Late-to-Early Training: LET LLMs Learn Earlier, So Faster and Better
作者: Ji Zhao, Yufei Gu, Shitong Shao, Xun Zhou, Liang Xiang, Zeke Xie
分类: cs.CL, cs.LG
发布日期: 2026-02-05
💡 一句话要点
提出LET:利用小模型知识加速大语言模型训练,提升性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 预训练 知识蒸馏 模型加速 迁移学习
📋 核心要点
- 现有大语言模型预训练计算成本高昂,阻碍了快速发展,如何高效利用现有小模型加速大模型训练是一个挑战。
- LET范式利用预训练小模型的后期层表示,指导大模型早期层的训练,使大模型更早学习到后期知识。
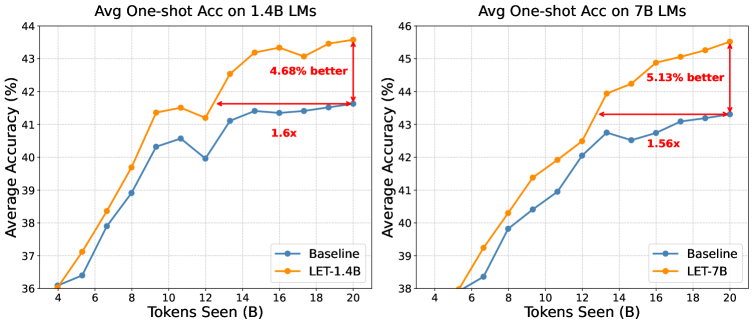
- 实验表明,LET能显著加速训练收敛,提升语言建模能力和下游任务性能,在1.4B模型上可加速1.6倍,精度提升5%。
📝 摘要(中文)
随着大语言模型(LLMs)通过扩展模型和数据规模取得了显著的经验性成功,预训练变得越来越重要,但计算成本也越来越高,阻碍了快速发展。尽管已经有许多以巨大的计算成本开发的预训练LLM,但一个根本性的现实问题仍未得到充分探索:我们能否利用现有的小型预训练模型来加速大型模型的训练?在本文中,我们提出了一种“由晚及早训练”(Late-to-Early Training,LET)范式,使LLM能够在更早的步骤和更早的层中显式地学习后期的知识。核心思想是在早期训练期间,使用预训练模型(即后期训练阶段)的后期层的表示来指导LLM的早期层。我们确定了驱动LET有效性的两个关键机制:由晚及早的步骤学习和由晚及早的层学习。这些机制显著加速了训练收敛,同时稳健地增强了语言建模能力和下游任务性能,从而以更快的速度和卓越的性能实现训练。在1.4B和7B参数模型上的大量实验证明了LET的效率和有效性。值得注意的是,当在Pile数据集上训练一个1.4B LLM时,与标准训练相比,我们的方法实现了高达1.6倍的加速,并在下游任务准确率方面提高了近5%,即使使用参数比目标模型少10倍的预训练模型。
🔬 方法详解
问题定义:论文旨在解决大语言模型预训练计算成本高昂的问题。现有方法通常从头开始训练大型模型,计算资源消耗巨大,训练周期长。如何有效利用已有的、计算成本较低的小型预训练模型来加速大型模型的训练,是一个亟待解决的问题。
核心思路:论文的核心思路是“由晚及早训练”(Late-to-Early Training,LET)。该方法借鉴了知识蒸馏的思想,但不是直接将小模型的知识迁移到大模型,而是利用小模型在训练后期学到的知识(即小模型后期层的表示),来指导大模型在训练早期阶段的学习。这样做的目的是让大模型更早地接触到训练后期的知识,从而加速训练过程并提升性能。
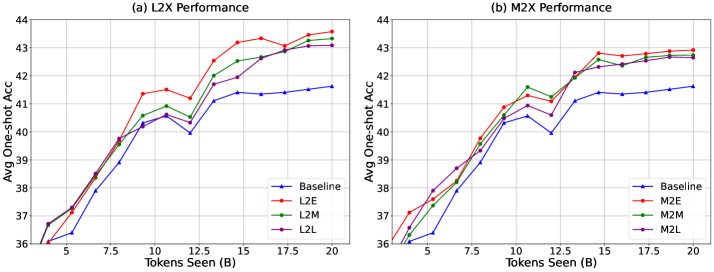
技术框架:LET的整体框架如下:首先,有一个预训练好的小型语言模型(Teacher Model)。然后,在训练目标大型语言模型(Student Model)时,在训练的早期阶段,使用Teacher Model的后期层(Late Layers)的表示作为指导信号,来训练Student Model的早期层(Early Layers)。随着训练的进行,逐渐减少Teacher Model的指导作用,最终Student Model完全自主学习。这个过程包含两个关键机制:Late-to-Early-Step Learning(在训练的早期阶段使用Teacher Model的指导)和Late-to-Early-Layer Learning(使用Teacher Model的后期层来指导Student Model的早期层)。
关键创新:LET的关键创新在于其“由晚及早”的学习范式。与传统的知识蒸馏方法不同,LET不是直接模仿小模型的输出,而是利用小模型在训练后期学到的知识表示来指导大模型的早期训练。这种方法能够更有效地利用小模型的知识,加速大模型的训练过程,并提升模型的性能。此外,LET还提出了Late-to-Early-Step Learning和Late-to-Early-Layer Learning两个关键机制,进一步提升了训练效果。
