OmniSIFT: Modality-Asymmetric Token Compression for Efficient Omni-modal Large Language Models
作者: Yue Ding, Yiyan Ji, Jungang Li, Xuyang Liu, Xinlong Chen, Junfei Wu, Bozhou Li, Bohan Zeng, Yang Shi, Yushuo Guan, Yuanxing Zhang, Jiaheng Liu, Qiang Liu, Pengfei Wan, Liang Wang
分类: cs.CL
发布日期: 2026-02-04
备注: Code will be released soon
💡 一句话要点
OmniSIFT:面向高效Omni-LLM的模态非对称Token压缩框架
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 Token压缩 视频理解 音频处理 大语言模型 模型优化 模态非对称
📋 核心要点
- Omni-LLM依赖长多模态token序列,计算开销大,而针对Omni-LLM的token压缩方法有限。
- OmniSIFT采用模态非对称压缩,通过时空视频剪枝和视觉引导的音频选择,减少冗余token。
- 实验表明,OmniSIFT仅用25%的token上下文,性能超越现有压缩方法,甚至超过全token模型。
📝 摘要(中文)
Omni-modal大型语言模型(Omni-LLM)在音视频理解任务中表现出强大的能力。然而,它们对长多模态token序列的依赖导致了巨大的计算开销。尽管存在这一挑战,但为Omni-LLM设计的token压缩方法仍然有限。为了弥合这一差距,我们提出了OmniSIFT(Omni-modal Spatio-temporal Informed Fine-grained Token compression),这是一个专为Omni-LLM量身定制的模态非对称token压缩框架。具体来说,OmniSIFT采用两阶段压缩策略:(i)时空视频剪枝模块,消除帧内结构和帧间重叠产生的视频冗余,以及(ii)视觉引导的音频选择模块,过滤音频token。整个框架通过可微的直通估计器进行端到端优化。在五个代表性基准上的大量实验证明了OmniSIFT的有效性和鲁棒性。值得注意的是,对于Qwen2.5-Omni-7B,OmniSIFT仅引入了4.85M参数,同时保持了比OmniZip等免训练基线更低的延迟。仅使用原始token上下文的25%,OmniSIFT始终优于所有压缩基线,甚至在某些任务上超过了全token模型的性能。
🔬 方法详解
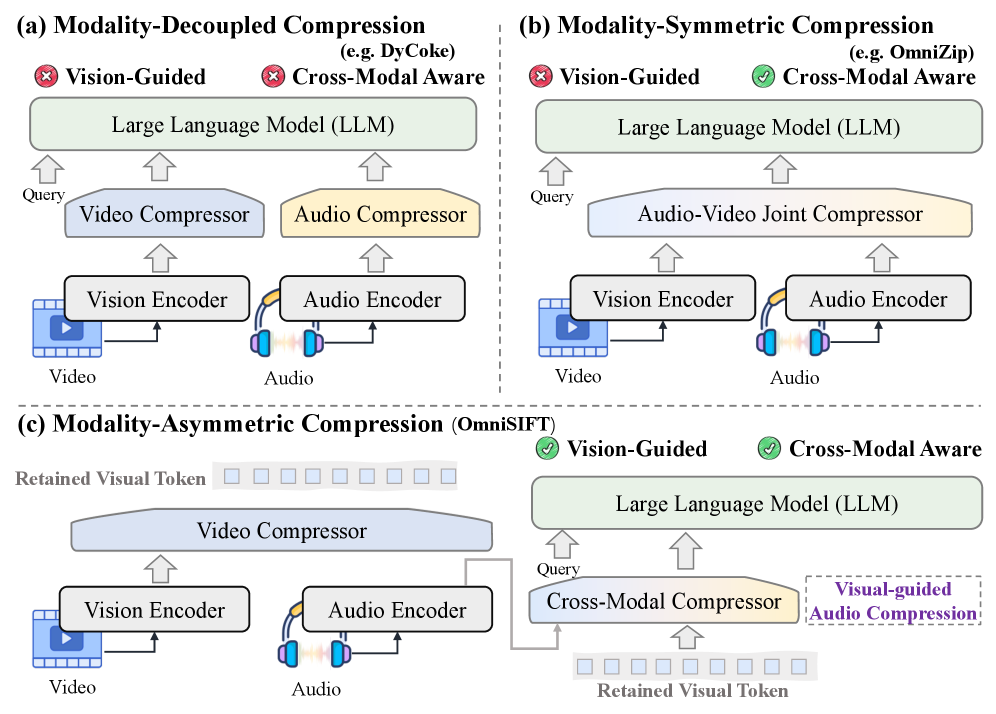
问题定义:OmniSIFT旨在解决Omni-LLM处理长多模态序列时计算开销大的问题。现有方法要么缺乏针对性,要么压缩效率不高,无法在性能和效率之间取得良好平衡。现有方法的痛点在于无法有效去除模态内的冗余以及模态间的相关性。
核心思路:OmniSIFT的核心思路是利用模态间的非对称性,对视频和音频采用不同的压缩策略。视频侧重于时空冗余消除,音频侧重于视觉信息引导的选择,从而更有效地去除冗余token,降低计算成本,同时保持模型性能。这样设计的原因在于视频和音频的特性不同,需要针对性地处理。
技术框架:OmniSIFT框架包含两个主要模块:(1) 时空视频剪枝模块:该模块旨在消除视频帧内和帧间的冗余信息。它通过分析视频帧的时空特征,识别并移除不重要的帧和区域。(2) 视觉引导的音频选择模块:该模块利用视觉信息来指导音频token的选择。它通过分析视频内容,确定与视频内容相关的音频token,并过滤掉不相关的token。整个框架采用端到端的方式进行训练,通过可微的直通估计器(Straight-Through Estimator)优化。
关键创新:OmniSIFT的关键创新在于其模态非对称的token压缩策略。与传统的token压缩方法不同,OmniSIFT针对视频和音频的特性,采用了不同的压缩策略,从而更有效地去除冗余信息。此外,OmniSIFT还采用了视觉引导的音频选择模块,利用视觉信息来指导音频token的选择,从而进一步提高了压缩效率。
