OPUS: Towards Efficient and Principled Data Selection in Large Language Model Pre-training in Every Iteration
作者: Shaobo Wang, Xuan Ouyang, Tianyi Xu, Yuzheng Hu, Jialin Liu, Guo Chen, Tianyu Zhang, Junhao Zheng, Kexin Yang, Xingzhang Ren, Dayiheng Liu, Linfeng Zhang
分类: cs.CL
发布日期: 2026-02-05
备注: 45 pages, 7 figures, 8 tables
💡 一句话要点
OPUS:通过优化器引导的投影效用选择,实现大语言模型预训练的迭代式高效数据选择。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 预训练 数据选择 优化器 数据效率 动态选择 效用函数
📋 核心要点
- 现有数据选择方法忽略训练动态或与优化器无关,导致预训练效率受限,无法充分利用高质量数据。
- OPUS通过优化器引导的投影效用选择,在优化器更新空间中定义数据效用,动态选择更优数据。
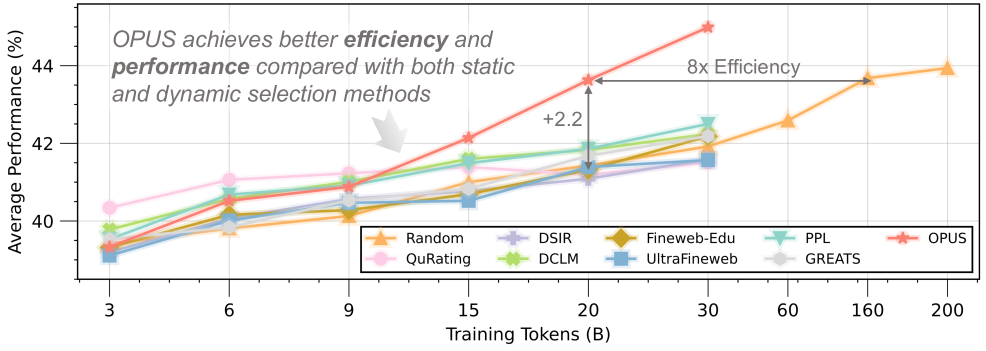
- 实验表明,OPUS在多种设置下均优于现有方法,显著提升了预训练效率,尤其是在数据受限场景下。
📝 摘要(中文)
随着高质量公共文本数据接近耗尽,预训练正从增加token数量转向选择更优token,即面临“数据墙”问题。现有方法要么依赖于忽略训练动态的启发式静态过滤器,要么使用基于原始梯度的、与优化器无关的动态标准。我们提出了OPUS(Optimizer-induced Projected Utility Selection),一个动态数据选择框架,它在优化器引导的更新空间中定义效用。OPUS通过将候选数据的有效更新(由现代优化器塑造)投影到源自稳定、同分布代理的目标方向上来对候选数据进行评分。为了确保可扩展性,我们采用Ghost技术与CountSketch来实现计算效率,并采用Boltzmann抽样来保证数据多样性,仅产生4.7%的额外计算开销。OPUS在不同的语料库、质量层级、优化器和模型规模上取得了显著成果。在FineWeb和FineWeb-Edu上预训练GPT-2 Large/XL 30B tokens时,OPUS优于工业级基线,甚至超过了完整200B token的训练效果。此外,当与工业级静态过滤器结合使用时,OPUS进一步提高了预训练效率,即使使用较低质量的数据也是如此。更进一步,在SciencePedia上持续预训练Qwen3-8B-Base时,OPUS仅使用0.5B tokens就实现了优于完整3B tokens训练的性能,展示了在特定领域中显著的数据效率提升。
🔬 方法详解
问题定义:论文旨在解决大语言模型预训练过程中数据选择效率低下的问题。现有方法,如静态过滤或基于原始梯度的动态选择,要么忽略了训练过程中的动态变化,要么没有充分考虑优化器的影响,导致数据利用率不高,预训练成本增加。
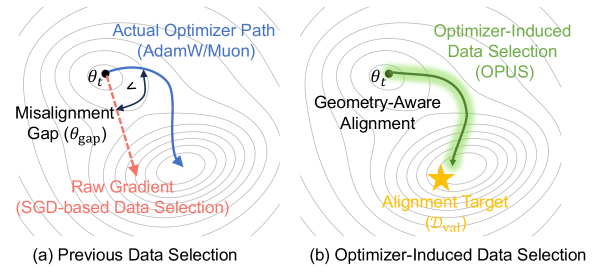
核心思路:OPUS的核心思路是在优化器引导的更新空间中定义数据的效用。这意味着数据的重要性不是由其原始梯度决定,而是由它在优化器作用下产生的实际更新方向和幅度决定。通过将数据的更新投影到一个代表理想训练方向的目标向量上,可以更准确地评估数据的价值。
技术框架:OPUS框架包含以下几个主要步骤:1) 使用一个稳定、同分布的代理数据集来确定目标更新方向。2) 对于每个候选数据样本,计算其在当前优化器下的有效更新。3) 将候选数据的更新投影到目标更新方向上,得到一个效用分数。4) 使用Boltzmann抽样根据效用分数选择数据,以保证数据多样性。为了提高计算效率,采用了Ghost技术和CountSketch算法。
关键创新:OPUS的关键创新在于将优化器纳入数据选择的考量范围。传统的动态数据选择方法通常只关注原始梯度,而忽略了优化器对梯度的修正作用。OPUS通过分析优化器如何塑造数据的更新,从而更准确地评估数据的价值。此外,OPUS还采用了高效的计算技术,使其能够在大规模数据集上进行数据选择。
