Fine-Grained Activation Steering: Steering Less, Achieving More
作者: Zijian Feng, Tianjiao Li, Zixiao Zhu, Hanzhang Zhou, Junlang Qian, Li Zhang, Jia Jim Deryl Chua, Lee Onn Mak, Gee Wah Ng, Kezhi Mao
分类: cs.CL
发布日期: 2026-02-04
备注: ICLR 2026
💡 一句话要点
AUSteer:通过细粒度激活控制,以更少干预实现更优大语言模型行为调控
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 行为调控 激活控制 细粒度控制 原子单元 自适应控制 情感控制 毒性减少
📋 核心要点
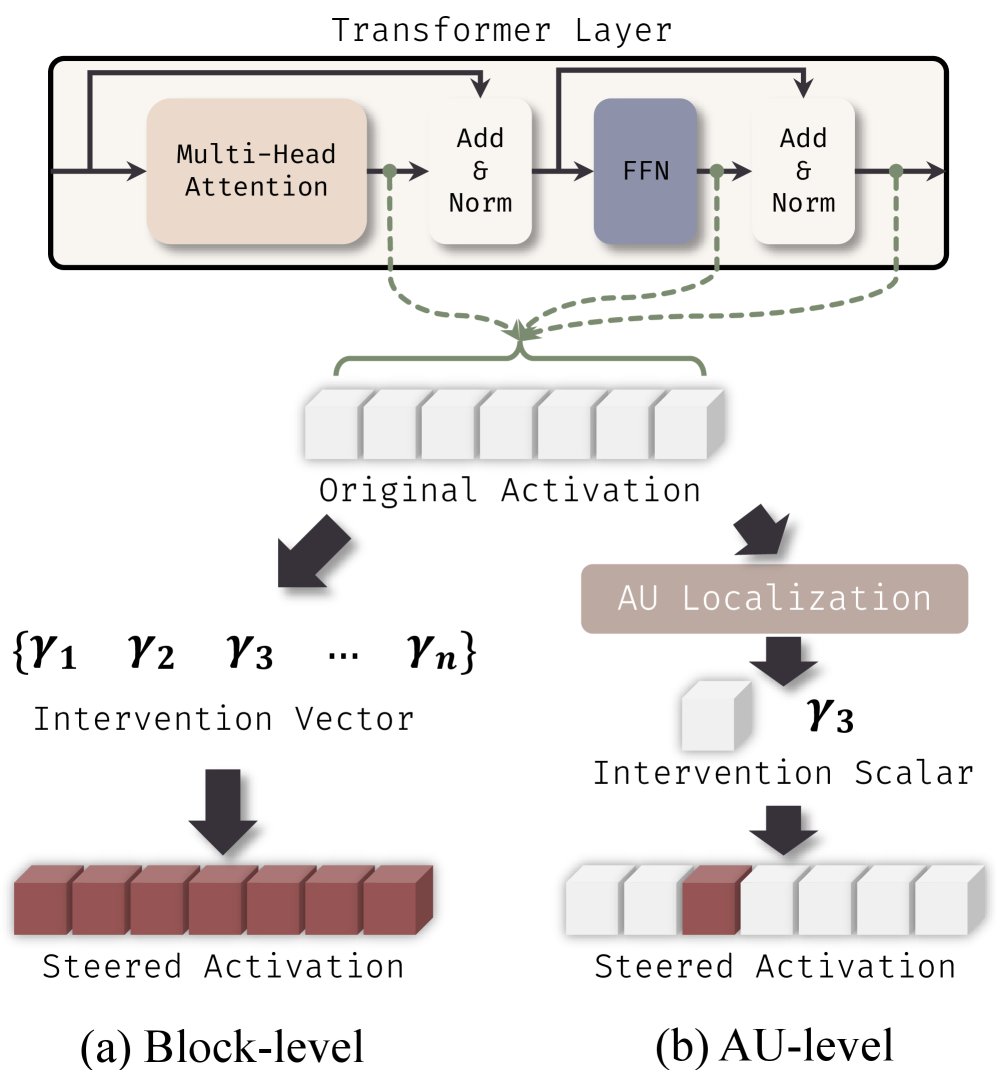
- 现有激活控制方法在块级别进行干预,忽略了块内激活的异构性,导致控制效率低下。
- 论文提出AUSteer,一种细粒度的激活控制方法,通过识别和控制原子单元级别的激活来提高控制精度。
- 实验结果表明,AUSteer在多个LLM和任务上优于现有基线,同时显著减少了需要控制的激活数量。
📝 摘要(中文)
激活控制已成为一种经济高效的修改大型语言模型(LLM)行为的范例。现有方法通常在块级别进行干预,控制选定的注意力头、前馈网络或残差流的捆绑激活。然而,我们发现块级激活本质上是异构的,纠缠了有益的、无关的和有害的特征,从而导致块级控制粗糙、低效且具有侵入性。为了研究根本原因,我们将块激活分解为细粒度的原子单元(AU)级激活,其中每个AU级激活对应于块激活的单个维度,每个AU表示块权重矩阵的一个切片。因此,控制AU级激活等同于控制其相关的AU。我们的理论和实证分析表明,异构性产生的原因是不同的AU或维度控制LLM输出中不同的token分布。因此,块级控制不可避免地将有用的和有害的token方向一起移动,从而降低了效率。限制对有益AU的干预可以产生更精确和有效的控制。基于这一洞察,我们提出AUSteer,一种简单而有效的方法,它在AU级别的更细粒度上运行。AUSteer首先通过计算对比样本上的激活动量来全局识别判别性AU。然后,它为不同的输入和选定的AU激活分配自适应控制强度。在多个LLM和任务上的综合实验表明,AUSteer始终优于先进的基线,同时控制的激活明显更少,这表明控制得越少,效果越好。
🔬 方法详解
问题定义:现有的大语言模型行为调控方法,如激活控制,通常在模型的块级别进行干预,例如控制整个注意力头或前馈网络的激活。这种粗粒度的控制方式忽略了块内激活的异构性,即不同的激活维度可能对应着不同的、甚至相反的行为特征。因此,在块级别进行控制会同时影响有益和有害的特征,降低了控制的效率和精度。
核心思路:论文的核心思路是将块级别的激活分解为更细粒度的原子单元(AU)级别,每个AU对应于块权重矩阵的一个切片和一个激活维度。通过分析不同AU对模型输出的影响,识别出对特定行为有益的AU,并只对这些AU进行控制。这种细粒度的控制方式可以更精确地调整模型的行为,避免了对无关或有害特征的干扰。
