Are Open-Weight LLMs Ready for Social Media Moderation? A Comparative Study on Bluesky
作者: Hsuan-Yu Chou, Wajiha Naveed, Shuyan Zhou, Xiaowei Yang
分类: cs.CL, cs.HC, cs.LG, cs.SI
发布日期: 2026-02-05
💡 一句话要点
评估开源LLM在社交媒体审核中的应用:以Bluesky平台为例
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 社交媒体审核 大型语言模型 开源LLM 有害内容检测 Bluesky 内容审核系统 隐私保护 性能评估
📋 核心要点
- 现有社交媒体内容审核依赖专有LLM,但其成本和隐私问题限制了应用。
- 论文评估了开源LLM在Bluesky平台内容审核中的性能,并与专有模型对比。
- 实验表明开源LLM在敏感性和特异性上与专有模型相当,为隐私保护审核提供可能。
📝 摘要(中文)
随着互联网的普及,有害内容日益增多,有效的内容审核需求也随之增长。研究表明,大型语言模型(LLM)可有效用于社交媒体审核任务,包括有害内容检测。虽然专有LLM已被证明在零样本学习中优于传统机器学习模型,但开源LLM的开箱即用能力仍是一个悬而未决的问题。受推理LLM最新进展的推动,我们评估了七个最先进的模型:四个专有模型和三个开源模型。通过对Bluesky上的真实帖子、Bluesky审核服务的审核决策以及两位作者的标注进行测试,我们发现开源LLM的敏感性(81%--97%)和特异性(91%--100%)与专有LLM(72%--98%,以及93%--99%)之间存在相当大的重叠。此外,我们的分析表明,对于粗鲁检测,特异性超过敏感性,但对于不容忍和威胁,情况则相反。最后,我们确定了人类审核员和LLM之间的一致性,突出了在平台规模和个性化审核环境中部署LLM的考虑因素。这些发现表明,开源LLM可以支持在消费级硬件上进行保护隐私的审核,并为设计平衡社区价值观与个人用户偏好的审核系统提供了新的方向。
🔬 方法详解
问题定义:论文旨在评估开源大型语言模型(LLM)在社交媒体内容审核任务中的有效性,特别是针对有害内容检测。现有方法主要依赖专有LLM,存在成本高昂、数据隐私风险以及透明度不足等痛点。开源LLM的潜力尚未充分挖掘,其在实际应用中的性能表现需要进一步研究。
核心思路:论文的核心思路是通过对比开源和专有LLM在真实社交媒体数据上的审核表现,评估开源LLM是否具备替代专有LLM的能力。通过分析不同类型有害内容的检测结果,揭示开源LLM的优势和局限性,为未来内容审核系统的设计提供指导。
技术框架:论文采用实证研究方法,主要流程包括:1) 数据收集:从Bluesky平台收集真实帖子数据;2) 人工标注:由两位作者对帖子进行有害内容标注;3) 模型评估:使用七个LLM(四个专有,三个开源)对帖子进行审核,并与人工标注和Bluesky审核服务的决策进行比较;4) 性能分析:计算LLM的敏感性、特异性等指标,分析不同类型有害内容的检测结果。
关键创新:论文的关键创新在于首次系统性地评估了开源LLM在真实社交媒体环境下的内容审核能力。通过对比开源和专有LLM的性能,揭示了开源LLM在隐私保护和成本效益方面的潜力。此外,论文还分析了不同类型有害内容的检测差异,为未来内容审核系统的优化提供了依据。
关键设计:论文的关键设计包括:1) 数据集构建:选择Bluesky平台作为研究对象,保证数据的真实性和代表性;2) 评估指标:采用敏感性和特异性等指标,全面评估LLM的审核性能;3) 模型选择:选取具有代表性的开源和专有LLM,保证评估结果的可靠性;4) 人工标注:由两位作者进行标注,并通过计算inter-rater agreement来保证标注质量。
🖼️ 关键图片
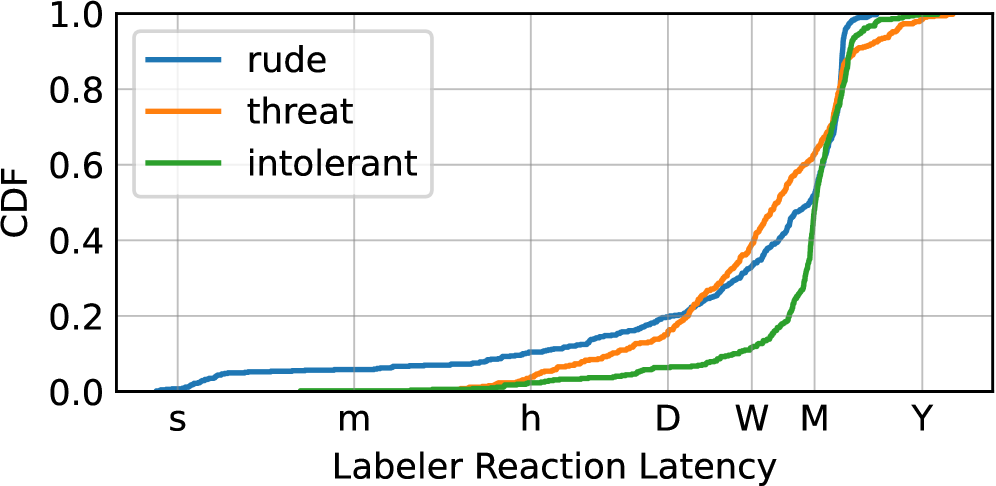


📊 实验亮点
实验结果表明,开源LLM在Bluesky平台上的内容审核性能与专有LLM相当,敏感性达到81%-97%,特异性达到91%-100%。此外,研究还发现不同类型的有害内容(如粗鲁、不容忍和威胁)在检测难度上存在差异,为优化内容审核策略提供了依据。
🎯 应用场景
该研究成果可应用于社交媒体平台的内容审核,特别是对于注重用户隐私和希望降低运营成本的平台。开源LLM的应用能够实现更透明、可控的内容审核流程,并促进社区自治。未来的研究可以探索如何结合开源LLM和个性化用户偏好,构建更灵活、高效的内容审核系统。
📄 摘要(原文)
As internet access expands, so does exposure to harmful content, increasing the need for effective moderation. Research has demonstrated that large language models (LLMs) can be effectively utilized for social media moderation tasks, including harmful content detection. While proprietary LLMs have been shown to zero-shot outperform traditional machine learning models, the out-of-the-box capability of open-weight LLMs remains an open question. Motivated by recent developments of reasoning LLMs, we evaluate seven state-of-the-art models: four proprietary and three open-weight. Testing with real-world posts on Bluesky, moderation decisions by Bluesky Moderation Service, and annotations by two authors, we find a considerable degree of overlap between the sensitivity (81%--97%) and specificity (91%--100%) of the open-weight LLMs and those (72%--98%, and 93%--99%) of the proprietary ones. Additionally, our analysis reveals that specificity exceeds sensitivity for rudeness detection, but the opposite holds for intolerance and threats. Lastly, we identify inter-rater agreement across human moderators and the LLMs, highlighting considerations for deploying LLMs in both platform-scale and personalized moderation contexts. These findings show open-weight LLMs can support privacy-preserving moderation on consumer-grade hardware and suggest new directions for designing moderation systems that balance community values with individual user preferences.