Cross-Lingual Empirical Evaluation of Large Language Models for Arabic Medical Tasks
作者: Chaimae Abouzahir, Congbo Ma, Nizar Habash, Farah E. Shamout
分类: cs.CL, cs.LG
发布日期: 2026-02-05
备注: Accepted to HeaLing-EACL 2026
💡 一句话要点
跨语言评估大型语言模型在阿拉伯语医疗任务中的表现差距
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 跨语言评估 阿拉伯语 医学问答 低资源语言
📋 核心要点
- 现有大型语言模型在医疗应用中表现出色,但主要集中于英语,对其他语言支持不足。
- 该研究对阿拉伯语和英语的医学问答任务进行了跨语言评估,揭示了语言差异导致的性能差距。
- 研究发现阿拉伯语医学文本存在结构性碎片化问题,模型置信度与正确性相关性低。
📝 摘要(中文)
近年来,大型语言模型(LLMs)已广泛应用于医疗领域,如临床决策支持、医学教育和医学问答。然而,这些模型通常以英语为中心,限制了它们在语言多样化社区中的鲁棒性和可靠性。最近的研究强调了低资源语言在各种医疗任务中的性能差异,但其根本原因仍未得到充分理解。在本研究中,我们对LLM在阿拉伯语和英语医学问答方面的性能进行了跨语言实证分析。我们的研究结果揭示了一种持续存在的、由语言驱动的性能差距,并且随着任务复杂性的增加而加剧。分词分析揭示了阿拉伯语医学文本中的结构性碎片化,而可靠性分析表明,模型报告的置信度和解释与正确性之间的相关性有限。总之,这些发现强调了在LLM的医疗任务中,需要采用语言感知的模型设计和评估策略。
🔬 方法详解
问题定义:论文旨在解决大型语言模型在处理非英语医疗文本,特别是阿拉伯语医疗文本时,性能显著下降的问题。现有方法主要以英语为中心进行训练和评估,忽略了不同语言的结构和语义差异,导致模型在处理阿拉伯语等低资源语言时表现不佳。这种性能差距限制了LLM在更广泛的语言社区中的应用,尤其是在医疗健康领域。
核心思路:论文的核心思路是通过跨语言的实证分析,量化LLM在阿拉伯语和英语医学问答任务中的性能差异,并深入探究造成这种差异的根本原因。通过分析分词结果和模型置信度,揭示阿拉伯语医学文本的结构性碎片化问题以及模型可靠性问题,从而为未来开发更具语言感知能力的LLM提供指导。
技术框架:该研究的技术框架主要包括以下几个步骤:1) 选择合适的LLM模型,例如预训练的Transformer模型;2) 构建或收集阿拉伯语和英语的医学问答数据集;3) 使用相同的模型和训练方法,分别在阿拉伯语和英语数据集上进行训练和评估;4) 对比模型在两种语言上的性能指标,如准确率、召回率等;5) 进行分词分析,评估不同语言文本的结构性差异;6) 分析模型输出的置信度和解释,评估模型的可靠性。
关键创新:该研究的关键创新在于:1) 首次对LLM在阿拉伯语医学问答任务中的性能进行了系统的跨语言评估,揭示了显著的性能差距;2) 通过分词分析,发现了阿拉伯语医学文本的结构性碎片化问题,为理解性能差距提供了新的视角;3) 评估了模型置信度和解释的可靠性,发现模型在处理阿拉伯语时,置信度与正确性之间的相关性较低。
