PACE: Defying the Scaling Hypothesis of Exploration in Iterative Alignment for Mathematical Reasoning
作者: Jun Rao, Zixiong Yu, Xuebo Liu, Guhan Chen, Jing Li, Jiansheng Wei, Xiaojun Meng, Min Zhang
分类: cs.CL
发布日期: 2026-02-05
💡 一句话要点
PACE:数学推理迭代对齐中,挑战探索规模假设,提升效率与鲁棒性
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 数学推理 迭代对齐 直接偏好优化 探索策略 生成模型
📋 核心要点
- 现有DPO方法依赖大规模采样寻找优质推理轨迹,但计算成本高昂且易受噪声干扰。
- PACE提出一种基于生成模型的纠正策略,从失败探索中合成高质量偏好对,降低探索成本。
- 实验表明,PACE在数学推理任务上,以更少的计算资源超越了DPO-R1,并展现出更强的鲁棒性。
📝 摘要(中文)
迭代直接偏好优化(Iterative Direct Preference Optimization)已成为对齐大型语言模型以进行推理任务的最先进范例。标准实现(DPO-R1)依赖于Best-of-N采样(例如,N≥8)来从分布尾部挖掘黄金轨迹。本文挑战了这种规模假设,并揭示了一种违反直觉的现象:在数学推理中,激进的探索会产生递减的回报,甚至导致灾难性的策略崩溃。我们从理论上证明,扩大N会放大验证器噪声并导致有害的分布偏移。为了解决这个问题,我们引入了PACE(通过纠正性探索的近端对齐),它用基于生成的纠正策略取代了蛮力挖掘。PACE以最小的预算(2<N<3)运行,从失败的探索中合成高保真偏好对。经验评估表明,PACE优于DPO-R1(N=16),同时仅使用约1/5的计算量,证明了其对奖励黑客和标签噪声的卓越鲁棒性。
🔬 方法详解
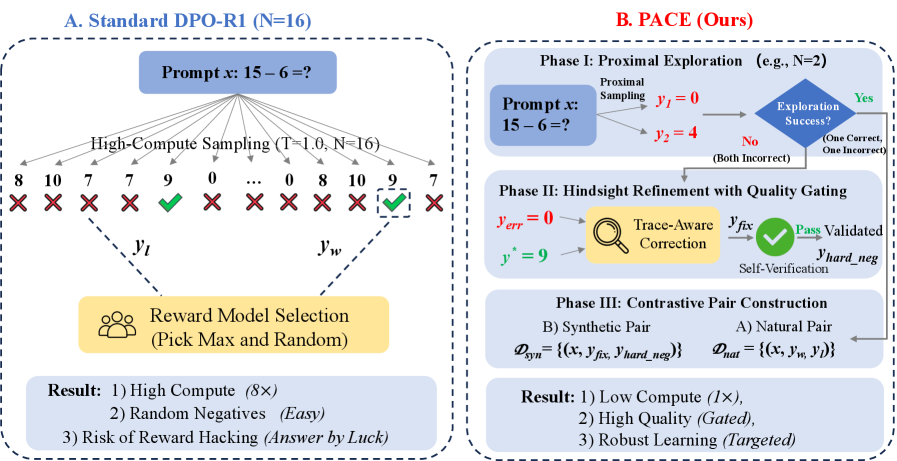
问题定义:现有基于DPO的数学推理模型依赖于Best-of-N采样策略,通过增加采样数量N来提高找到高质量推理轨迹的概率。然而,这种方法计算成本高昂,并且随着N的增大,验证器噪声也会被放大,导致模型学习到错误的偏好,最终导致策略崩溃。因此,如何高效且鲁棒地从探索中学习高质量的推理策略是一个关键问题。
核心思路:PACE的核心思路是利用生成模型从失败的探索中学习,而不是简单地增加采样数量。具体来说,PACE通过分析失败的推理轨迹,生成更正后的轨迹,并利用这些更正后的轨迹来构建高质量的偏好对。这种方法可以在较低的计算成本下,更有效地利用探索数据,并减少验证器噪声的影响。
技术框架:PACE的整体框架包括以下几个主要步骤:1) 使用一个小型采样集(2<N<3)进行探索,生成初始的推理轨迹;2) 对生成的轨迹进行评估,识别失败的轨迹;3) 使用生成模型对失败的轨迹进行纠正,生成更正后的轨迹;4) 将原始轨迹和更正后的轨迹组成偏好对,用于训练DPO模型。
关键创新:PACE的关键创新在于使用生成模型进行纠正性探索,而不是依赖于大规模采样。这种方法可以更有效地利用探索数据,并减少验证器噪声的影响。此外,PACE还提出了一种新的偏好对构建方法,可以更好地利用纠正后的轨迹来训练DPO模型。
关键设计:PACE的关键设计包括:1) 使用一个小型采样集(2<N<3)进行探索,以降低计算成本;2) 使用一个预训练的语言模型作为生成模型,用于纠正失败的轨迹;3) 使用一种基于奖励的偏好对构建方法,将原始轨迹和更正后的轨迹组成偏好对。具体的损失函数和网络结构细节在论文中有详细描述。
🖼️ 关键图片


📊 实验亮点
实验结果表明,PACE在数学推理任务上显著优于DPO-R1(N=16),同时仅使用约1/5的计算资源。具体来说,PACE在MATH数据集上取得了更高的准确率,并且对奖励黑客和标签噪声表现出更强的鲁棒性。这些结果验证了PACE方法的有效性和优越性。
🎯 应用场景
PACE方法可应用于各种需要复杂推理能力的场景,例如数学问题求解、代码生成、逻辑推理等。通过提高模型在探索过程中的效率和鲁棒性,PACE可以帮助开发更强大、更可靠的AI系统,并降低训练成本。该方法还有潜力应用于其他强化学习领域,提升智能体的学习效率。
📄 摘要(原文)
Iterative Direct Preference Optimization has emerged as the state-of-the-art paradigm for aligning Large Language Models on reasoning tasks. Standard implementations (DPO-R1) rely on Best-of-N sampling (e.g., $N \ge 8$) to mine golden trajectories from the distribution tail. In this paper, we challenge this scaling hypothesis and reveal a counter-intuitive phenomenon: in mathematical reasoning, aggressive exploration yields diminishing returns and even catastrophic policy collapse. We theoretically demonstrate that scaling $N$ amplifies verifier noise and induces detrimental distribution shifts. To resolve this, we introduce \textbf{PACE} (Proximal Alignment via Corrective Exploration), which replaces brute-force mining with a generation-based corrective strategy. Operating with a minimal budget ($2<N<3$), PACE synthesizes high-fidelity preference pairs from failed explorations. Empirical evaluations show that PACE outperforms DPO-R1 $(N=16)$ while using only about $1/5$ of the compute, demonstrating superior robustness against reward hacking and label noise.