LinGO: A Linguistic Graph Optimization Framework with LLMs for Interpreting Intents of Online Uncivil Discourse
作者: Yuan Zhang, Thales Bertaglia
分类: cs.CL, cs.CY
发布日期: 2026-02-04
💡 一句话要点
LinGO:利用语言图优化框架与LLM提升在线不文明言论意图识别
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 不文明言论检测 语言图优化 大型语言模型 意图识别 检索增强生成
📋 核心要点
- 现有不文明言论检测器容易误判,无法准确识别包含不文明线索但表达文明意图的帖子,导致不文明行为的评估偏差。
- LinGO框架通过将语言分解为多步骤组件,并针对性地优化易错步骤的提示或示例,从而提升LLM对不文明意图的理解。
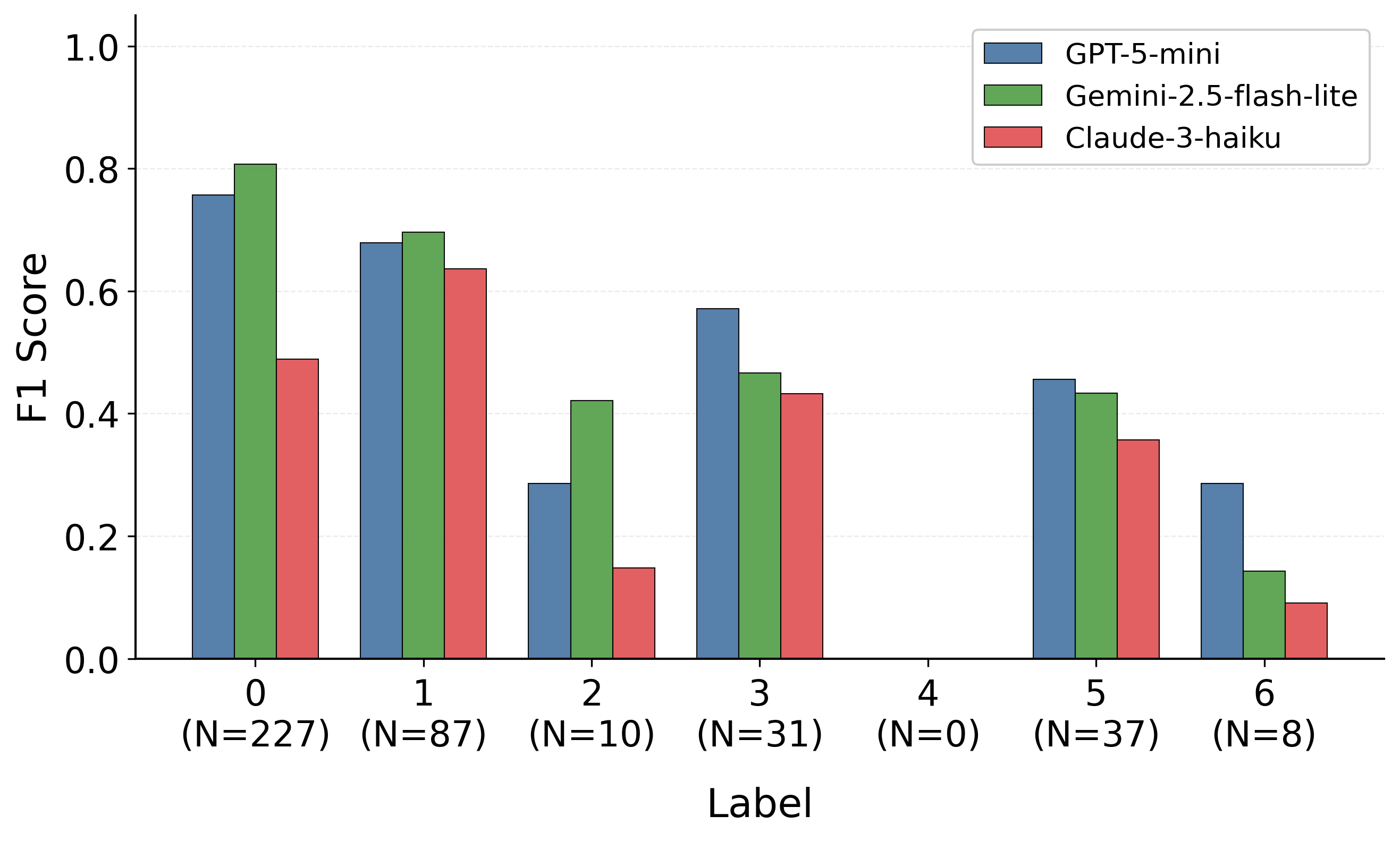
- 实验结果表明,LinGO在多个LLM上均优于现有基线方法,尤其是在结合RAG和Gemini模型时,性能提升显著。
📝 摘要(中文)
检测不文明语言对于维护安全、包容和民主的在线空间至关重要。然而,现有的分类器经常错误地解释包含不文明线索但表达文明意图的帖子,导致对在线有害不文明行为的估计过高。我们引入LinGO,一个用于大型语言模型(LLM)的语言图优化框架,它利用语言结构和优化技术来分类使用各种直接和间接表达方式的不文明行为的多类别意图。LinGO将语言分解为多步骤语言组件,识别导致最多错误的目标步骤,并迭代优化目标步骤的提示和/或示例组件。我们使用在2022年巴西总统选举期间收集的数据集对其进行评估,该数据集包含四种形式的政治不文明行为:不礼貌(IMP)、仇恨言论和刻板印象(HSST)、人身伤害和暴力政治言论(PHAVPR)以及对民主制度和价值观的威胁(THREAT)。每个实例都标注有六种类型的文明/不文明意图。我们使用三种经济高效的LLM:GPT-5-mini、Gemini 2.5 Flash-Lite和Claude 3 Haiku,以及四种优化技术:TextGrad、AdalFlow、DSPy和检索增强生成(RAG)来对LinGO进行基准测试。结果表明,与零样本、思维链、直接优化和微调基线相比,LinGO在所有模型中始终提高了准确性和加权F1。RAG是最强的优化技术,并且与Gemini模型配对时,可实现最佳的整体性能。这些发现表明,将多步骤语言组件合并到LLM指令中并优化目标组件可以帮助模型解释复杂的语义含义,这可以扩展到将来的其他复杂语义解释任务。
🔬 方法详解
问题定义:论文旨在解决在线不文明言论意图识别的难题。现有方法,特别是传统的分类器,在处理包含不文明线索但表达文明意图的帖子时表现不佳,导致对有害不文明行为的估计过高。这些方法无法充分理解语言的复杂性和细微差别,容易产生误判。
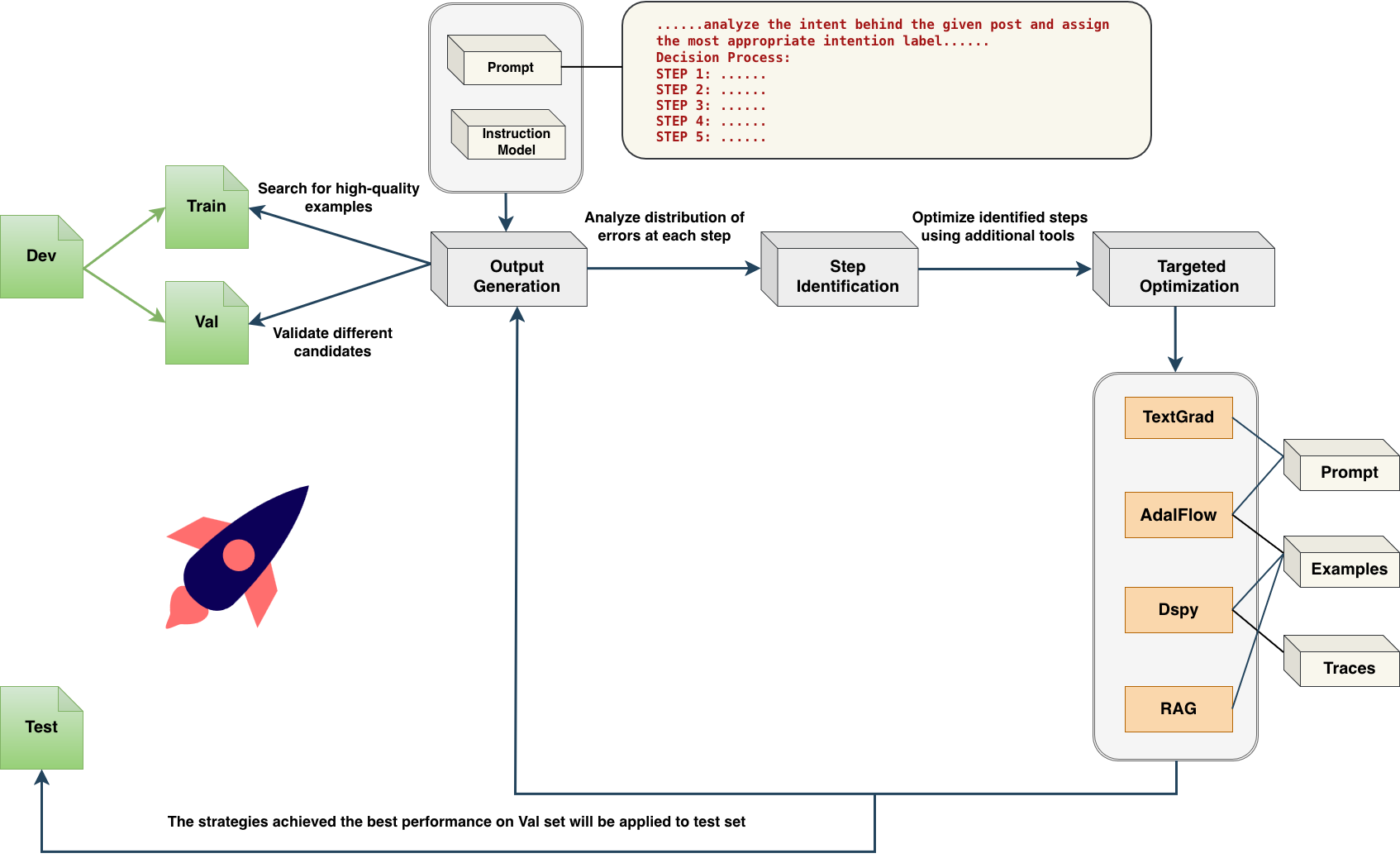
核心思路:LinGO的核心思路是将语言分解为多步骤的语言组件,并针对性地优化那些导致错误最多的步骤。通过这种分解和优化,LinGO能够更好地理解语言的复杂语义,从而更准确地识别不文明言论的意图。这种方法借鉴了人类理解语言的方式,即逐步分析和理解每个组成部分。
