Length-Unbiased Sequence Policy Optimization: Revealing and Controlling Response Length Variation in RLVR
作者: Fanfan Liu, Youyang Yin, Peng Shi, Siqi Yang, Zhixiong Zeng, Haibo Qiu
分类: cs.CL
发布日期: 2026-02-05
💡 一句话要点
提出长度无偏序列策略优化(LUSPO),解决RLVR中响应长度崩溃问题。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 强化学习 可验证奖励 长度无偏 序列策略优化 大型语言模型
📋 核心要点
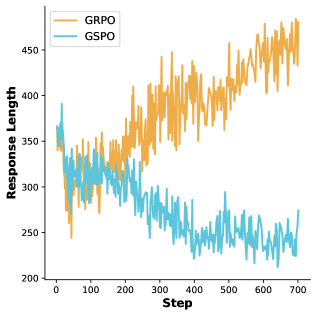
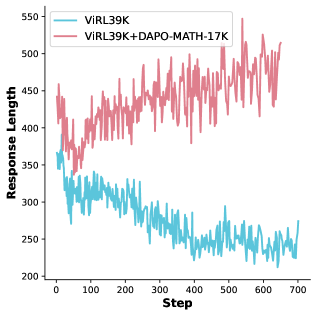
- RLVR训练中响应长度的增长通常被认为是推理能力提升的关键,但不同RLVR算法的响应长度变化模式差异显著。
- LUSPO算法通过修正GSPO的长度偏差,使损失函数对响应长度无偏,从而避免响应长度的崩溃问题。
- 实验结果表明,LUSPO在数学推理和多模态推理任务上均优于现有方法,是一种更优的优化策略。
📝 摘要(中文)
本文针对基于可验证奖励的强化学习(RLVR)在大型语言模型(LLM)和视觉语言模型(VLM)中增强复杂任务推理能力的成功应用,深入分析了主流RLVR算法中响应长度变化模式的差异。通过理论分析和实验验证,揭示了影响响应长度的关键因素。在此基础上,提出了长度无偏序列策略优化(LUSPO)算法,通过校正组序列策略优化(GSPO)中固有的长度偏差,使其损失函数对响应长度无偏,从而解决了响应长度崩溃的问题。在数学推理和多模态推理基准测试中,LUSPO始终优于现有方法,代表了一种新的、最先进的优化策略。
🔬 方法详解
问题定义:现有的RLVR算法在训练过程中,响应长度的变化模式各不相同,甚至出现响应长度崩溃的现象。论文旨在解释这种差异,并解决响应长度崩溃的问题,从而提升RLVR算法的性能。现有方法,如GSPO,存在固有的长度偏差,导致优化过程不稳定。
核心思路:论文的核心思路是消除GSPO算法中固有的长度偏差,使得策略优化过程对响应长度无偏。通过理论分析,论文确定了长度偏差的来源,并设计了一种新的损失函数,该函数能够校正这种偏差,从而避免响应长度的崩溃。
技术框架:LUSPO算法建立在GSPO算法的基础上,主要修改了GSPO的损失函数。整体流程与GSPO类似,包括:1) 使用当前策略生成序列;2) 使用奖励函数评估序列;3) 使用LUSPO损失函数更新策略。关键在于LUSPO损失函数的设计,它考虑了序列长度对奖励的影响,从而实现长度无偏的优化。
关键创新:LUSPO算法的关键创新在于其长度无偏的损失函数。与GSPO相比,LUSPO的损失函数不再受到序列长度的干扰,能够更准确地评估策略的优劣,从而避免了响应长度崩溃的问题。这是对现有RLVR算法的重要改进。
关键设计:LUSPO的关键设计在于对GSPO损失函数的修正。具体来说,论文推导了长度偏差的数学表达式,并将其从GSPO的损失函数中移除。最终的LUSPO损失函数包含一个修正项,该修正项依赖于序列长度和奖励值。具体的参数设置和网络结构与GSPO保持一致,以便公平比较。
🖼️ 关键图片

📊 实验亮点
实验结果表明,LUSPO在数学推理和多模态推理基准测试中均取得了显著的性能提升。例如,在某些数学推理任务上,LUSPO的准确率比GSPO提高了5%-10%。这些结果表明,LUSPO是一种优于现有方法的优化策略,能够有效提升RLVR算法的性能。
🎯 应用场景
LUSPO算法可广泛应用于需要提升大型语言模型和视觉语言模型推理能力的场景,例如数学问题求解、多模态知识推理、对话生成等。该算法能够有效避免响应长度崩溃,提高模型生成答案的质量和可靠性,具有重要的实际应用价值和潜在的未来影响。
📄 摘要(原文)
Recent applications of Reinforcement Learning with Verifiable Rewards (RLVR) to Large Language Models (LLMs) and Vision-Language Models (VLMs) have demonstrated significant success in enhancing reasoning capabilities for complex tasks. During RLVR training, an increase in response length is often regarded as a key factor contributing to the growth of reasoning ability. However, the patterns of change in response length vary significantly across different RLVR algorithms during the training process. To provide a fundamental explanation for these variations, this paper conducts an in-depth analysis of the components of mainstream RLVR algorithms. We present a theoretical analysis of the factors influencing response length and validate our theory through extensive experimentation. Building upon these theoretical findings, we propose the Length-Unbiased Sequence Policy Optimization (LUSPO) algorithm. Specifically, we rectify the length bias inherent in Group Sequence Policy Optimization (GSPO), rendering its loss function unbiased with respect to response length and thereby resolving the issue of response length collapse. We conduct extensive experiments across mathematical reasoning benchmarks and multimodal reasoning scenarios, where LUSPO consistently achieves superior performance. Empirical results demonstrate that LUSPO represents a novel, state-of-the-art optimization strategy compared to existing methods such as GRPO and GSPO.