关键设计:OPUS的关键设计包括:1) 目标更新方向的确定:使用一个小的、高质量的代理数据集,通过训练得到一个稳定的更新方向。2) 效用分数的计算:将候选数据的更新投影到目标更新方向上,投影长度作为效用分数。3) 数据多样性保证:使用Boltzmann抽样,根据效用分数对数据进行抽样,避免过度选择相似的数据。4) 计算效率优化:使用Ghost技术和CountSketch算法来降低计算复杂度。
🖼️ 关键图片

📊 实验亮点
OPUS在GPT-2 Large/XL的预训练中,仅使用30B tokens就超越了工业级基线,甚至达到了完整200B tokens的训练效果。在Qwen3-8B-Base的持续预训练中,OPUS仅使用0.5B tokens就优于完整3B tokens的训练结果,显著提升了数据效率。此外,OPUS与工业级静态过滤器结合使用时,能够进一步提高预训练效率,即使在较低质量的数据集上也能取得良好效果。
🎯 应用场景
OPUS可应用于各种大语言模型的预训练场景,尤其是在高质量数据稀缺或计算资源有限的情况下。它可以帮助研究人员和工程师更有效地利用现有数据,降低预训练成本,并提升模型性能。此外,OPUS还可以应用于特定领域的模型训练,例如科学、医学等,通过选择与领域相关的高价值数据,提高模型在特定任务上的表现。
📄 摘要(原文)
As high-quality public text approaches exhaustion, a phenomenon known as the Data Wall, pre-training is shifting from more tokens to better tokens. However, existing methods either rely on heuristic static filters that ignore training dynamics, or use dynamic yet optimizer-agnostic criteria based on raw gradients. We propose OPUS (Optimizer-induced Projected Utility Selection), a dynamic data selection framework that defines utility in the optimizer-induced update space. OPUS scores candidates by projecting their effective updates, shaped by modern optimizers, onto a target direction derived from a stable, in-distribution proxy. To ensure scalability, we employ Ghost technique with CountSketch for computational efficiency, and Boltzmann sampling for data diversity, incurring only 4.7\% additional compute overhead. OPUS achieves remarkable results across diverse corpora, quality tiers, optimizers, and model scales. In pre-training of GPT-2 Large/XL on FineWeb and FineWeb-Edu with 30B tokens, OPUS outperforms industrial-level baselines and even full 200B-token training. Moreover, when combined with industrial-level static filters, OPUS further improves pre-training efficiency, even with lower-quality data. Furthermore, in continued pre-training of Qwen3-8B-Base on SciencePedia, OPUS achieves superior performance using only 0.5B tokens compared to full training with 3B tokens, demonstrating significant data efficiency gains in specialized domains.