When Silence Is Golden: Can LLMs Learn to Abstain in Temporal QA and Beyond?
作者: Xinyu Zhou, Chang Jin, Carsten Eickhoff, Zhijiang Guo, Seyed Ali Bahrainian
分类: cs.CL, cs.AI
发布日期: 2026-02-04
备注: Accepted to ICLR2026
💡 一句话要点
提出基于强化学习的CoT框架,提升LLM在时序问答中的拒答能力
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 时序问答 拒答能力 强化学习 思维链 不确定性建模 可靠性
📋 核心要点
- 现有LLM在时序问答中常忽略时间信息,产生错误答案,且缺乏承认不确定性的拒答能力。
- 论文提出结合CoT监督和强化学习的训练框架,通过拒答感知奖励引导模型学习何时拒绝回答。
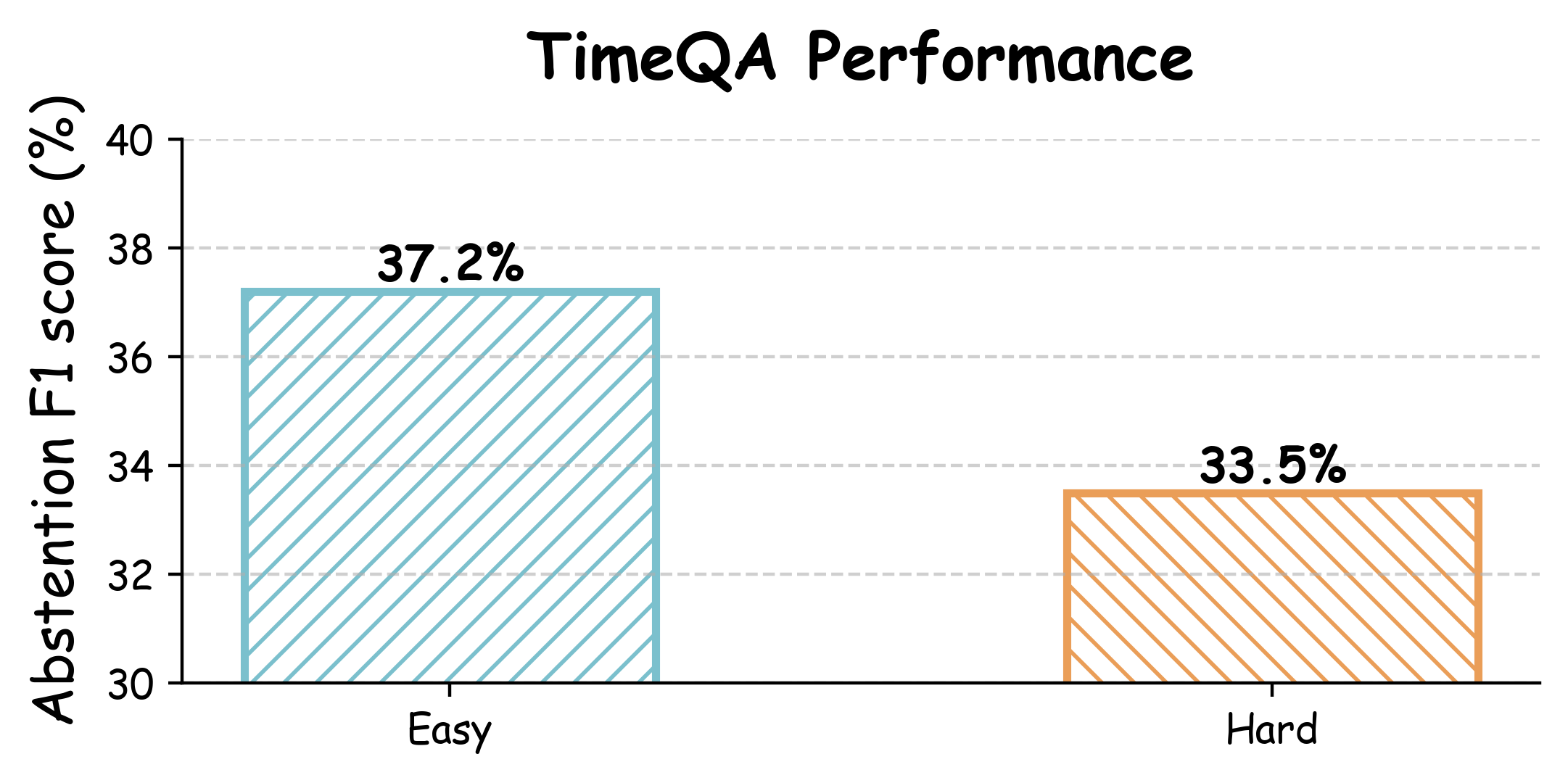
- 实验表明,该方法显著提升了模型在时序问答上的准确率,并提高了对无法回答问题的拒答率。
📝 摘要(中文)
大型语言模型(LLM)很少承认不确定性,经常产生流畅但具有误导性的答案,而不是选择拒绝回答。这种弱点在时序问答中尤为明显,模型经常忽略时间敏感的证据,并将不同时间段的事实混淆。本文首次对训练LLM在时序问答中具备拒答能力进行了实证研究。现有的校准方法可能无法可靠地捕捉复杂推理中的不确定性。因此,我们将拒答视为一种可教授的技能,并引入了一个管道,将思维链(CoT)监督与由拒答感知奖励引导的强化学习(RL)相结合。我们的目标是系统地分析不同类型的信息和训练技术如何影响LLM中具有拒答行为的时序推理。通过对各种方法进行广泛的实验研究,我们发现RL在推理方面产生了强大的经验收益:由Qwen2.5-1.5B-Instruct初始化的模型在TimeQA-Easy和Hard上分别超过GPT-4o 3.46%和5.80%的精确匹配率。此外,它在无法回答的问题上的真阳性率比纯监督微调(SFT)变体提高了20%。除了性能之外,我们的分析表明,SFT会诱导过度自信并损害可靠性,而RL可以提高预测准确性,但也表现出类似的风险。最后,通过比较隐式推理线索(例如,原始上下文、时间子上下文、知识图谱)与显式CoT监督,我们发现隐式信息对具有拒答的推理提供的益处有限。我们的研究为如何联合优化拒答和推理提供了新的见解,为构建更可靠的LLM奠定了基础。
🔬 方法详解
问题定义:论文旨在解决大型语言模型在时序问答任务中过度自信的问题,即模型倾向于给出错误答案,而不是承认自身的不确定性并拒绝回答。现有方法,如校准技术,在捕捉复杂推理过程中的不确定性方面表现不佳,无法有效提升模型的拒答能力。
核心思路:论文将拒答视为一种可学习的技能,通过强化学习的方式训练模型,使其能够根据自身对答案的置信度选择是否回答问题。核心在于设计合适的奖励函数,鼓励模型在不确定时选择拒答,在确定时给出正确答案。
