VILLAIN at AVerImaTeC: Verifying Image-Text Claims via Multi-Agent Collaboration
作者: Jaeyoon Jung, Yejun Yoon, Seunghyun Yoon, Kunwoo Park
分类: cs.CL, cs.AI, cs.CY
发布日期: 2026-02-04
备注: A system description paper for the AVerImaTeC shared task at the Ninth FEVER Workshop (co-located with EACL 2026)
🔗 代码/项目: GITHUB
💡 一句话要点
VILLAIN:基于多智能体协作验证图像-文本声明的系统
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 图像-文本验证 多模态事实核查 多智能体协作 视觉-语言模型 知识检索
📋 核心要点
- 现有方法在图像-文本事实核查中缺乏有效的多模态信息融合和推理能力,难以准确识别细微的错误信息。
- VILLAIN系统通过构建多智能体协作框架,利用不同智能体在模态特定和跨模态分析上的优势,提升核查准确性。
- 该系统在AVerImaTeC共享任务中取得第一名,验证了多智能体协作在图像-文本事实核查中的有效性。
📝 摘要(中文)
本文介绍了VILLAIN,一个多模态事实核查系统,它通过基于提示的多智能体协作来验证图像-文本声明。针对AVerImaTeC共享任务,VILLAIN在事实核查的多个阶段采用视觉-语言模型智能体。文本和视觉证据从知识库中检索,并通过额外的网络收集进行丰富。为了识别关键信息并解决证据项目之间的不一致性,特定模态和跨模态智能体生成分析报告。在随后的阶段,基于这些报告生成问答对。最后,Verdict Prediction智能体基于图像-文本声明和生成的问答对产生验证结果。我们的系统在所有评估指标的排行榜上名列第一。源代码可在https://github.com/ssu-humane/VILLAIN公开获取。
🔬 方法详解
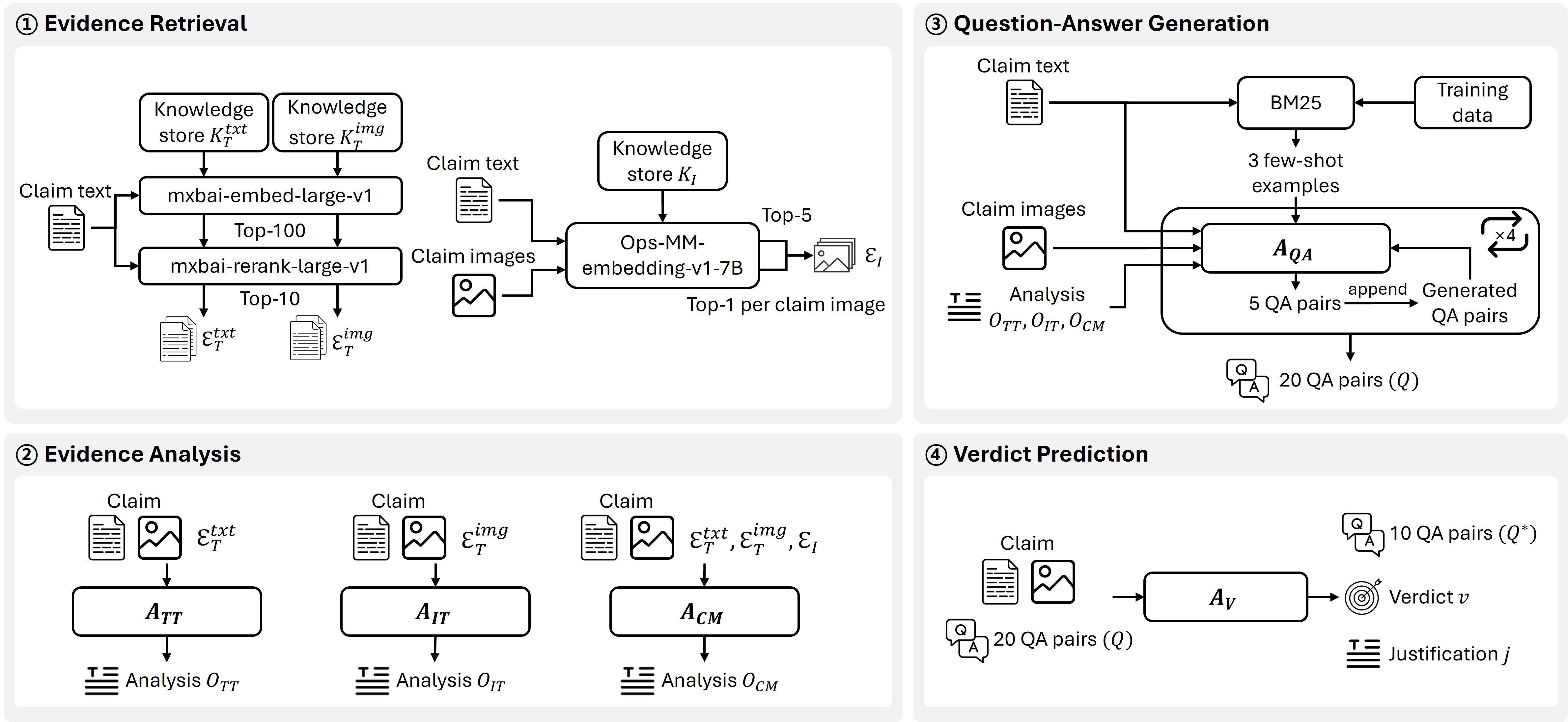
问题定义:论文旨在解决图像-文本声明的事实核查问题。现有方法在处理复杂场景和细粒度语义时,往往难以准确判断声明的真伪。痛点在于缺乏有效的多模态信息融合和推理机制,以及对外部知识的充分利用。
核心思路:论文的核心思路是利用多智能体协作,每个智能体负责不同的任务,例如信息检索、模态特定分析、跨模态推理和结论预测。通过智能体之间的协作,可以更全面地理解图像和文本信息,并有效地利用外部知识,从而提高事实核查的准确性。
技术框架:VILLAIN系统的整体架构包含以下几个主要阶段:1) 知识检索:从知识库(包括额外的网络收集数据)中检索相关的文本和视觉证据。2) 报告生成:模态特定和跨模态智能体生成分析报告,用于识别关键信息和解决证据项目之间的不一致性。3) 问答对生成:基于分析报告生成问答对,用于进一步验证声明的真伪。4) 结论预测:Verdict Prediction智能体基于图像-文本声明和生成的问答对,最终预测验证结果。
