Exploiting contextual information to improve stance detection in informal political discourse with LLMs
作者: Arman Engin Sucu, Yixiang Zhou, Mario A. Nascimento, Tony Mullen
分类: cs.CL, cs.AI
发布日期: 2026-02-04
备注: 14 pages, 7 figures
期刊: Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 4: Student Research Workshop) 2025
DOI: 10.18653/v1/2025.acl-srw.86
💡 一句话要点
利用上下文信息,通过大语言模型提升非正式政治语境下的立场检测
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 立场检测 大型语言模型 上下文信息 用户画像 政治语境
📋 核心要点
- 现有政治立场检测方法在处理非正式在线语境时,难以有效应对语言的讽刺、歧义和上下文依赖性。
- 该论文提出利用用户历史帖子构建的个人资料摘要作为上下文信息,辅助大语言模型进行立场检测。
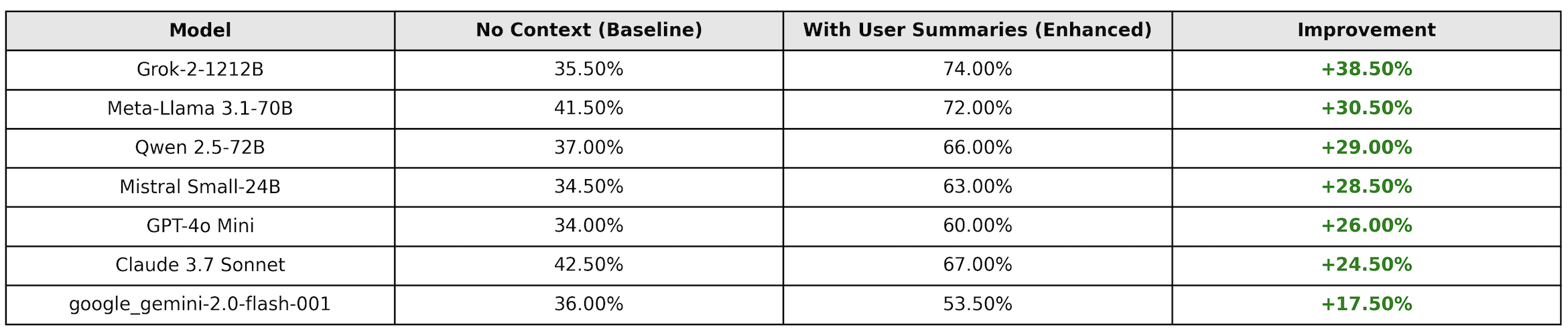
- 实验结果表明,引入上下文信息后,LLM的立场检测准确率显著提升,最高提升幅度达38.5%,最高准确率达74%。
📝 摘要(中文)
本研究探讨了使用大型语言模型(LLMs)在非正式在线语境中进行政治立场检测,该语境下的语言通常具有讽刺性、歧义性和上下文依赖性。我们探索了提供上下文信息(特别是从历史帖子中提取的用户个人资料摘要)是否可以提高分类准确性。通过使用真实世界的政治论坛数据集,我们生成了结构化的个人资料,总结了用户的意识形态倾向、重复出现的主题和语言模式。我们通过全面的跨模型评估,在基线和上下文丰富的设置中评估了七个最先进的LLM。我们的研究结果表明,上下文提示显著提高了准确性,提升幅度从+17.5%到+38.5%不等,最高可达74%的准确率,超过了以往的方法。我们还分析了个人资料大小和帖子选择策略如何影响性能,表明战略性地选择政治内容比选择更大的随机上下文产生更好的结果。这些发现强调了结合用户级别上下文以增强LLM在细致的政治分类任务中的性能的价值。
🔬 方法详解
