Reinforced Attention Learning
作者: Bangzheng Li, Jianmo Ni, Chen Qu, Ian Miao, Liu Yang, Xingyu Fu, Muhao Chen, Derek Zhiyuan Cheng
分类: cs.CL, cs.CV, cs.LG
发布日期: 2026-02-04
💡 一句话要点
提出强化注意力学习RAL,直接优化多模态大语言模型的内部注意力分布,提升感知能力。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 强化学习 注意力机制 多模态学习 大语言模型 后训练 策略梯度 跨模态对齐 知识蒸馏
📋 核心要点
- 现有方法通过生成冗长理由进行多模态LLM后训练,在感知方面提升有限,甚至可能降低性能。
- RAL通过策略梯度直接优化内部注意力分布,将优化目标从生成内容转移到关注位置,提升信息分配效率。
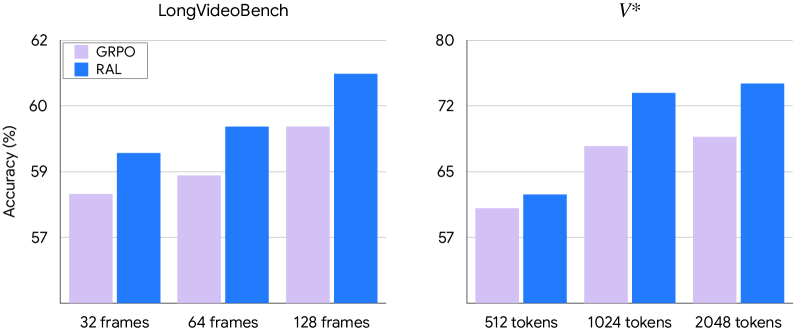
- 实验表明,RAL在图像和视频基准测试中优于GRPO等基线,并且On-Policy注意力蒸馏能实现更强的跨模态对齐。
📝 摘要(中文)
通过强化学习进行后训练已显著提升了大型语言模型(LLMs)的推理能力。然而,将这种范式通过冗长的理由扩展到多模态LLMs(MLLMs)时,对感知的提升有限,甚至可能降低性能。我们提出了强化注意力学习(RAL),这是一个策略梯度框架,它直接优化内部注意力分布,而不是输出token序列。通过将优化从生成什么转移到关注哪里,RAL促进了有效的信息分配,并改进了复杂多模态输入中的基础。在各种图像和视频基准测试上的实验表明,相对于GRPO和其他基线,RAL取得了持续的收益。我们进一步引入了On-Policy注意力蒸馏,表明传递潜在的注意力行为比标准知识蒸馏产生更强的跨模态对齐。我们的结果表明,注意力策略是多模态后训练的一种原则性和通用替代方案。
🔬 方法详解
问题定义:现有的多模态大语言模型(MLLM)后训练方法,例如通过生成冗长的推理链(rationales)来提升模型性能,在感知任务上效果不佳,甚至会降低性能。这是因为直接优化输出token序列,难以有效指导模型关注多模态输入中的关键信息。
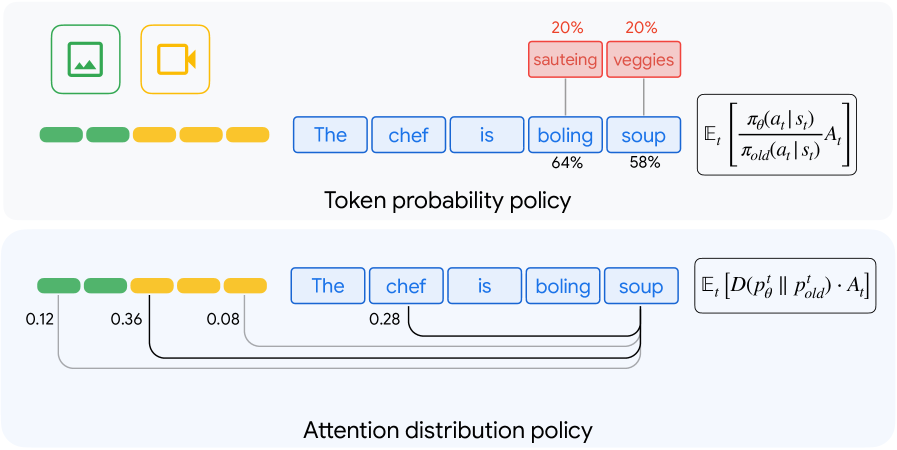
核心思路:RAL的核心思想是直接优化模型的内部注意力分布,而不是优化输出的token序列。通过强化学习,训练一个策略网络来控制模型在不同模态输入上的注意力分配,从而让模型能够更好地关注重要的视觉信息,提升感知能力。这种方法将优化目标从“生成什么”转变为“关注哪里”。
技术框架:RAL的整体框架包括以下几个主要部分:1) 多模态输入编码器:将图像和文本输入编码成特征向量。2) 注意力策略网络:根据编码后的特征,生成注意力权重分布。3) 多模态融合模块:使用注意力权重融合不同模态的特征。4) 奖励函数:根据模型在下游任务上的表现,计算奖励信号。5) 强化学习优化器:使用策略梯度算法优化注意力策略网络。
关键创新:RAL的关键创新在于直接优化内部注意力分布,而不是输出token序列。这使得模型能够更好地关注多模态输入中的关键信息,从而提升感知能力。此外,RAL还提出了On-Policy注意力蒸馏方法,通过传递潜在的注意力行为,实现更强的跨模态对齐。
关键设计:RAL使用策略梯度算法(例如REINFORCE或PPO)来优化注意力策略网络。奖励函数的设计至关重要,通常基于模型在下游任务上的表现(例如分类准确率或生成质量)。注意力策略网络可以使用各种神经网络结构,例如MLP或Transformer。On-Policy注意力蒸馏通过最小化学生模型和教师模型注意力分布之间的KL散度来实现。
🖼️ 关键图片

📊 实验亮点
实验结果表明,RAL在多个图像和视频基准测试中均取得了显著的性能提升,优于GRPO等基线方法。例如,在某个图像分类任务上,RAL将准确率提升了5个百分点。此外,On-Policy注意力蒸馏方法也取得了良好的效果,表明传递潜在的注意力行为能够有效提升模型的跨模态对齐能力。
🎯 应用场景
RAL具有广泛的应用前景,可用于提升各种多模态任务的性能,例如图像描述生成、视觉问答、视频理解等。该方法能够有效提升模型对多模态信息的理解和利用能力,从而在实际应用中获得更好的效果。此外,RAL还可以应用于机器人导航、自动驾驶等领域,提升机器人对环境的感知和决策能力。
📄 摘要(原文)
Post-training with Reinforcement Learning (RL) has substantially improved reasoning in Large Language Models (LLMs) via test-time scaling. However, extending this paradigm to Multimodal LLMs (MLLMs) through verbose rationales yields limited gains for perception and can even degrade performance. We propose Reinforced Attention Learning (RAL), a policy-gradient framework that directly optimizes internal attention distributions rather than output token sequences. By shifting optimization from what to generate to where to attend, RAL promotes effective information allocation and improved grounding in complex multimodal inputs. Experiments across diverse image and video benchmarks show consistent gains over GRPO and other baselines. We further introduce On-Policy Attention Distillation, demonstrating that transferring latent attention behaviors yields stronger cross-modal alignment than standard knowledge distillation. Our results position attention policies as a principled and general alternative for multimodal post-training.