关键创新:该论文的关键创新在于提出了一个基于提示的多智能体协作框架,将复杂的事实核查任务分解为多个子任务,并分配给不同的智能体。这种方法能够充分利用不同智能体的优势,实现更高效和准确的事实核查。此外,系统还通过额外的网络收集来丰富知识库,从而提高了对外部知识的利用率。
关键设计:论文中使用了基于提示的智能体,通过精心设计的提示语来引导智能体执行特定的任务。具体的技术细节包括:用于信息检索的查询构建方法、用于模态特定分析和跨模态推理的视觉-语言模型选择和微调策略、以及用于结论预测的分类器设计。此外,知识库的构建和维护也是一个关键的设计环节,需要考虑数据的质量和覆盖范围。
🖼️ 关键图片

📊 实验亮点
VILLAIN系统在AVerImaTeC共享任务中,在所有评估指标的排行榜上均名列第一,证明了其在图像-文本事实核查方面的优越性能。这一结果表明,多智能体协作框架能够有效地提升事实核查的准确性和效率,为未来的研究提供了有价值的参考。
🎯 应用场景
该研究成果可应用于新闻媒体的事实核查、社交媒体内容审核、以及教育领域的知识验证等场景。通过自动化的图像-文本事实核查,可以有效减少虚假信息的传播,提高信息的可信度,并为用户提供更可靠的信息服务。未来,该技术还可以扩展到其他多模态数据的验证,例如视频和音频。
📄 摘要(原文)
This paper describes VILLAIN, a multimodal fact-checking system that verifies image-text claims through prompt-based multi-agent collaboration. For the AVerImaTeC shared task, VILLAIN employs vision-language model agents across multiple stages of fact-checking. Textual and visual evidence is retrieved from the knowledge store enriched through additional web collection. To identify key information and address inconsistencies among evidence items, modality-specific and cross-modal agents generate analysis reports. In the subsequent stage, question-answer pairs are produced based on these reports. Finally, the Verdict Prediction agent produces the verification outcome based on the image-text claim and the generated question-answer pairs. Our system ranked first on the leaderboard across all evaluation metrics. The source code is publicly available at https://github.com/ssu-humane/VILLAIN.