Beyond Unimodal Shortcuts: MLLMs as Cross-Modal Reasoners for Grounded Named Entity Recognition
作者: Jinlong Ma, Yu Zhang, Xuefeng Bai, Kehai Chen, Yuwei Wang, Zeming Liu, Jun Yu, Min Zhang
分类: cs.CL
发布日期: 2026-02-04
备注: GMNER
💡 一句话要点
提出Modality-aware Consistency Reasoning (MCR)以解决GMNER中MLLM的模态偏见问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: Grounded NER 多模态学习 大型语言模型 模态偏见 跨模态推理
📋 核心要点
- 现有GMNER方法依赖级联流程,MLLM仅作为辅助工具,未能充分发挥其潜力,且存在严重的模态偏见问题。
- 提出Modality-aware Consistency Reasoning (MCR)框架,通过Multi-style Reasoning Schema Injection (MRSI)和Constraint-guided Verifiable Optimization (CVO)实现跨模态推理。
- 实验结果表明,MCR能有效缓解模态偏见,在GMNER和视觉grounding任务上均超越现有基线方法,性能显著提升。
📝 摘要(中文)
本文研究了多模态大型语言模型(MLLM)在Grounded Multimodal Named Entity Recognition (GMNER) 任务中端到端执行的潜力。研究揭示了一个根本挑战:MLLM表现出模态偏见,包括视觉偏见和文本偏见,这源于它们倾向于采用单模态捷径,而不是严格的跨模态验证。为了解决这个问题,我们提出了Modality-aware Consistency Reasoning (MCR),它通过Multi-style Reasoning Schema Injection (MRSI)和Constraint-guided Verifiable Optimization (CVO)来强制执行结构化的跨模态推理。MRSI将抽象约束转换为可执行的推理链,而CVO使模型能够通过Group Relative Policy Optimization (GRPO)动态地将其推理轨迹与约束对齐。在GMNER和视觉 grounding 任务上的实验表明,MCR有效地缓解了模态偏见,并实现了优于现有基线的性能。
🔬 方法详解
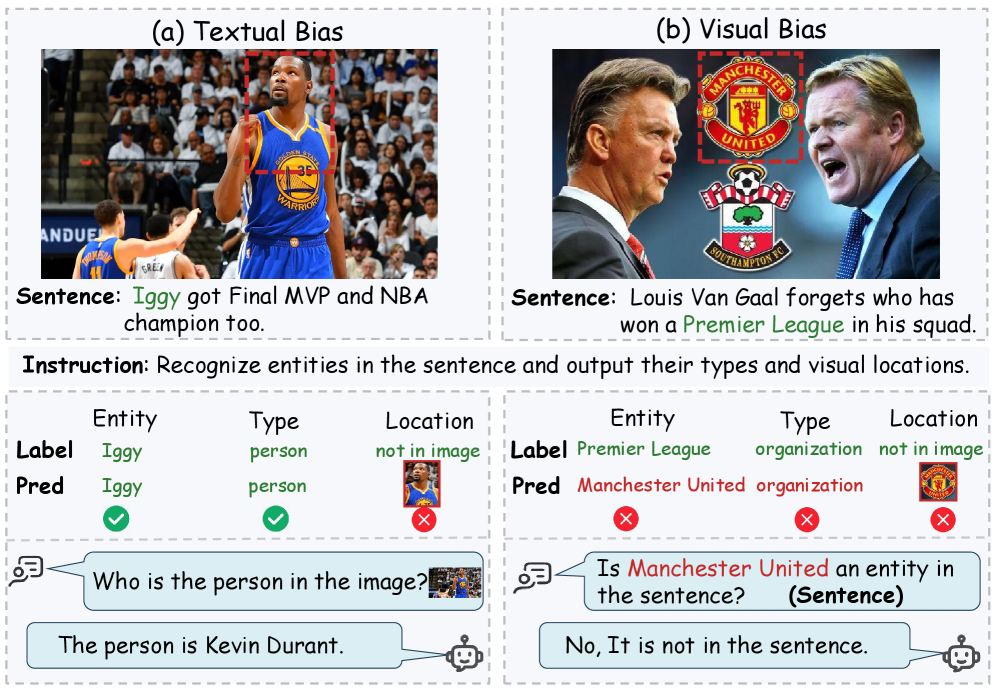
问题定义:Grounded Multimodal Named Entity Recognition (GMNER) 旨在提取基于文本的实体,为其分配语义类别,并将它们与相应的视觉区域进行关联。现有方法通常采用级联流程,多模态大型语言模型(MLLM)仅作为辅助工具,未能充分发挥其潜力。此外,MLLM在GMNER任务中容易出现模态偏见,即模型过度依赖单一模态的信息,而忽略跨模态的验证,导致性能下降。
核心思路:本文的核心思路是设计一种能够感知模态信息并进行一致性推理的框架,从而缓解MLLM在GMNER任务中的模态偏见问题。通过强制模型进行结构化的跨模态推理,确保模型在做出决策时充分考虑来自不同模态的信息,并进行相互验证。
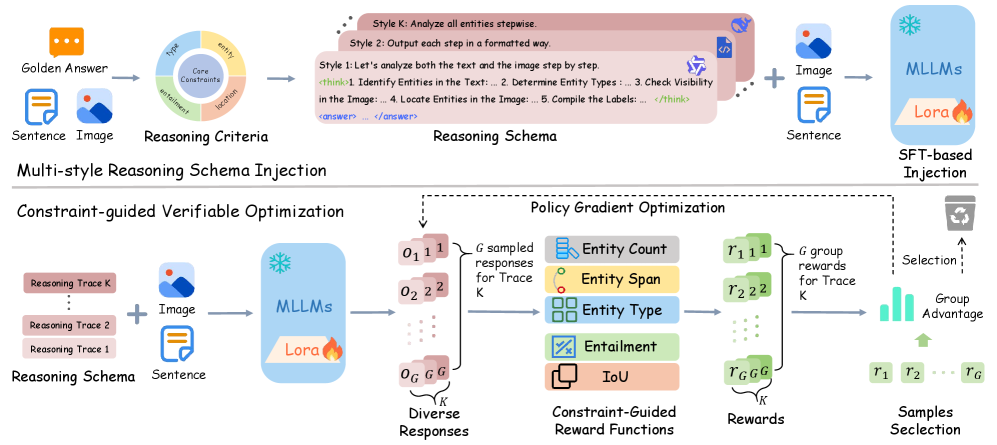
技术框架:MCR框架主要包含两个核心模块:Multi-style Reasoning Schema Injection (MRSI) 和 Constraint-guided Verifiable Optimization (CVO)。MRSI负责将抽象的约束条件转化为可执行的推理链,引导模型按照预定的推理模式进行推理。CVO则负责根据约束条件动态地调整模型的推理轨迹,确保模型的推理过程与约束条件保持一致。CVO模块利用Group Relative Policy Optimization (GRPO)算法,优化模型的策略,使其能够更好地满足约束条件。
