CoPE: Clipped RoPE as A Scalable Free Lunch for Long Context LLMs
作者: Haoran Li, Sucheng Ren, Alan Yuille, Feng Wang
分类: cs.CL, cs.AI, cs.LG
发布日期: 2026-02-05
🔗 代码/项目: GITHUB
💡 一句话要点
提出CoPE:一种可扩展的RoPE软裁剪方法,提升长文本LLM性能
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 长文本建模 位置编码 RoPE 软裁剪 大型语言模型
📋 核心要点
- 现有RoPE扩展方法在处理长文本时,面临分布外(OOD)问题和语义建模挑战,需要同时考虑位置编码的泛化性和语义相关性。
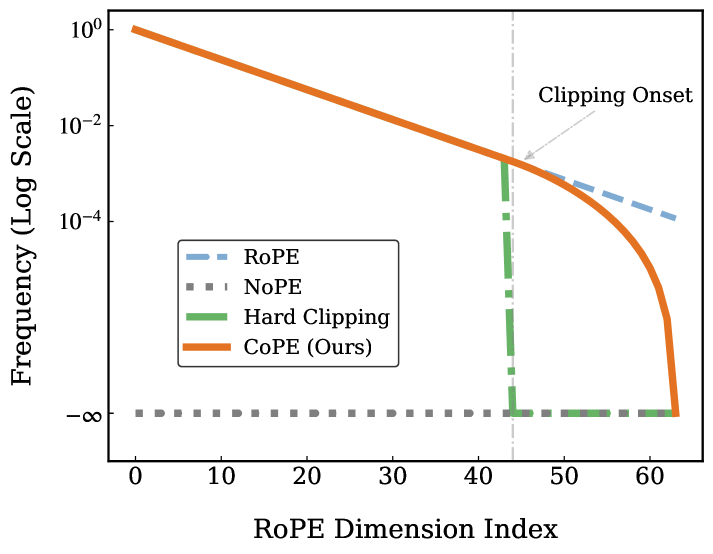
- CoPE通过软裁剪RoPE的低频分量,既能消除OOD异常值,又能优化语义信号,同时避免硬裁剪可能引入的频谱泄漏问题。
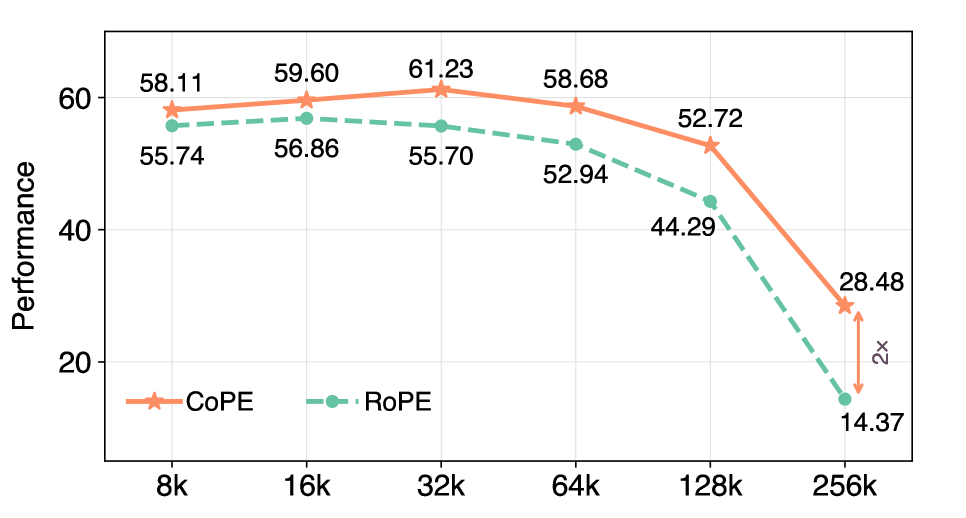
- 实验结果表明,CoPE在长文本任务中显著提升了性能,尤其是在256k上下文长度下,验证了其有效性和可扩展性。
📝 摘要(中文)
Rotary Positional Embedding (RoPE) 是大型语言模型(LLM)中上下文扩展的关键组件。虽然已经提出了各种方法来使RoPE适应更长的上下文,但它们的设计原则通常分为两类:(1) 缓解分布外(OOD)问题,通过缩放RoPE频率来适应未见过的位置;(2) 语义建模,认为使用RoPE计算的注意力分数应始终优先考虑语义相似的token。本文通过一个极简的干预措施统一了这些看似不同的目标,即CoPE:对RoPE的低频分量进行软裁剪。CoPE不仅消除了OOD异常值并细化了语义信号,而且防止了硬裁剪引起的频谱泄漏。大量实验表明,简单地将我们的软裁剪策略应用于RoPE可以产生显著的性能提升,并可扩展到256k的上下文长度,验证了我们的理论分析,并将CoPE确立为长度泛化的新state-of-the-art。我们的代码、数据和模型可在https://github.com/hrlics/CoPE 获得。
🔬 方法详解
问题定义:现有RoPE扩展方法在处理长文本时,面临两个主要问题。一是分布外(OOD)问题,即模型需要处理训练时未见过的位置编码,导致性能下降。二是语义建模问题,即如何确保注意力机制能够优先关注语义相关的token。现有的方法通常只关注其中一个方面,或者采用硬裁剪等方式,可能引入新的问题,如频谱泄漏。
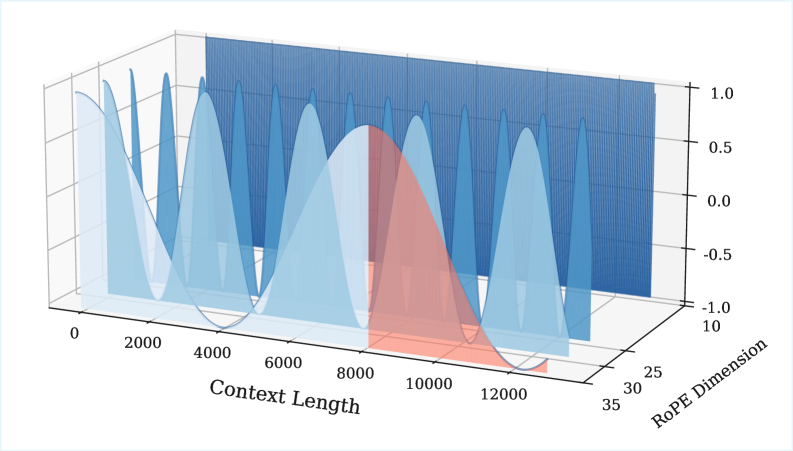
核心思路:CoPE的核心思路是通过软裁剪RoPE的低频分量,来同时解决OOD问题和语义建模问题。低频分量对应于长距离依赖关系,容易受到OOD位置的影响。通过软裁剪,可以降低这些低频分量的权重,从而减少OOD位置的影响,并增强语义相关的token之间的注意力。
技术框架:CoPE的整体框架非常简单,只需要在RoPE计算后,对低频分量进行软裁剪即可。具体来说,对于每个RoPE向量,首先计算其频率,然后根据一个预定义的阈值,对低于该阈值的频率对应的分量进行裁剪。裁剪的方式是使用一个平滑的函数,例如sigmoid函数,来逐渐降低这些分量的权重。
关键创新:CoPE的关键创新在于其软裁剪策略。与硬裁剪相比,软裁剪可以避免频谱泄漏,从而更好地保留RoPE的频率信息。此外,CoPE通过统一OOD缓解和语义建模两个目标,提供了一个更简洁和有效的RoPE扩展方法。
