History-Guided Iterative Visual Reasoning with Self-Correction
作者: Xinglong Yang, Zhilin Peng, Zhanzhan Liu, Haochen Shi, Sheng-Jun Huang
分类: cs.CL, cs.AI, cs.MM
发布日期: 2026-02-04
💡 一句话要点
提出H-GIVR框架,通过历史信息引导迭代视觉推理并进行自校正,提升多模态大语言模型的推理可靠性。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态大语言模型 视觉推理 自洽性 迭代推理 历史信息引导 自校正 跨模态学习
📋 核心要点
- 现有自洽性方法局限于固定的“重复抽样和投票”模式,无法重用历史推理信息,导致模型难以主动纠正视觉理解错误。
- H-GIVR框架通过迭代推理,使模型多次观察图像,并利用历史答案作为参考,动态纠正错误,提升推理准确性。
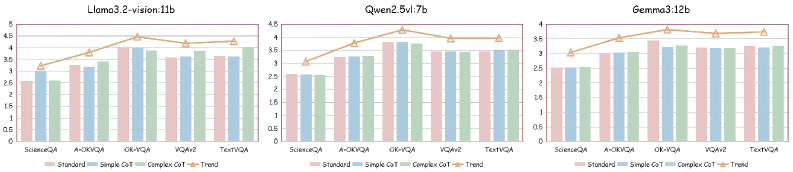
- 实验结果表明,H-GIVR框架在多个数据集和模型上显著提升了跨模态推理准确性,同时保持较低的计算成本,例如在ScienceQA数据集上提升了107%。
📝 摘要(中文)
本文提出了一种名为H-GIVR的框架,旨在提升多模态大语言模型(MLLMs)的推理可靠性。该框架受到人类重复验证和动态纠错推理行为的启发,通过迭代推理,使MLLM多次观察图像,并将先前生成的答案作为后续步骤的参考,从而动态地纠正错误并提高答案准确性。与传统的“重复抽样和投票”的自洽性方法不同,H-GIVR能够重用历史推理信息。在五个数据集和三个模型上进行的综合实验表明,H-GIVR框架能够显著提高跨模态推理的准确性,同时保持较低的计算成本。例如,在ScienceQA数据集上使用Llama3.2-vision:11b模型时,该模型平均每个问题需要2.57个响应即可达到78.90%的准确率,相比基线提高了107%。
🔬 方法详解
问题定义:现有方法在提升多模态大语言模型推理可靠性时,主要依赖于重复采样和投票的自洽性方法。这些方法忽略了历史推理信息,导致模型无法动态调整推理过程,难以有效纠正视觉理解错误。因此,需要一种能够利用历史信息,进行迭代推理和自校正的方法,以提升推理准确性。
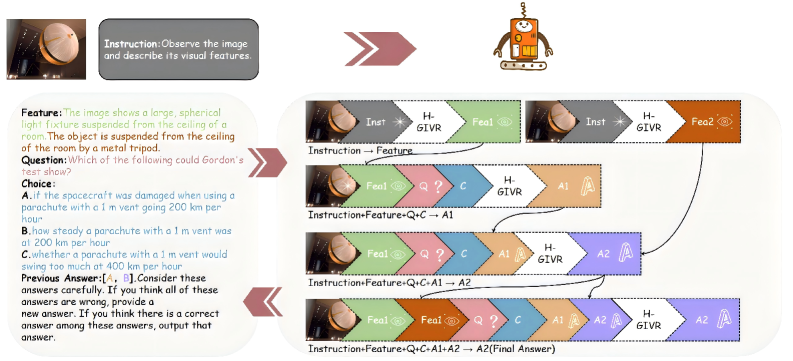
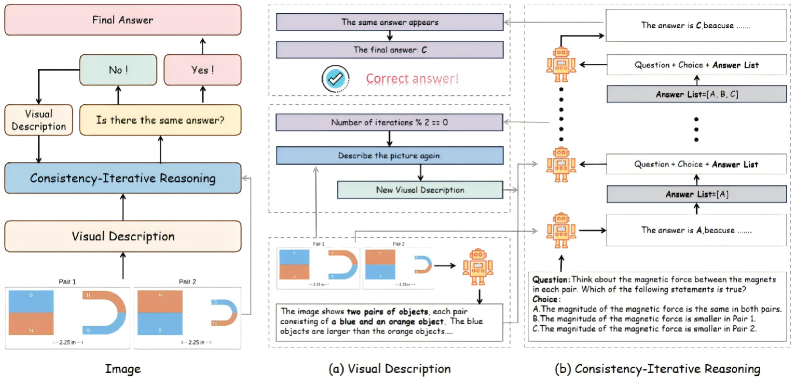
核心思路:H-GIVR框架的核心思路是模拟人类的推理过程,即通过多次观察和验证,并利用已有的信息来动态纠正错误。模型在迭代推理过程中,会多次观察图像,并将之前生成的答案作为后续步骤的参考,从而实现动态的错误纠正和推理优化。
技术框架:H-GIVR框架的整体流程如下:首先,模型接收图像和问题作为输入。然后,模型进行第一次推理,生成初始答案。接下来,模型进入迭代推理阶段,每次迭代都会将图像、问题以及之前的答案作为输入,生成新的答案。在每次迭代中,模型会利用历史答案来指导视觉理解和推理过程。最后,模型综合所有迭代生成的答案,选择最终的答案。
关键创新:H-GIVR框架的关键创新在于引入了历史信息引导的迭代推理机制。与传统的自洽性方法不同,H-GIVR能够重用历史推理信息,使模型能够动态地调整推理过程,并主动纠正视觉理解错误。这种迭代和自校正的机制能够显著提升推理的准确性和可靠性。
关键设计:H-GIVR框架的关键设计包括:1) 如何有效地利用历史答案来指导后续的推理过程;2) 如何平衡迭代次数和计算成本;3) 如何选择最终的答案。论文中可能使用了特定的注意力机制或融合策略来整合历史信息。具体的损失函数和网络结构细节需要在论文中进一步查找。
🖼️ 关键图片
📊 实验亮点