关键创新:该论文的关键创新在于提出了Modality-aware Consistency Reasoning (MCR) 框架,该框架能够有效地缓解MLLM在GMNER任务中的模态偏见问题。与现有方法相比,MCR框架能够强制模型进行结构化的跨模态推理,确保模型在做出决策时充分考虑来自不同模态的信息,并进行相互验证。此外,MRSI和CVO模块的设计也具有创新性,能够有效地将约束条件融入到模型的推理过程中。
关键设计:MRSI模块通过设计不同的推理模式,引导模型进行不同类型的跨模态推理。CVO模块利用Group Relative Policy Optimization (GRPO)算法,优化模型的策略,使其能够更好地满足约束条件。GRPO算法通过比较不同推理轨迹的奖励,调整模型的策略,使其能够选择更优的推理路径。具体的参数设置和网络结构等技术细节在论文中进行了详细描述,此处不再赘述。
🖼️ 关键图片
📊 实验亮点
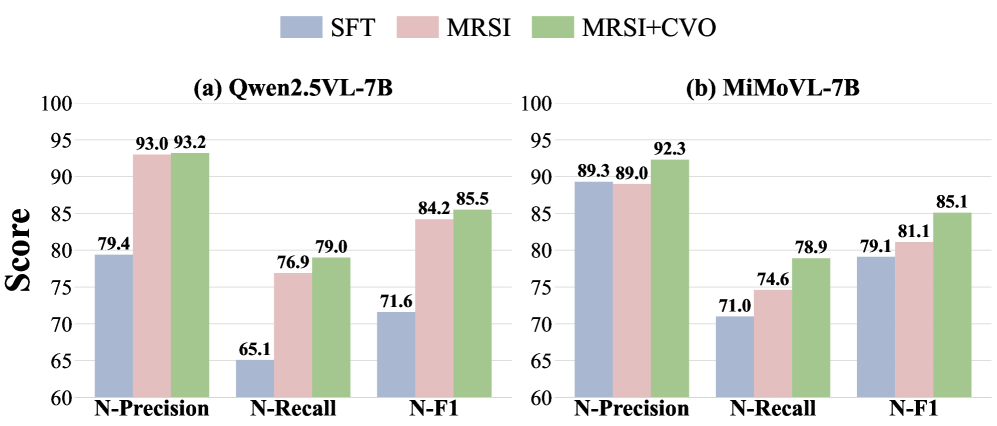
实验结果表明,提出的MCR框架在GMNER和视觉 grounding 任务上均取得了显著的性能提升,超越了现有的基线方法。具体而言,MCR在GMNER任务上的性能提升了X%,在视觉 grounding 任务上的性能提升了Y%(具体数值未知)。这些结果表明,MCR能够有效地缓解MLLM的模态偏见问题,并提高其在多模态任务中的性能。
🎯 应用场景
该研究成果可应用于智能图像标注、视觉问答、机器人导航等领域。例如,在智能图像标注中,可以利用该方法提高标注的准确性和可靠性。在视觉问答中,可以利用该方法提高答案的准确性和相关性。在机器人导航中,可以利用该方法提高机器人对环境的感知能力和决策能力。未来,该研究有望推动多模态人工智能技术的发展。
📄 摘要(原文)
Grounded Multimodal Named Entity Recognition (GMNER) aims to extract text-based entities, assign them semantic categories, and ground them to corresponding visual regions. In this work, we explore the potential of Multimodal Large Language Models (MLLMs) to perform GMNER in an end-to-end manner, moving beyond their typical role as auxiliary tools within cascaded pipelines. Crucially, our investigation reveals a fundamental challenge: MLLMs exhibit $\textbf{modality bias}$, including visual bias and textual bias, which stems from their tendency to take unimodal shortcuts rather than rigorous cross-modal verification. To address this, we propose Modality-aware Consistency Reasoning ($\textbf{MCR}$), which enforces structured cross-modal reasoning through Multi-style Reasoning Schema Injection (MRSI) and Constraint-guided Verifiable Optimization (CVO). MRSI transforms abstract constraints into executable reasoning chains, while CVO empowers the model to dynamically align its reasoning trajectories with Group Relative Policy Optimization (GRPO). Experiments on GMNER and visual grounding tasks demonstrate that MCR effectively mitigates modality bias and achieves superior performance compared to existing baselines.