Semantic Self-Distillation for Language Model Uncertainty
作者: Edward Phillips, Sean Wu, Boyan Gao, David A. Clifton
分类: cs.CL
发布日期: 2026-02-04
💡 一句话要点
提出语义自蒸馏方法,用于语言模型不确定性量化和幻觉预测。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 语言模型 不确定性量化 语义分散性 知识蒸馏 幻觉预测
📋 核心要点
- 大型语言模型的不确定性量化困难,现有方法计算成本高昂,难以应用于延迟敏感场景。
- 提出语义自蒸馏(SSD)方法,将语言模型的语义分布提炼到轻量级学生模型中,用于快速不确定性估计。
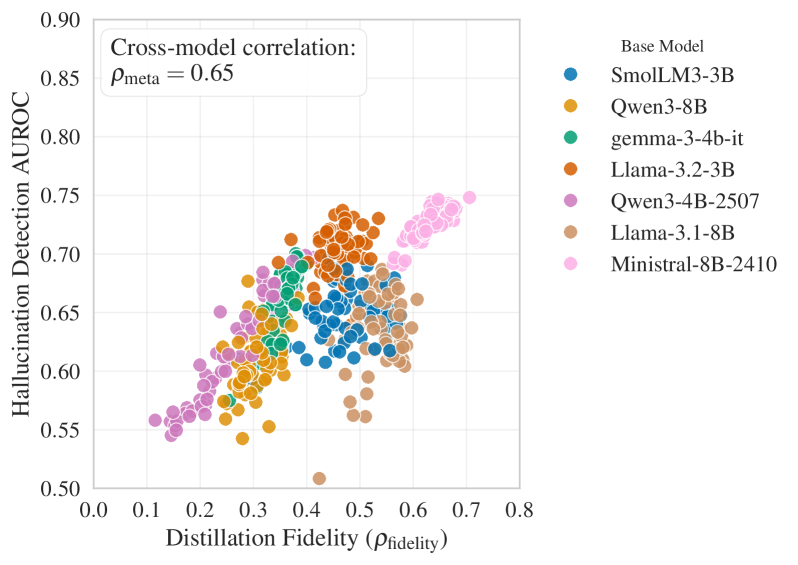
- 实验表明,SSD在幻觉预测和领域外答案检测方面表现出色,性能与计算成本高的语义分散性方法相当。
📝 摘要(中文)
大型语言模型在不确定性量化方面面临挑战,部分原因是其复杂性和输出的多样性。语义分散性,即采样答案含义的方差,已被认为是模型不确定性的有效代理,但其计算成本限制了其在延迟敏感型应用中的使用。本文表明,采样的语义分布可以被提炼成轻量级的学生模型,该模型在语言模型生成答案token之前估计提示条件下的不确定性。学生模型预测可能答案的语义分布;该分布的熵为幻觉预测提供了有效的不确定性信号,概率密度允许评估候选答案的可靠性。在TriviaQA上,我们的学生模型在幻觉预测方面与有限样本语义分散性相匹配或优于它,并为领域外答案检测提供了强大的信号。我们将这种技术称为语义自蒸馏(SSD),我们认为它为提炼复杂输出空间(超越语言)中的预测不确定性提供了一个通用框架。
🔬 方法详解
问题定义:大型语言模型(LLM)的复杂性和输出多样性使得对其进行可靠的不确定性量化变得困难。现有的语义分散性方法,通过计算多个采样答案之间的语义差异来估计不确定性,虽然有效,但计算成本过高,不适用于需要低延迟的应用场景。因此,需要一种更高效的方法来量化LLM的不确定性,特别是对于幻觉预测和领域外检测等任务。
核心思路:论文的核心思路是将LLM的语义分散性知识蒸馏到一个轻量级的学生模型中。学生模型学习预测LLM在给定prompt下的答案语义分布,而不是直接生成答案。通过分析学生模型预测的语义分布的熵,可以有效地估计LLM的不确定性。这种方法的关键在于,学生模型的计算成本远低于LLM,因此可以实现快速的不确定性量化。
技术框架:SSD框架包含两个主要阶段:教师模型(LLM)的语义分布生成和学生模型的训练。首先,对于给定的prompt,使用LLM生成多个采样答案。然后,将这些答案嵌入到语义空间中,并计算其语义分布。这个语义分布作为教师信号,用于训练学生模型。学生模型是一个轻量级的神经网络,它以prompt作为输入,预测一个语义分布,该分布尽可能接近教师模型生成的语义分布。在推理阶段,学生模型预测的语义分布的熵被用作不确定性度量。
关键创新:SSD的关键创新在于将语义分散性知识从大型LLM蒸馏到轻量级学生模型。与直接使用LLM进行不确定性量化相比,SSD显著降低了计算成本,使其适用于延迟敏感型应用。此外,SSD提供了一种通用的框架,可以应用于各种复杂的输出空间,而不仅仅局限于语言模型。
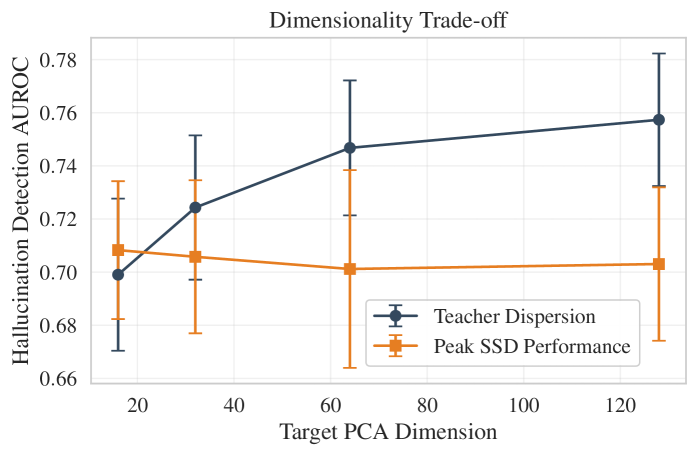
关键设计:学生模型通常是一个小型Transformer模型或MLP。损失函数通常采用KL散度或交叉熵,用于衡量学生模型预测的语义分布与教师模型生成的语义分布之间的差异。关键参数包括学生模型的架构大小、训练数据量和蒸馏温度。蒸馏温度用于控制学生模型学习的平滑程度,较高的温度可以防止学生模型过度拟合教师模型的噪声。
