Bi-directional Bias Attribution: Debiasing Large Language Models without Modifying Prompts
作者: Yujie Lin, Kunquan Li, Yixuan Liao, Xiaoxin Chen, Jinsong Su
分类: cs.CL, cs.AI
发布日期: 2026-02-04
🔗 代码/项目: GITHUB
💡 一句话要点
提出双向偏差归因方法,无需修改提示即可消除大型语言模型中的偏见。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 偏差消除 公平性 神经元归因 积分梯度
📋 核心要点
- 现有LLM去偏见方法如微调和提示工程存在可扩展性问题,且可能影响多轮交互的用户体验。
- 该论文提出一种新框架,无需微调或修改提示,即可检测刻板印象诱导词并归因神经元级偏差。
- 实验表明,该方法在减少偏差的同时,能够保持LLM的整体性能,具有实际应用价值。
📝 摘要(中文)
大型语言模型(LLMs)在各种自然语言处理任务中表现出令人印象深刻的能力。然而,它们的输出经常表现出社会偏见,引发了公平性问题。现有的去偏见方法,如在额外数据集上进行微调或提示工程,面临可扩展性问题或在多轮交互中损害用户体验。为了解决这些挑战,我们提出了一个框架,用于检测刻板印象诱导词,并将LLM中的神经元级偏差归因,而无需微调或修改提示。我们的框架首先通过跨人口群体的比较分析来识别刻板印象诱导形容词和名词。然后,我们使用基于积分梯度的两种归因策略将有偏行为归因于特定神经元。最后,我们通过直接干预投影层的激活来减轻偏差。在三个广泛使用的LLM上的实验表明,我们的方法有效地减少了偏差,同时保持了整体模型性能。代码可在github链接获得:https://github.com/XMUDeepLIT/Bi-directional-Bias-Attribution。
🔬 方法详解
问题定义:大型语言模型(LLMs)在生成文本时会表现出社会偏见,这引发了公平性问题。现有的去偏见方法,例如微调或提示工程,要么难以扩展到大型模型,要么在多轮对话中会影响用户体验,因为需要不断调整提示。
核心思路:该论文的核心思路是通过分析模型内部的神经元激活来定位和消除偏见,而不是依赖于外部的微调或提示修改。具体来说,首先识别导致刻板印象的词语,然后将这些词语与模型中的特定神经元联系起来,最后通过干预这些神经元的激活来减轻偏见。这种方法旨在直接解决模型内部的偏见根源。
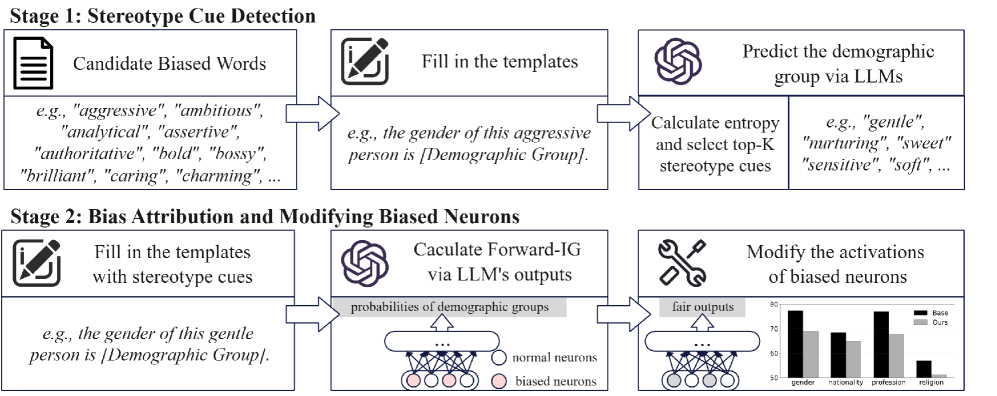
技术框架:该框架包含以下几个主要阶段: 1. 刻板印象诱导词识别:通过比较不同人口群体在特定上下文中的词语使用情况,识别出那些与刻板印象相关的形容词和名词。 2. 神经元偏差归因:使用基于积分梯度的两种归因策略,将有偏行为归因于特定的神经元。这两种策略分别从输入词语和输出结果两个方向进行归因,从而实现双向偏差归因。 3. 偏差缓解:通过直接干预投影层的神经元激活来减轻偏差。具体来说,通过调整这些神经元的激活值,使得模型在生成文本时不再表现出偏见。
关键创新:该论文的关键创新在于提出了一种无需修改提示或微调的去偏见方法。与现有方法相比,该方法更加高效和灵活,可以直接应用于各种LLM,而无需针对特定任务或数据集进行调整。此外,双向偏差归因策略能够更准确地定位导致偏见的神经元。