关键设计:在时空视频剪枝模块中,使用了可学习的mask来控制哪些视频帧和区域被保留。损失函数包括重构损失和稀疏性损失,以保证压缩后的视频能够尽可能地保留原始信息,并鼓励mask的稀疏性。在视觉引导的音频选择模块中,使用了cross-attention机制来融合视觉和音频信息,从而确定哪些音频token与视频内容相关。整个框架使用AdamW优化器进行训练,学习率设置为1e-4。
🖼️ 关键图片


📊 实验亮点
OmniSIFT在Qwen2.5-Omni-7B模型上仅引入4.85M参数,在保持较低延迟的同时,仅使用25%的原始token上下文,性能超越了OmniZip等免训练基线,并在多个任务上超过了全token模型的性能。这表明OmniSIFT在压缩效率和性能保持方面具有显著优势。
🎯 应用场景
OmniSIFT可应用于各种需要高效处理音视频数据的场景,例如移动设备上的视频理解、实时视频会议、智能监控等。通过降低计算开销,OmniSIFT使得Omni-LLM能够在资源受限的设备上运行,并提高实时性。未来,该技术有望推动多模态人工智能在更广泛领域的应用。
📄 摘要(原文)
Omni-modal Large Language Models (Omni-LLMs) have demonstrated strong capabilities in audio-video understanding tasks. However, their reliance on long multimodal token sequences leads to substantial computational overhead. Despite this challenge, token compression methods designed for Omni-LLMs remain limited. To bridge this gap, we propose OmniSIFT (Omni-modal Spatio-temporal Informed Fine-grained Token compression), a modality-asymmetric token compression framework tailored for Omni-LLMs. Specifically, OmniSIFT adopts a two-stage compression strategy: (i) a spatio-temporal video pruning module that removes video redundancy arising from both intra-frame structure and inter-frame overlap, and (ii) a vision-guided audio selection module that filters audio tokens. The entire framework is optimized end-to-end via a differentiable straight-through estimator. Extensive experiments on five representative benchmarks demonstrate the efficacy and robustness of OmniSIFT. Notably, for Qwen2.5-Omni-7B, OmniSIFT introduces only 4.85M parameters while maintaining lower latency than training-free baselines such as OmniZip. With merely 25% of the original token context, OmniSIFT consistently outperforms all compression baselines and even surpasses the performance of the full-token model on several tasks.