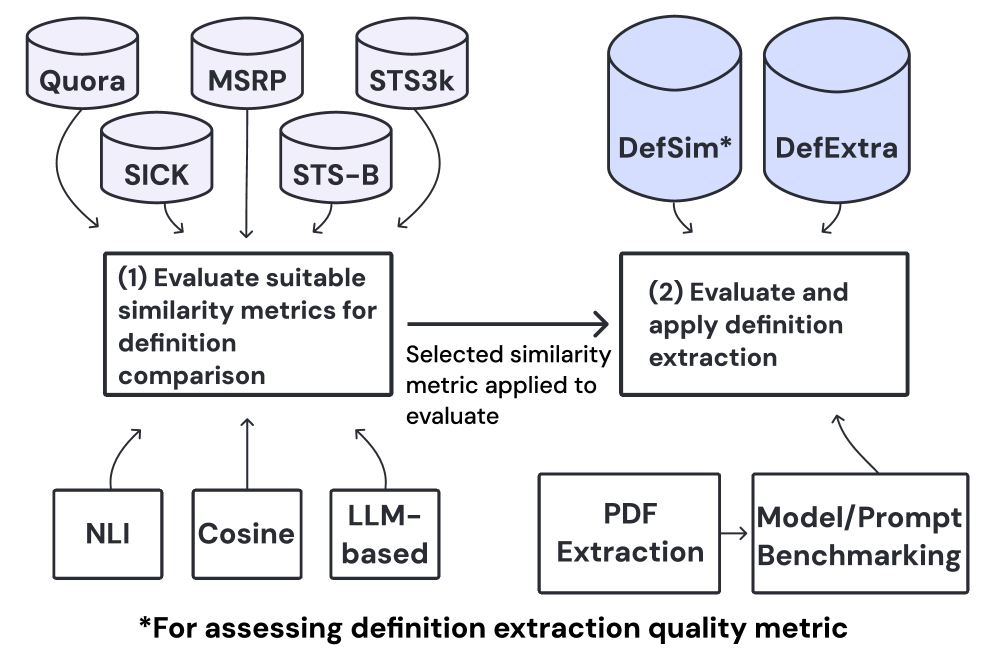
技术框架:SciDef 的整体流程包含以下几个主要阶段:1) 文献输入:输入待抽取定义的学术文献。2) 提示工程:设计多步提示和 DSPy 优化提示,引导大语言模型进行定义抽取。3) 定义抽取:利用大语言模型抽取候选定义。4) 定义评估:使用基于 NLI 的方法评估抽取定义的质量,过滤掉不相关的定义。
关键创新:论文的关键创新在于:1) 提出了 SciDef 流程,将大语言模型应用于学术文献定义抽取任务。2) 探索了多步提示和 DSPy 优化提示策略,提高了定义抽取的性能。3) 提出了基于 NLI 的定义评估方法,能够更可靠地评估抽取定义的质量。
关键设计:论文中,多步提示策略将定义抽取任务分解为多个步骤,例如先识别候选定义,再进行筛选和精炼。DSPy 优化提示则通过自动调整提示词,进一步提升模型性能。基于 NLI 的定义评估方法,将抽取出的定义与上下文进行推理,判断其是否一致和相关。
🖼️ 关键图片
📊 实验亮点
实验结果表明,SciDef 能够有效提取科学文献中的定义,准确率达到 86.4%。多步提示和 DSPy 优化提示策略能够显著提高定义抽取的性能。基于 NLI 的定义评估方法比其他评估指标更可靠。该研究在 DefExtra 和 DefSim 两个数据集上进行了评估,证明了 SciDef 的有效性。
🎯 应用场景
SciDef 可应用于构建自动化的知识图谱、术语表,辅助科研人员快速查找和理解专业术语,提高科研效率。此外,该方法还可用于教育领域,帮助学生更好地理解学术概念。未来,该研究可扩展到其他类型的文本,例如法律文件、新闻报道等。
📄 摘要(原文)
Definitions are the foundation for any scientific work, but with a significant increase in publication numbers, gathering definitions relevant to any keyword has become challenging. We therefore introduce SciDef, an LLM-based pipeline for automated definition extraction. We test SciDef on DefExtra & DefSim, novel datasets of human-extracted definitions and definition-pairs' similarity, respectively. Evaluating 16 language models across prompting strategies, we demonstrate that multi-step and DSPy-optimized prompting improve extraction performance. To evaluate extraction, we test various metrics and show that an NLI-based method yields the most reliable results. We show that LLMs are largely able to extract definitions from scientific literature (86.4% of definitions from our test-set); yet future work should focus not just on finding definitions, but on identifying relevant ones, as models tend to over-generate them. Code & datasets are available at https://github.com/Media-Bias-Group/SciDef.