关键设计:LET的关键设计包括:1) 选择合适的Teacher Model的后期层作为指导信号。论文中具体选择哪些层的信息未知。2) 设计合适的损失函数来衡量Student Model的早期层与Teacher Model的后期层之间的差异。损失函数的具体形式未知。3) 确定合适的Teacher Model指导的衰减策略,即随着训练的进行,如何逐渐减少Teacher Model的指导作用。衰减策略的具体形式未知。
🖼️ 关键图片

📊 实验亮点
实验结果表明,在Pile数据集上训练一个1.4B参数的LLM时,LET方法相比标准训练,能够实现高达1.6倍的加速,并在下游任务准确率方面提升近5%。即使使用的预训练模型参数量比目标模型少10倍,LET依然能够取得显著的性能提升,证明了其高效性和有效性。
🎯 应用场景
LET方法可广泛应用于大语言模型的预训练加速,降低训练成本,缩短开发周期。该方法尤其适用于资源有限的研究机构或个人开发者,他们可以利用已有的较小模型,快速训练出性能优越的大型模型。此外,LET还可以应用于模型压缩和知识迁移等领域,具有重要的实际应用价值和广阔的发展前景。
📄 摘要(原文)
As Large Language Models (LLMs) achieve remarkable empirical success through scaling model and data size, pretraining has become increasingly critical yet computationally prohibitive, hindering rapid development. Despite the availability of numerous pretrained LLMs developed at significant computational expense, a fundamental real-world question remains underexplored: \textit{Can we leverage existing small pretrained models to accelerate the training of larger models?} In this paper, we propose a Late-to-Early Training (LET) paradigm that enables LLMs to explicitly learn later knowledge in earlier steps and earlier layers. The core idea is to guide the early layers of an LLM during early training using representations from the late layers of a pretrained (i.e. late training phase) model. We identify two key mechanisms that drive LET's effectiveness: late-to-early-step learning and late-to-early-layer learning. These mechanisms significantly accelerate training convergence while robustly enhancing both language modeling capabilities and downstream task performance, enabling faster training with superior performance. Extensive experiments on 1.4B and 7B parameter models demonstrate LET's efficiency and effectiveness. Notably, when training a 1.4B LLM on the Pile dataset, our method achieves up to 1.6$\times$ speedup with nearly 5\% improvement in downstream task accuracy compared to standard training, even when using a pretrained model with 10$\times$ fewer parameters than the target model.