关键设计:该论文的关键设计包括: 1. 积分梯度归因:使用积分梯度方法来计算每个神经元对模型输出的影响,从而确定哪些神经元与偏见相关。 2. 双向归因策略:同时考虑输入词语和输出结果,从两个方向进行偏差归因,从而提高归因的准确性。 3. 投影层干预:选择在投影层进行神经元激活干预,因为投影层是连接模型不同部分的桥梁,干预投影层可以有效地影响模型的整体行为。
🖼️ 关键图片

📊 实验亮点
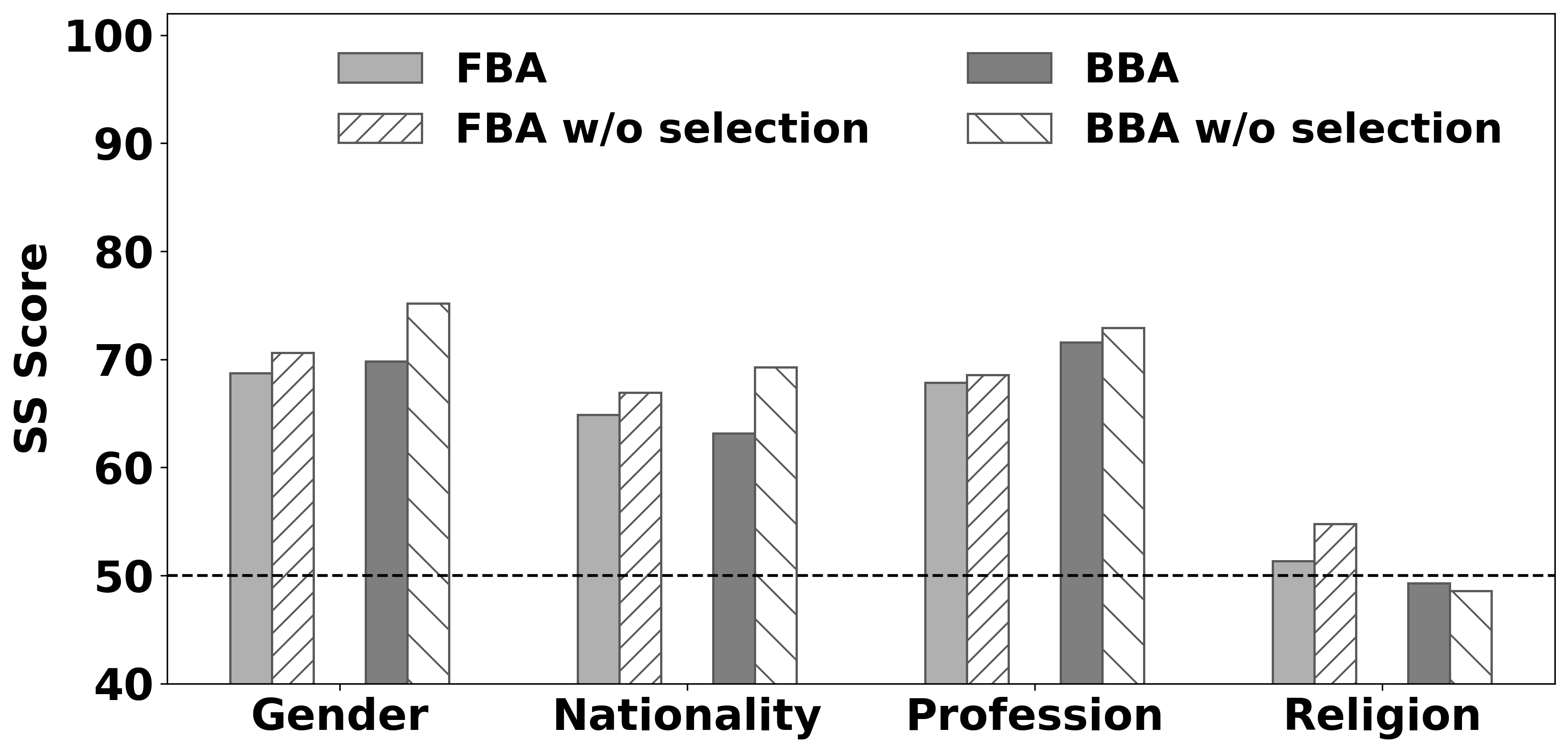
实验结果表明,该方法在三个广泛使用的LLM上有效地减少了偏见,同时保持了整体模型性能。具体的性能数据和对比基线在论文中详细给出,证明了该方法在去偏见方面的有效性和实用性。该方法无需修改提示,更易于部署和应用。
🎯 应用场景
该研究成果可广泛应用于各种需要公平性和公正性的自然语言处理应用中,例如招聘、信贷评估、法律咨询等。通过消除LLM中的偏见,可以避免歧视性或不公平的决策,提高社会公平性。此外,该方法还可以用于提高LLM的可解释性,帮助人们更好地理解模型的内部运作机制。
📄 摘要(原文)
Large language models (LLMs) have demonstrated impressive capabilities across a wide range of natural language processing tasks. However, their outputs often exhibit social biases, raising fairness concerns. Existing debiasing methods, such as fine-tuning on additional datasets or prompt engineering, face scalability issues or compromise user experience in multi-turn interactions. To address these challenges, we propose a framework for detecting stereotype-inducing words and attributing neuron-level bias in LLMs, without the need for fine-tuning or prompt modification. Our framework first identifies stereotype-inducing adjectives and nouns via comparative analysis across demographic groups. We then attribute biased behavior to specific neurons using two attribution strategies based on integrated gradients. Finally, we mitigate bias by directly intervening on their activations at the projection layer. Experiments on three widely used LLMs demonstrate that our method effectively reduces bias while preserving overall model performance. Code is available at the github link: https://github.com/XMUDeepLIT/Bi-directional-Bias-Attribution.