PersoDPO: Scalable Preference Optimization for Instruction-Adherent, Persona-Grounded Dialogue via Multi-LLM Evaluation
作者: Saleh Afzoon, MohammadHossein Ahmadi, Usman Naseem, Amin Beheshti
分类: cs.CL, cs.HC
发布日期: 2026-02-04
备注: Accepted at WISE 2025 Conference
💡 一句话要点
PersoDPO:通过多LLM评估实现可扩展的、符合指令和角色设定的对话偏好优化
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 对话系统 偏好优化 大型语言模型 角色设定 自动化评估
📋 核心要点
- 现有开源LLM在角色设定对话中,难以同时保证上下文一致性和角色一致性,是当前面临的核心挑战。
- PersoDPO利用闭源和开源LLM的自动评估信号,构建高质量偏好对,无需人工标注,实现可扩展的偏好优化。
- 实验表明,使用PersoDPO微调的开源模型在多个评估指标上,显著优于现有开源基线和标准DPO方法。
📝 摘要(中文)
个性化和上下文连贯性是构建有效的角色设定对话系统的两个重要组成部分。这些方面在增强用户参与度以及确保响应与用户身份更相关和一致方面起着至关重要的作用。然而,最近的研究表明,尽管开源大型语言模型(LLM)表现出强大的通用对话能力(如流畅性和自然性),但它们仍然难以生成在上下文上具有依据且与角色提示对齐的响应。我们提出了PersoDPO,这是一个可扩展的偏好优化框架,它使用来自闭源和开源LLM生成的响应的自动评估的监督信号来微调对话模型。该框架集成了针对连贯性和个性化的评估指标,以及长度-格式合规性特征,以促进指令遵循。这些信号被组合起来以自动构建高质量的偏好对,无需手动注释,从而实现可扩展且可重现的训练流程。在FoCus数据集上的实验表明,使用PersoDPO框架微调的开源语言模型在多个评估维度上始终优于强大的开源基线和标准直接偏好优化(DPO)变体。
🔬 方法详解
问题定义:论文旨在解决角色设定对话系统中,开源LLM难以生成既符合上下文又符合角色设定的高质量回复的问题。现有方法,特别是直接偏好优化(DPO),在处理复杂的角色设定和上下文依赖时表现不足,需要大量人工标注数据,成本高昂且难以扩展。
核心思路:PersoDPO的核心思路是利用多个LLM(包括闭源和开源)的自动评估结果作为监督信号,自动构建高质量的偏好对,从而避免人工标注的需要。通过优化这些偏好对,可以引导模型生成更符合指令、更连贯且更具个性化的回复。
技术框架:PersoDPO框架主要包含以下几个阶段:1) 使用多个LLM生成候选回复;2) 使用自动评估指标(如连贯性、个性化程度、长度-格式合规性)对候选回复进行评分;3) 基于评分构建偏好对,即选择得分较高的回复作为“胜者”,得分较低的回复作为“败者”;4) 使用DPO算法,根据构建的偏好对微调对话模型。整个流程无需人工干预,可以自动化运行。
关键创新:PersoDPO的关键创新在于其自动构建偏好对的方法。与传统的DPO方法需要人工标注偏好数据不同,PersoDPO利用多个LLM的自动评估结果,显著降低了标注成本,提高了可扩展性。此外,PersoDPO集成了多种评估指标,包括连贯性、个性化程度和长度-格式合规性,从而可以更全面地评估和优化模型的性能。
关键设计:PersoDPO的关键设计包括:1) 使用多个LLM进行评估,以提高评估的准确性和鲁棒性;2) 集成多种评估指标,以全面评估模型的性能;3) 使用长度-格式合规性特征,以确保模型生成符合指令要求的回复;4) 使用DPO算法进行微调,以优化模型的偏好。
🖼️ 关键图片


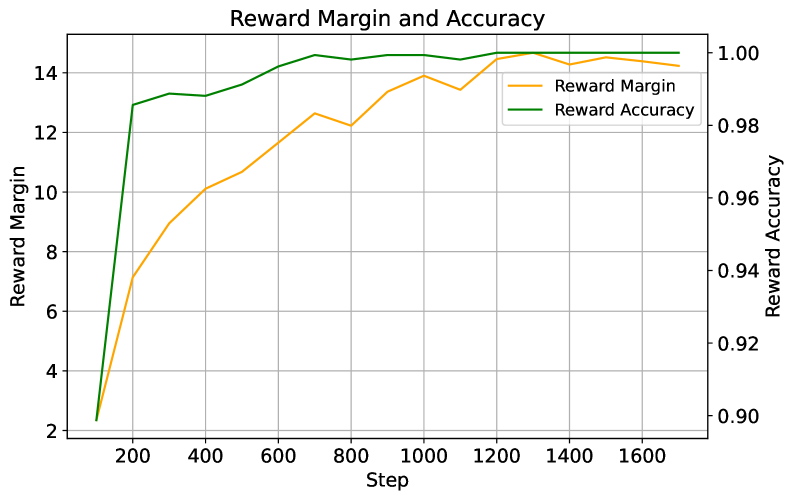
📊 实验亮点
在FoCus数据集上的实验结果表明,使用PersoDPO框架微调的开源语言模型在多个评估维度上始终优于强大的开源基线和标准DPO变体。具体而言,PersoDPO在连贯性、个性化程度和指令遵循方面均取得了显著提升,证明了其有效性。
🎯 应用场景
PersoDPO可应用于各种需要个性化和上下文连贯性的对话系统,例如智能客服、虚拟助手、社交机器人等。该方法能够显著提高对话系统的用户体验,使其能够生成更自然、更相关、更符合用户期望的回复。此外,PersoDPO的自动化训练流程降低了开发成本,使得构建高质量的对话系统变得更加容易。
📄 摘要(原文)
Personalization and contextual coherence are two essential components in building effective persona-grounded dialogue systems. These aspects play a crucial role in enhancing user engagement and ensuring responses are more relevant and consistent with user identity. However, recent studies indicate that open-source large language models (LLMs) continue to struggle to generate responses that are both contextually grounded and aligned with persona cues, despite exhibiting strong general conversational abilities like fluency and naturalness. We present PersoDPO, a scalable preference optimisation framework that uses supervision signals from automatic evaluations of responses generated by both closed-source and open-source LLMs to fine-tune dialogue models. The framework integrates evaluation metrics targeting coherence and personalization, along with a length-format compliance feature to promote instruction adherence. These signals are combined to automatically construct high-quality preference pairs without manual annotation, enabling a scalable and reproducible training pipeline. Experiments on the FoCus dataset show that an open-source language model fine-tuned with the PersoDPO framework consistently outperforms strong open-source baselines and a standard Direct Preference Optimization (DPO) variant across multiple evaluation dimensions.