FedMosaic: Federated Retrieval-Augmented Generation via Parametric Adapters
作者: Zhilin Liang, Yuxiang Wang, Zimu Zhou, Hainan Zhang, Boyi Liu, Yongxin Tong
分类: cs.CL
发布日期: 2026-02-05
备注: 11 pages
💡 一句话要点
FedMosaic:基于参数化适配器的联邦检索增强生成框架,解决隐私场景下的知识孤岛问题。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 联邦学习 检索增强生成 参数化适配器 知识增强 隐私保护
📋 核心要点
- 现有RAG方法在隐私敏感场景中面临挑战,因为它们通常需要集中式语料库或直接传输原始文档,这违反了数据隐私保护的要求。
- FedMosaic通过引入参数化适配器,将文档编码为轻量级模型参数,避免了原始文本的传输,并采用多文档适配器和选择性聚合来降低开销。
- 实验结果表明,FedMosaic在准确率上优于现有方法,同时显著降低了存储和通信成本,为隐私保护的联邦RAG提供了一种有效的解决方案。
📝 摘要(中文)
检索增强生成(RAG)通过将生成过程与外部知识相结合,增强大型语言模型(LLM)的真实性并减少幻觉。然而,大多数部署都假设存在一个中心化的语料库,这在注重隐私的领域(知识仍然孤立存在)中是不可行的。这促使了联邦RAG(FedRAG)的出现,其中中央LLM服务器与分布式数据孤岛协作,而无需共享原始文档。上下文RAG通过传输逐字文档违反了这一要求,而参数化RAG将文档编码为轻量级适配器,这些适配器在推理时与冻结的LLM合并,从而避免了原始文本的交换。我们采用了参数化方法,但面临着由FedRAG引起的两个独特的挑战:每个文档适配器带来的高存储和通信成本,以及不加选择地合并多个适配器造成的破坏性聚合。我们提出了FedMosaic,这是第一个基于参数化适配器的联邦RAG框架。FedMosaic将语义相关的文档聚类到多文档适配器中,并使用文档特定的掩码来降低开销,同时保持特异性,并执行选择性适配器聚合,仅组合相关对齐且非冲突的适配器。实验表明,FedMosaic在四个类别中实现了比最先进方法平均高10.9%的准确率,同时降低了78.8%到86.3%的存储成本和91.4%的通信成本,并且从不共享原始文档。
🔬 方法详解
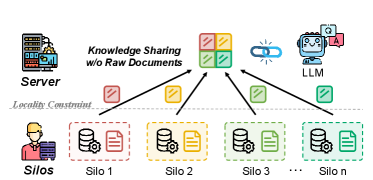
问题定义:论文旨在解决联邦学习场景下,如何安全有效地利用分布式知识库增强大型语言模型(LLM)的问题。现有方法,如上下文RAG,需要传输原始文档,侵犯了数据隐私。参数化RAG虽然避免了原始文本传输,但每个文档一个适配器导致存储和通信开销巨大,且盲目聚合适配器会产生冲突,降低性能。
核心思路:FedMosaic的核心思路是利用参数化适配器在保护隐私的前提下实现知识增强,并通过多文档适配器和选择性聚合来降低开销和避免冲突。它将语义相关的文档聚类到一起,形成一个适配器,并只聚合那些相关且不冲突的适配器。
技术框架:FedMosaic的整体框架包含以下几个主要阶段:1) 文档聚类:将语义相关的文档聚类成组。2) 适配器生成:为每个文档组生成一个多文档适配器,并使用文档特定的掩码来区分不同文档的信息。3) 选择性聚合:根据查询的相关性和适配器之间的冲突程度,选择性地聚合适配器。4) LLM推理:将聚合后的适配器与冻结的LLM合并,进行推理。
关键创新:FedMosaic的关键创新在于:1) 多文档适配器:将多个语义相关的文档压缩到一个适配器中,显著降低了存储和通信开销。2) 选择性聚合:通过评估适配器与查询的相关性以及适配器之间的冲突程度,只聚合那些有益的适配器,避免了盲目聚合带来的性能下降。
关键设计:文档聚类采用语义相似度度量,例如使用预训练语言模型计算文档的嵌入向量,然后进行聚类。适配器生成使用轻量级的神经网络结构,例如MLP或Transformer层。选择性聚合通过计算查询与适配器的相关性得分,以及适配器之间的冲突得分来实现。相关性得分可以使用余弦相似度等方法计算,冲突得分可以使用互信息等方法计算。
🖼️ 关键图片


📊 实验亮点
实验结果表明,FedMosaic在四个类别(具体类别未知)中,相比最先进的方法,平均准确率提升了10.9%。同时,FedMosaic显著降低了存储和通信成本,分别降低了78.8%到86.3%和91.4%。这些结果表明,FedMosaic在保证隐私的前提下,能够有效地利用分布式知识库增强LLM的性能。
🎯 应用场景
FedMosaic适用于需要保护用户隐私的联邦学习场景,例如医疗健康、金融服务等领域。它可以帮助这些领域利用分布在不同机构或用户手中的知识库,增强LLM的性能,同时避免数据泄露的风险。该研究的成果有助于推动联邦学习在实际应用中的落地,并为构建更加安全可靠的AI系统提供技术支持。
📄 摘要(原文)
Retrieval-Augmented Generation (RAG) enhances Large Language Models (LLMs) by grounding generation in external knowledge to improve factuality and reduce hallucinations. Yet most deployments assume a centralized corpus, which is infeasible in privacy aware domains where knowledge remains siloed. This motivates federated RAG (FedRAG), where a central LLM server collaborates with distributed silos without sharing raw documents. In context RAG violates this requirement by transmitting verbatim documents, whereas parametric RAG encodes documents into lightweight adapters that merge with a frozen LLM at inference, avoiding raw-text exchange. We adopt the parametric approach but face two unique challenges induced by FedRAG: high storage and communication from per-document adapters, and destructive aggregation caused by indiscriminately merging multiple adapters. We present FedMosaic, the first federated RAG framework built on parametric adapters. FedMosaic clusters semantically related documents into multi-document adapters with document-specific masks to reduce overhead while preserving specificity, and performs selective adapter aggregation to combine only relevance-aligned, nonconflicting adapters. Experiments show that FedMosaic achieves an average 10.9% higher accuracy than state-of-the-art methods in four categories, while lowering storage costs by 78.8% to 86.3% and communication costs by 91.4%, and never sharing raw documents.