LycheeDecode: Accelerating Long-Context LLM Inference via Hybrid-Head Sparse Decoding
作者: Gang Lin, Dongfang Li, Zhuoen Chen, Yukun Shi, Xuhui Chen, Baotian Hu, Min Zhang
分类: cs.CL, cs.AI
发布日期: 2026-02-04
备注: ICLR 2026
💡 一句话要点
LycheeDecode:通过混合头稀疏解码加速长文本LLM推理。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 长文本LLM 推理加速 稀疏注意力 混合头注意力 键值缓存 HardKuma 高效解码
📋 核心要点
- 现有长文本LLM推理面临键值缓存快速增长的挑战,导致内存和延迟成本高昂。
- LycheeDecode提出一种细粒度的混合头注意力机制,通过动态识别和重用关键token来加速解码。
- 实验表明,LycheeDecode在保持甚至超越全注意力模型生成质量的同时,实现了高达2.7倍的加速。
📝 摘要(中文)
长文本大型语言模型(LLM)的普及暴露了一个关键瓶颈:解码过程中快速扩展的键值缓存,这带来了沉重的内存和延迟成本。虽然最近的方法试图通过在层之间共享一组关键token来缓解这个问题,但这种粗粒度的共享忽略了注意力头的功能多样性,从而损害了模型性能。为了解决这个问题,我们提出了一种高效的解码方法LycheeDecode,它以一种细粒度的混合头注意力机制为中心,该机制采用了一种硬件高效的top-k选择策略。具体来说,这种新颖的基于HardKuma的机制将注意力头划分为一个小的检索头子集,用于动态识别关键token,以及一个主要的稀疏头子集,用于重用这些token以实现高效计算。通过在Llama3和Qwen3等领先模型上,针对长文本理解(例如,LongBench,RULER)和复杂推理(例如,AIME24,OlympiadBench)等不同基准进行的大量实验,我们证明了LycheeDecode实现了与甚至超过全注意力基线的生成质量。至关重要的是,这是在128K上下文长度下高达2.7倍的加速下完成的。通过保留注意力头的功能多样性,我们的细粒度策略克服了现有方法的性能瓶颈,为高效和高质量的长文本LLM推理提供了一条强大且经过验证的途径。
🔬 方法详解
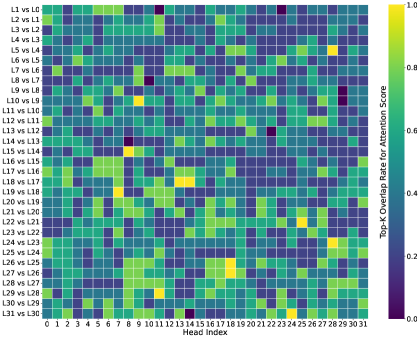
问题定义:长文本LLM推理过程中,键值缓存随着上下文长度的增加而迅速膨胀,导致内存占用和计算延迟显著增加。现有方法通过跨层共享关键token来缓解这个问题,但粗粒度的共享方式忽略了不同注意力头的功能差异,从而影响模型性能。
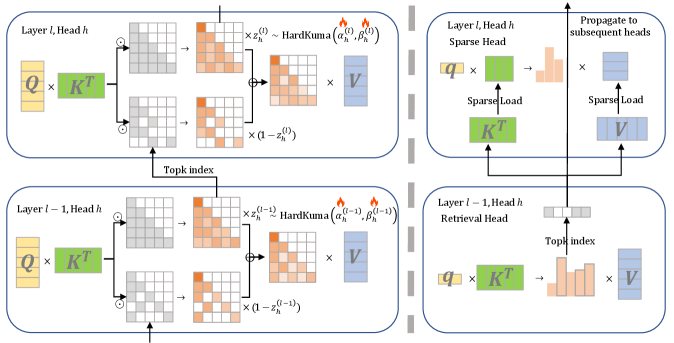
核心思路:LycheeDecode的核心思路是采用一种细粒度的混合头注意力机制,将注意力头划分为检索头和稀疏头。检索头负责动态识别关键token,而稀疏头则重用这些关键token进行高效计算。这种方式既能减少计算量,又能保留注意力头的功能多样性。
技术框架:LycheeDecode的整体框架包括以下几个主要步骤:1) 使用检索头动态识别关键token;2) 将关键token传递给稀疏头;3) 稀疏头利用关键token进行注意力计算;4) 将稀疏头的输出进行聚合,得到最终的输出表示。该框架的关键在于如何高效地识别关键token,以及如何设计稀疏头的计算方式。
关键创新:LycheeDecode的关键创新在于其细粒度的混合头注意力机制。与现有方法相比,LycheeDecode能够更精细地控制哪些token被共享,以及哪些注意力头参与计算。此外,LycheeDecode还采用了一种基于HardKuma的硬件高效的top-k选择策略,进一步提高了计算效率。
关键设计:LycheeDecode的关键设计包括:1) 检索头的数量和选择策略;2) 稀疏头的计算方式,例如采用稀疏矩阵乘法或低秩近似;3) HardKuma-based top-k选择策略的具体实现细节。这些设计参数需要根据具体的模型和数据集进行调整,以达到最佳的性能。
🖼️ 关键图片

📊 实验亮点
实验结果表明,LycheeDecode在LongBench和RULER等长文本理解基准以及AIME24和OlympiadBench等复杂推理基准上,取得了与全注意力基线相当甚至更好的生成质量。同时,在128K上下文长度下,LycheeDecode实现了高达2.7倍的推理加速,显著降低了计算成本。
🎯 应用场景
LycheeDecode可应用于各种需要处理长文本的场景,例如长文档摘要、机器翻译、对话生成、代码生成等。通过降低长文本LLM推理的计算成本,LycheeDecode使得在资源受限的设备上部署这些模型成为可能,并促进了长文本LLM在实际应用中的普及。
📄 摘要(原文)
The proliferation of long-context large language models (LLMs) exposes a key bottleneck: the rapidly expanding key-value cache during decoding, which imposes heavy memory and latency costs. While recent approaches attempt to alleviate this by sharing a single set of crucial tokens across layers, such coarse-grained sharing undermines model performance by neglecting the functional diversity of attention heads. To address this, we propose LycheeDecode, an efficient decoding method centered on a fine-grained hybrid-head attention mechanism that employs a hardware-efficient top-k selection strategy. Specifically, the novel HardKuma-based mechanism partitions attention heads into a small subset of retrieval heads that dynamically identify crucial tokens and a majority of sparse heads that reuse them for efficient computation. Through extensive experiments on leading models like Llama3 and Qwen3 across diverse benchmarks for long-context understanding (e.g., LongBench, RULER) and complex reasoning (e.g., AIME24, OlympiadBench), we demonstrate that LycheeDecode achieves generative quality comparable to, and at times surpassing even the full-attention baseline. Crucially, this is accomplished with up to a 2.7x speedup at a 128K context length. By preserving the functional diversity of attention heads, our fine-grained strategy overcomes the performance bottlenecks of existing methods, providing a powerful and validated pathway to both efficient and high-quality long-context LLM inference.