技术框架:AUSteer方法主要包含两个阶段:AU识别和自适应控制。在AU识别阶段,首先构建对比样本,然后计算每个AU在对比样本上的激活动量,用于衡量该AU对目标行为的贡献程度。选择激活动量高的AU作为判别性AU。在自适应控制阶段,根据输入样本和选定的AU激活,为每个AU分配自适应的控制强度,然后对AU激活进行调整。
关键创新:AUSteer的关键创新在于将激活控制的粒度从块级别降低到原子单元级别。通过分析和控制单个激活维度,可以更精确地调整模型的行为,避免了粗粒度控制带来的副作用。此外,AUSteer还引入了自适应控制强度,可以根据不同的输入样本和AU激活动态调整控制力度,进一步提高了控制的灵活性和有效性。
关键设计:AUSteer的关键设计包括:1) 使用激活动量作为AU重要性的度量,可以有效地识别对目标行为有贡献的AU;2) 采用自适应控制强度,可以根据输入样本和AU激活动态调整控制力度;3) 通过限制控制的AU数量,可以降低计算成本,并避免对模型造成过多的干扰。
🖼️ 关键图片

📊 实验亮点
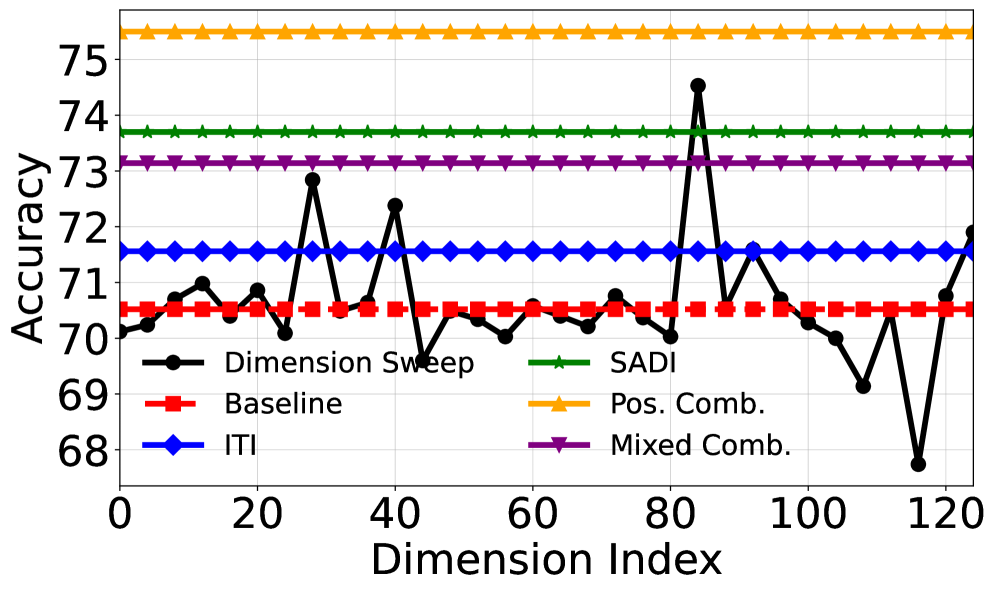
实验结果表明,AUSteer在多个LLM(包括LLaMA-2和GPT-J)和任务(包括情感控制和毒性减少)上显著优于现有的激活控制方法。例如,在情感控制任务中,AUSteer在控制情感强度的同时,能够更好地保持生成文本的流畅性和相关性。此外,AUSteer能够以更少的干预(即控制更少的激活)实现更好的性能,证明了其高效性和精确性。
🎯 应用场景
AUSteer方法可应用于各种需要对大型语言模型行为进行精确控制的场景,例如:内容生成风格控制、对话系统偏好对齐、有害信息过滤等。通过细粒度的激活控制,可以使模型在特定任务上表现出期望的行为,同时避免产生不希望的副作用。该方法具有广泛的应用前景,有助于提升大语言模型在实际应用中的可靠性和安全性。
📄 摘要(原文)
Activation steering has emerged as a cost-effective paradigm for modifying large language model (LLM) behaviors. Existing methods typically intervene at the block level, steering the bundled activations of selected attention heads, feedforward networks, or residual streams. However, we reveal that block-level activations are inherently heterogeneous, entangling beneficial, irrelevant, and harmful features, thereby rendering block-level steering coarse, inefficient, and intrusive. To investigate the root cause, we decompose block activations into fine-grained atomic unit (AU)-level activations, where each AU-level activation corresponds to a single dimension of the block activation, and each AU denotes a slice of the block weight matrix. Steering an AU-level activation is thus equivalent to steering its associated AU. Our theoretical and empirical analysis show that heterogeneity arises because different AUs or dimensions control distinct token distributions in LLM outputs. Hence, block-level steering inevitably moves helpful and harmful token directions together, which reduces efficiency. Restricting intervention to beneficial AUs yields more precise and effective steering. Building on this insight, we propose AUSteer, a simple and efficient method that operates at a finer granularity of the AU level. AUSteer first identifies discriminative AUs globally by computing activation momenta on contrastive samples. It then assigns adaptive steering strengths tailored to diverse inputs and selected AU activations. Comprehensive experiments on multiple LLMs and tasks show that AUSteer consistently surpasses advanced baselines while steering considerably fewer activations, demonstrating that steering less achieves more.