实验结果表明,H-GIVR框架在多个数据集上显著提升了跨模态推理的准确性。例如,在ScienceQA数据集上,使用Llama3.2-vision:11b模型时,H-GIVR框架仅需平均2.57个响应即可达到78.90%的准确率,相比基线提高了107%。此外,实验还表明H-GIVR框架在保持较低计算成本的同时,能够有效地提升推理性能。
🎯 应用场景
H-GIVR框架可应用于各种需要视觉推理的场景,例如视觉问答、图像描述、视觉常识推理等。该研究成果有助于提升多模态大语言模型在实际应用中的可靠性和准确性,例如在智能客服、自动驾驶、医疗诊断等领域具有潜在的应用价值。未来,该框架可以进一步扩展到其他模态,例如语音和文本,以实现更全面的多模态推理。
📄 摘要(原文)
Self-consistency methods are the core technique for improving the reasoning reliability of multimodal large language models (MLLMs). By generating multiple reasoning results through repeated sampling and selecting the best answer via voting, they play an important role in cross-modal tasks. However, most existing self-consistency methods are limited to a fixed ``repeated sampling and voting'' paradigm and do not reuse historical reasoning information. As a result, models struggle to actively correct visual understanding errors and dynamically adjust their reasoning during iteration. Inspired by the human reasoning behavior of repeated verification and dynamic error correction, we propose the H-GIVR framework. During iterative reasoning, the MLLM observes the image multiple times and uses previously generated answers as references for subsequent steps, enabling dynamic correction of errors and improving answer accuracy. We conduct comprehensive experiments on five datasets and three models. The results show that the H-GIVR framework can significantly improve cross-modal reasoning accuracy while maintaining low computational cost. For instance, using \texttt{Llama3.2-vision:11b} on the ScienceQA dataset, the model requires an average of 2.57 responses per question to achieve an accuracy of 78.90\%, representing a 107\% improvement over the baseline.