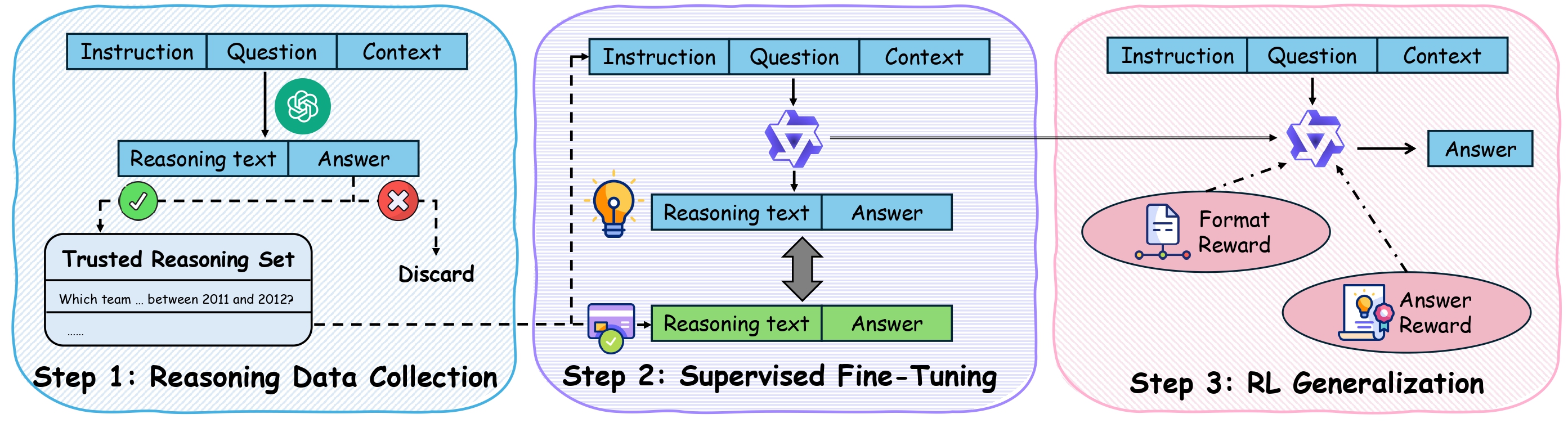
技术框架:整体框架包含两个主要阶段:首先,使用思维链(Chain-of-Thought, CoT)数据对模型进行监督微调(SFT),使其具备初步的推理能力。然后,使用强化学习(RL)对模型进行进一步训练,通过拒答感知奖励函数引导模型学习拒答行为。该框架利用CoT提供推理过程的监督,并利用RL优化拒答策略。
关键创新:论文的关键创新在于将拒答问题转化为一个强化学习问题,并设计了相应的拒答感知奖励函数。与传统的校准方法不同,该方法直接训练模型学习何时应该拒绝回答,从而更有效地提升模型的拒答能力。此外,结合CoT监督和强化学习,可以更好地利用已有的知识和推理能力。
关键设计:奖励函数的设计是关键。奖励函数需要平衡回答正确、回答错误和拒绝回答三种情况。具体来说,回答正确会获得正向奖励,回答错误会受到惩罚,拒绝回答则会获得一个适中的奖励,以鼓励模型在不确定时选择拒答。此外,论文还探索了不同的信息类型(如原始上下文、时间子上下文、知识图谱)对模型推理和拒答行为的影响。
🖼️ 关键图片

📊 实验亮点
实验结果表明,使用强化学习训练的模型在TimeQA-Easy和Hard数据集上分别超越GPT-4o 3.46%和5.80%的精确匹配率。更重要的是,该模型在无法回答的问题上的真阳性率比纯监督微调模型提高了20%,表明其拒答能力得到了显著提升。这证明了强化学习在提升LLM拒答能力方面的有效性。
🎯 应用场景
该研究成果可应用于各种需要高可靠性的问答系统,例如医疗诊断、金融分析、法律咨询等领域。通过提升模型在不确定情况下的拒答能力,可以有效避免错误信息的传播,提高系统的安全性和可靠性,并为用户提供更值得信赖的服务。
📄 摘要(原文)
Large language models (LLMs) rarely admit uncertainty, often producing fluent but misleading answers, rather than abstaining (i.e., refusing to answer). This weakness is even evident in temporal question answering, where models frequently ignore time-sensitive evidence and conflate facts across different time-periods. In this paper, we present the first empirical study of training LLMs with an abstention ability while reasoning about temporal QA. Existing approaches such as calibration might be unreliable in capturing uncertainty in complex reasoning. We instead frame abstention as a teachable skill and introduce a pipeline that couples Chain-of-Thought (CoT) supervision with Reinforcement Learning (RL) guided by abstention-aware rewards. Our goal is to systematically analyze how different information types and training techniques affect temporal reasoning with abstention behavior in LLMs. Through extensive experiments studying various methods, we find that RL yields strong empirical gains on reasoning: a model initialized by Qwen2.5-1.5B-Instruct surpasses GPT-4o by $3.46\%$ and $5.80\%$ in Exact Match on TimeQA-Easy and Hard, respectively. Moreover, it improves the True Positive rate on unanswerable questions by $20\%$ over a pure supervised fine-tuned (SFT) variant. Beyond performance, our analysis shows that SFT induces overconfidence and harms reliability, while RL improves prediction accuracy but exhibits similar risks. Finally, by comparing implicit reasoning cues (e.g., original context, temporal sub-context, knowledge graphs) with explicit CoT supervision, we find that implicit information provides limited benefit for reasoning with abstention. Our study provides new insights into how abstention and reasoning can be jointly optimized, providing a foundation for building more reliable LLMs.