🖼️ 关键图片

📊 实验亮点
在TriviaQA数据集上,SSD学生模型在幻觉预测方面与计算成本更高的有限样本语义分散性方法性能相当甚至更好。同时,SSD为领域外答案检测提供了强大的信号,表明其具有良好的泛化能力。这些结果表明,SSD是一种有效且高效的语言模型不确定性量化方法。
🎯 应用场景
该研究成果可应用于各种需要可靠不确定性估计的语言模型应用,例如:问答系统,可以利用不确定性估计来过滤掉不可靠的答案;对话系统,可以避免生成不确定或矛盾的回复;内容生成,可以评估生成内容的质量和可靠性。此外,该方法还可以扩展到其他领域,例如图像生成和机器人控制,以提高系统的鲁棒性和安全性。
📄 摘要(原文)
Large language models present challenges for principled uncertainty quantification, in part due to their complexity and the diversity of their outputs. Semantic dispersion, or the variance in the meaning of sampled answers, has been proposed as a useful proxy for model uncertainty, but the associated computational cost prohibits its use in latency-critical applications. We show that sampled semantic distributions can be distilled into lightweight student models which estimate a prompt-conditioned uncertainty before the language model generates an answer token. The student model predicts a semantic distribution over possible answers; the entropy of this distribution provides an effective uncertainty signal for hallucination prediction, and the probability density allows candidate answers to be evaluated for reliability. On TriviaQA, our student models match or outperform finite-sample semantic dispersion for hallucination prediction and provide a strong signal for out-of-domain answer detection. We term this technique Semantic Self-Distillation (SSD), which we suggest provides a general framework for distilling predictive uncertainty in complex output spaces beyond language.