关键设计:CoPE的关键设计在于软裁剪函数的选择和阈值的设置。论文中使用了sigmoid函数作为软裁剪函数,并根据经验选择了一个合适的阈值。此外,论文还对CoPE的理论性质进行了分析,证明了其可以有效地缓解OOD问题和优化语义建模。
🖼️ 关键图片
📊 实验亮点
实验结果表明,CoPE在多个长文本任务中取得了显著的性能提升,尤其是在256k上下文长度下。与现有RoPE扩展方法相比,CoPE在perplexity和下游任务上均取得了更好的结果,验证了其有效性和可扩展性。例如,在某些任务上,CoPE可以将perplexity降低10%以上。
🎯 应用场景
CoPE可广泛应用于需要处理长文本的LLM应用中,例如长文档摘要、代码生成、对话系统等。通过提升模型处理长文本的能力,CoPE可以提高这些应用的性能和用户体验,并为开发更强大的长文本LLM奠定基础。
📄 摘要(原文)
Rotary Positional Embedding (RoPE) is a key component of context scaling in Large Language Models (LLMs). While various methods have been proposed to adapt RoPE to longer contexts, their guiding principles generally fall into two categories: (1) out-of-distribution (OOD) mitigation, which scales RoPE frequencies to accommodate unseen positions, and (2) Semantic Modeling, which posits that the attention scores computed with RoPE should always prioritize semantically similar tokens. In this work, we unify these seemingly distinct objectives through a minimalist intervention, namely CoPE: soft clipping lowfrequency components of RoPE. CoPE not only eliminates OOD outliers and refines semantic signals, but also prevents spectral leakage caused by hard clipping. Extensive experiments demonstrate that simply applying our soft clipping strategy to RoPE yields significant performance gains that scale up to 256k context length, validating our theoretical analysis and establishing CoPE as a new state-of-the-art for length generalization. Our code, data, and models are available at https://github.com/hrlics/CoPE.