技术框架:LinGO框架包含以下主要步骤:1) 将语言分解为多步骤语言组件;2) 识别导致最多错误的目标步骤;3) 迭代优化目标步骤的提示和/或示例组件。框架利用大型语言模型(LLM)作为基础模型,并结合不同的优化技术(如TextGrad、AdalFlow、DSPy和RAG)来提升性能。整体流程是一个迭代优化的过程,通过不断调整提示和示例,提高LLM对不文明意图的识别能力。
关键创新:LinGO的关键创新在于其语言图优化框架,该框架能够将复杂的语言分解为可管理的组件,并针对性地优化这些组件。与传统的端到端方法不同,LinGO能够深入分析语言的结构和语义,从而更好地理解语言的意图。此外,LinGO还能够灵活地结合不同的优化技术,以适应不同的LLM和数据集。
关键设计:论文中使用了多种优化技术,包括TextGrad、AdalFlow、DSPy和RAG。RAG(检索增强生成)被证明是最有效的优化技术,它通过检索相关的外部知识来增强LLM的理解能力。此外,论文还使用了不同的LLM(如GPT-5-mini、Gemini 2.5 Flash-Lite和Claude 3 Haiku)进行实验,以评估LinGO的泛化能力。具体的参数设置和损失函数等技术细节在论文中没有详细描述,属于未知信息。
🖼️ 关键图片

📊 实验亮点
实验结果表明,LinGO在多个LLM上均优于零样本、思维链、直接优化和微调等基线方法。RAG是最有效的优化技术,与Gemini模型结合使用时,能够实现最佳的整体性能。具体而言,LinGO在准确性和加权F1指标上均有显著提升,表明其能够更准确地识别不文明言论的意图。
🎯 应用场景
LinGO框架可应用于各种在线平台,用于自动检测和过滤不文明言论,维护健康的在线讨论环境。该技术有助于减少网络欺凌、仇恨言论和政治煽动,提升用户体验,并促进更具建设性的在线交流。未来,LinGO有望扩展到其他复杂的语义解释任务,例如情感分析、观点挖掘和虚假信息检测。
📄 摘要(原文)
Detecting uncivil language is crucial for maintaining safe, inclusive, and democratic online spaces. Yet existing classifiers often misinterpret posts containing uncivil cues but expressing civil intents, leading to inflated estimates of harmful incivility online. We introduce LinGO, a linguistic graph optimization framework for large language models (LLMs) that leverages linguistic structures and optimization techniques to classify multi-class intents of incivility that use various direct and indirect expressions. LinGO decomposes language into multi-step linguistic components, identifies targeted steps that cause the most errors, and iteratively optimizes prompt and/or example components for targeted steps. We evaluate it using a dataset collected during the 2022 Brazilian presidential election, encompassing four forms of political incivility: Impoliteness (IMP), Hate Speech and Stereotyping (HSST), Physical Harm and Violent Political Rhetoric (PHAVPR), and Threats to Democratic Institutions and Values (THREAT). Each instance is annotated with six types of civil/uncivil intent. We benchmark LinGO using three cost-efficient LLMs: GPT-5-mini, Gemini 2.5 Flash-Lite, and Claude 3 Haiku, and four optimization techniques: TextGrad, AdalFlow, DSPy, and Retrieval-Augmented Generation (RAG). The results show that, across all models, LinGO consistently improves accuracy and weighted F1 compared with zero-shot, chain-of-thought, direct optimization, and fine-tuning baselines. RAG is the strongest optimization technique and, when paired with Gemini model, achieves the best overall performance. These findings demonstrate that incorporating multi-step linguistic components into LLM instructions and optimize targeted components can help the models explain complex semantic meanings, which can be extended to other complex semantic explanation tasks in the future.