关键设计:研究中可能涉及的关键设计包括:1) 数据集的选择和预处理,需要确保数据集的质量和平衡性;2) 分词器的选择,需要考虑不同分词器对阿拉伯语文本的处理能力;3) 模型评估指标的选择,需要综合考虑准确率、召回率等多个指标;4) 置信度评估方法的设计,需要选择合适的指标来衡量模型置信度的可靠性。
🖼️ 关键图片
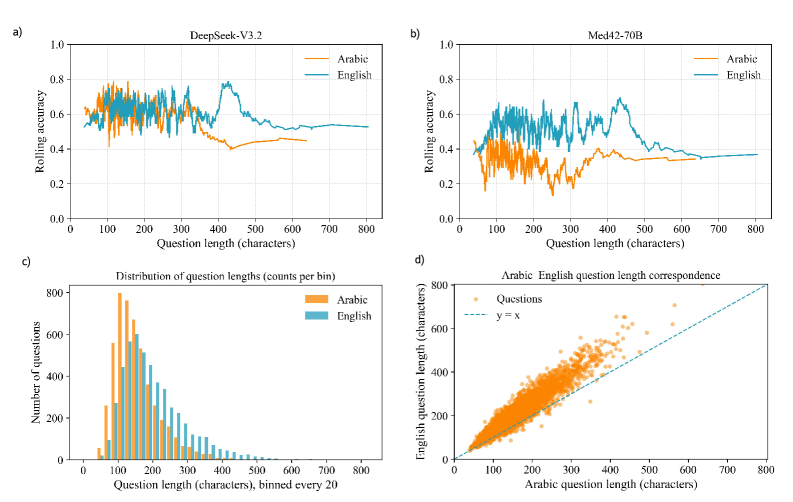
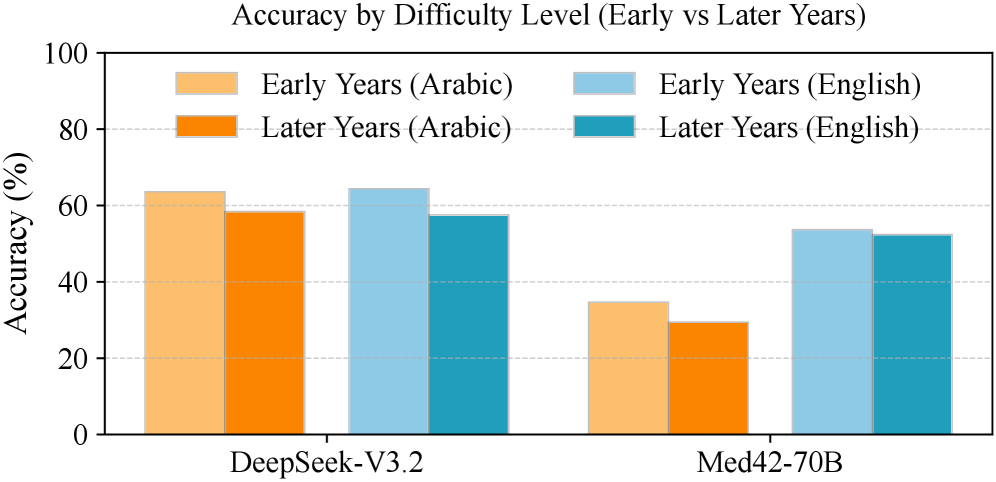

📊 实验亮点
研究结果表明,LLM在阿拉伯语医学问答任务中的性能明显低于英语,揭示了语言驱动的性能差距。分词分析显示阿拉伯语医学文本存在结构性碎片化,模型置信度与正确性相关性低。这些发现强调了在医疗LLM中进行语言感知设计和评估的必要性。
🎯 应用场景
该研究成果可应用于提升多语言医疗健康服务的质量和可及性。通过开发更具语言感知能力的LLM,可以为不同语言背景的患者提供更准确、可靠的医疗信息和决策支持。此外,该研究也为开发其他低资源语言的LLM提供了借鉴,有助于推动人工智能技术在更广泛的语言社区中的应用。
📄 摘要(原文)
In recent years, Large Language Models (LLMs) have become widely used in medical applications, such as clinical decision support, medical education, and medical question answering. Yet, these models are often English-centric, limiting their robustness and reliability for linguistically diverse communities. Recent work has highlighted discrepancies in performance in low-resource languages for various medical tasks, but the underlying causes remain poorly understood. In this study, we conduct a cross-lingual empirical analysis of LLM performance on Arabic and English medical question and answering. Our findings reveal a persistent language-driven performance gap that intensifies with increasing task complexity. Tokenization analysis exposes structural fragmentation in Arabic medical text, while reliability analysis suggests that model-reported confidence and explanations exhibit limited correlation with correctness. Together, these findings underscore the need for language-aware design and evaluation strategies in LLMs for medical tasks.