问题定义:论文旨在解决非正式政治讨论中立场检测的难题。现有方法难以有效处理非正式语境中常见的讽刺、隐喻和上下文依赖性表达,导致立场检测准确率较低。此外,缺乏对用户历史行为的考虑,使得模型难以理解用户的真实意图。
核心思路:论文的核心思路是利用用户的历史发帖记录构建用户画像,将用户画像作为上下文信息输入到大型语言模型中,从而提高模型对用户立场的判断准确性。这种方法模拟了人类在理解他人观点时会考虑其背景信息的认知过程。
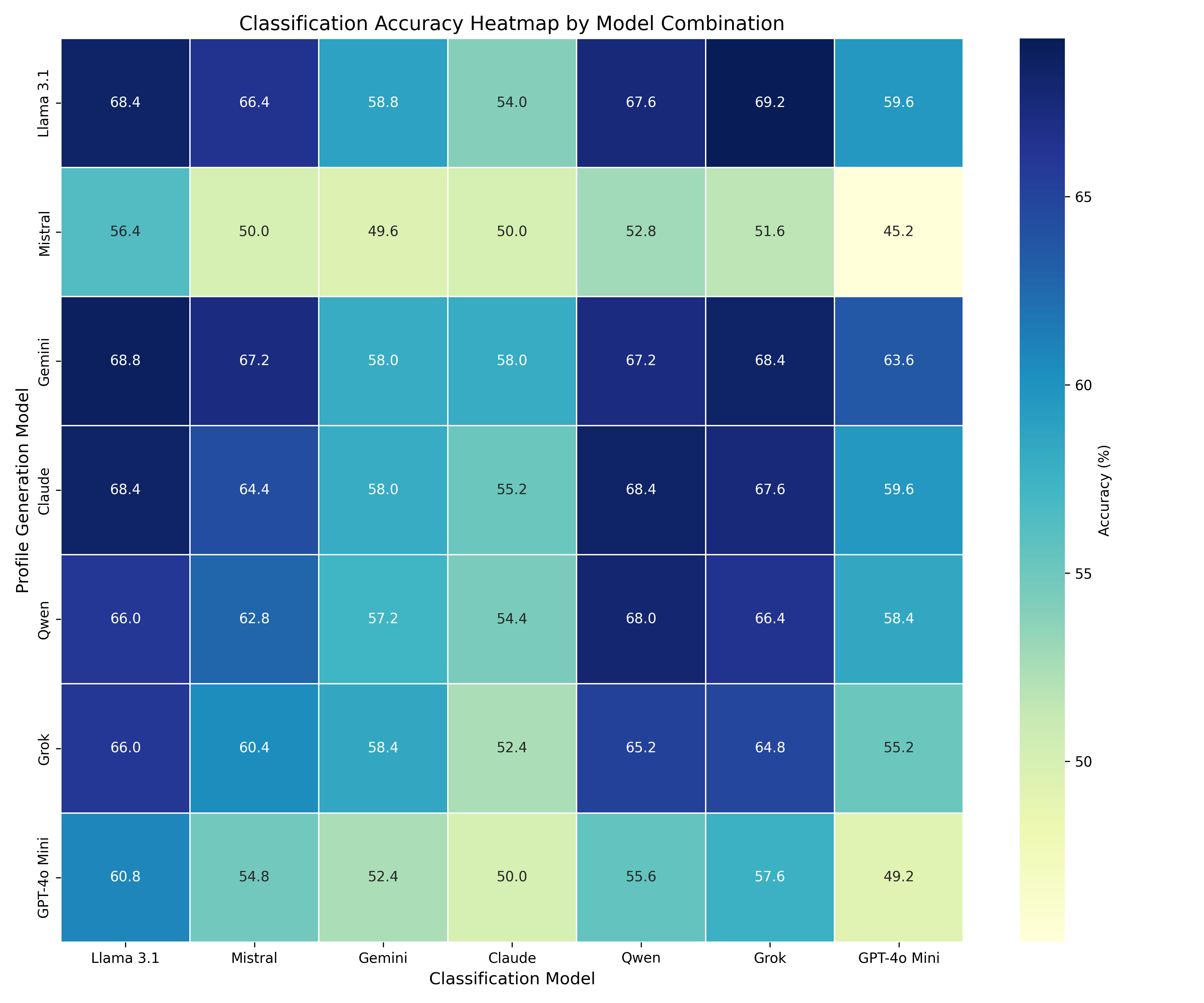
技术框架:整体框架包括以下几个主要步骤:1)收集政治论坛数据;2)基于用户历史发帖记录生成用户画像,画像包含用户的意识形态倾向、常讨论话题和语言风格等信息;3)将用户画像作为上下文提示输入到大型语言模型中;4)利用LLM进行立场检测;5)评估模型性能。
关键创新:该论文的关键创新在于将用户画像作为上下文信息引入到LLM中,从而显著提高了非正式政治语境下的立场检测准确率。与传统方法相比,该方法能够更好地捕捉用户的真实意图,并有效应对非正式语境中的语言挑战。
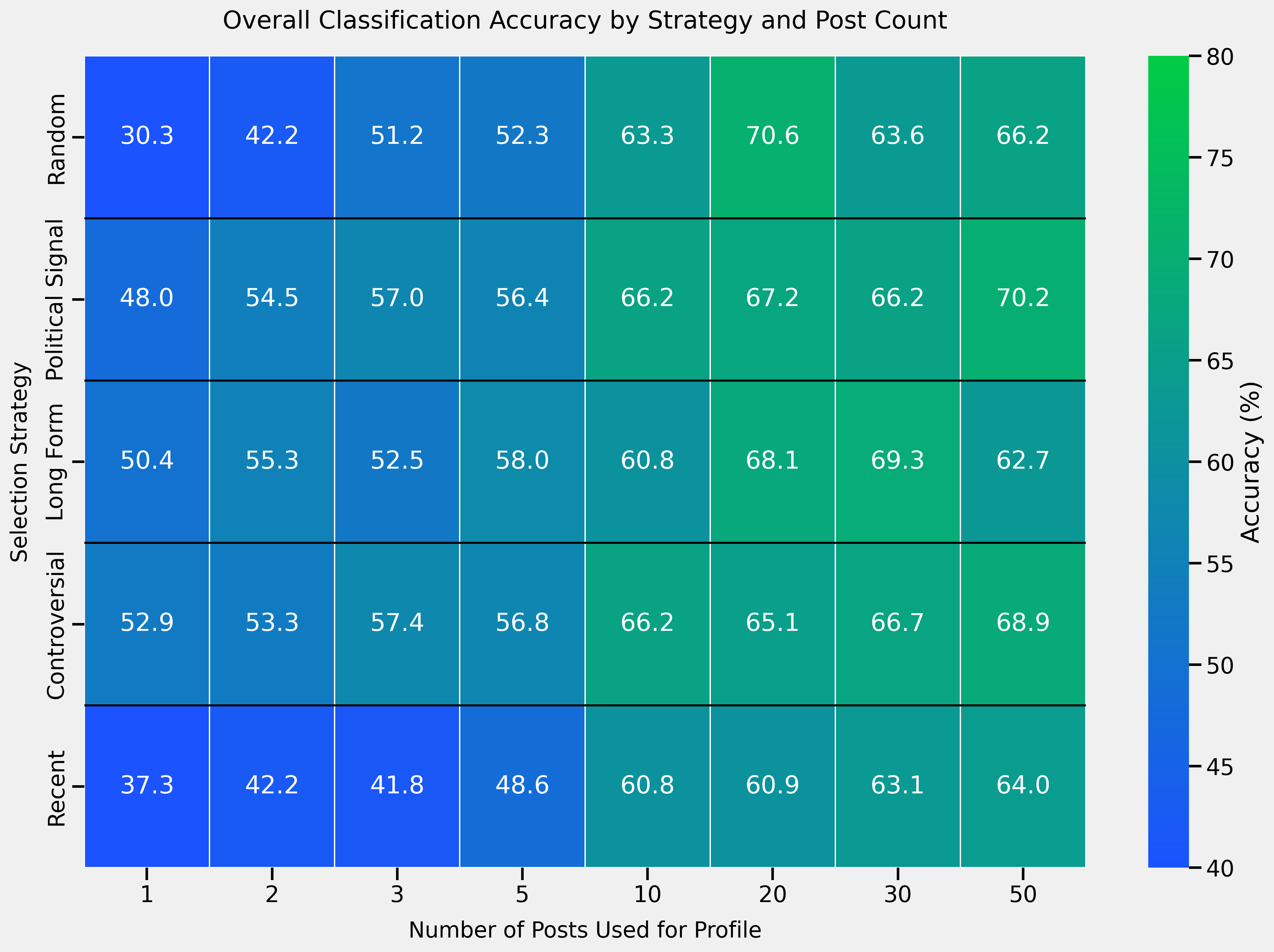
关键设计:用户画像的构建方式是关键设计之一。论文采用了结构化的方式来总结用户的意识形态倾向、常讨论话题和语言风格。此外,论文还研究了不同大小的用户画像以及不同的帖子选择策略对模型性能的影响。例如,相比于随机选择帖子,选择包含更多政治内容的帖子能够产生更好的用户画像。
🖼️ 关键图片
📊 实验亮点
实验结果表明,引入用户画像作为上下文信息后,LLM的立场检测准确率显著提升,提升幅度从+17.5%到+38.5%不等,最高可达74%的准确率。此外,研究还发现,相比于随机选择帖子,选择包含更多政治内容的帖子能够产生更好的用户画像,从而进一步提高模型性能。该方法在多个最先进的LLM上都取得了显著的提升。
🎯 应用场景
该研究成果可应用于舆情分析、网络安全监控、政治观点挖掘等领域。通过准确识别用户在政治议题上的立场,可以帮助政府、企业和研究机构更好地了解公众舆论,及时发现潜在的网络安全风险,并深入分析不同政治群体的观点和诉求。此外,该技术还可以用于个性化推荐,为用户提供更符合其政治倾向的信息。
📄 摘要(原文)
This study investigates the use of Large Language Models (LLMs) for political stance detection in informal online discourse, where language is often sarcastic, ambiguous, and context-dependent. We explore whether providing contextual information, specifically user profile summaries derived from historical posts, can improve classification accuracy. Using a real-world political forum dataset, we generate structured profiles that summarize users' ideological leaning, recurring topics, and linguistic patterns. We evaluate seven state-of-the-art LLMs across baseline and context-enriched setups through a comprehensive cross-model evaluation. Our findings show that contextual prompts significantly boost accuracy, with improvements ranging from +17.5\% to +38.5\%, achieving up to 74\% accuracy that surpasses previous approaches. We also analyze how profile size and post selection strategies affect performance, showing that strategically chosen political content yields better results than larger, randomly selected contexts. These findings underscore the value of incorporating user-level context to enhance LLM performance in nuanced political classification tasks.