Beyond Rejection Sampling: Trajectory Fusion for Scaling Mathematical Reasoning
作者: Jie Deng, Hanshuang Tong, Jun Li, Shining Liang, Ning Wu, Hongzhi Li, Yutao Xie
分类: cs.CL
发布日期: 2026-02-04
💡 一句话要点
TrajFusion:通过轨迹融合提升LLM在数学推理中的性能
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 数学推理 大型语言模型 拒绝采样 微调 轨迹融合 试错学习 反思提示
📋 核心要点
- 现有基于拒绝采样的数学推理微调方法忽略了训练数据中蕴含的错误信息,导致模型无法有效学习从错误中纠正。
- TrajFusion通过融合正确和错误推理轨迹,并引入反思提示,显式建模试错过程,从而提供更丰富的监督信号。
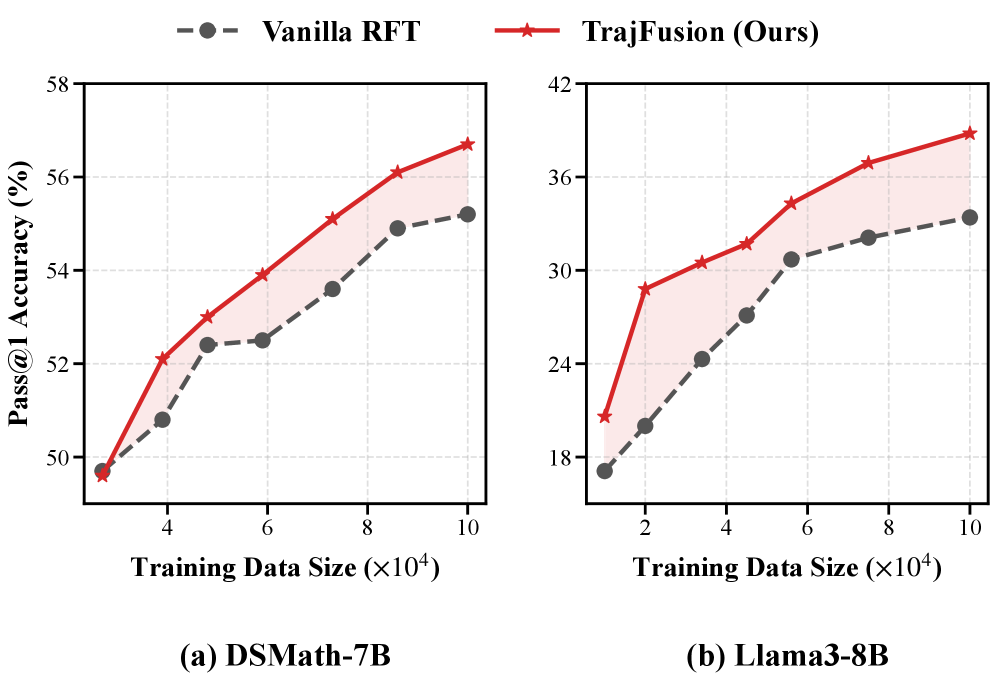
- 实验表明,TrajFusion在多个数学基准测试中显著优于传统的拒绝采样微调方法,尤其是在复杂和长篇推理问题上。
📝 摘要(中文)
大型语言模型(LLM)在数学推理方面取得了显著进展,通常通过拒绝采样进行微调,仅保留正确的推理轨迹。然而,这种范式将监督视为二元过滤器,系统地排除了教师生成的错误,忽略了训练过程中推理失败的建模。本文提出了TrajFusion,一种将拒绝采样重新定义为结构化监督构建过程的微调策略。具体而言,TrajFusion通过将选定的错误轨迹与反思提示和正确轨迹交错,形成融合轨迹,显式地建模了试错推理。每个融合样本的长度根据教师错误的频率和多样性自适应地控制,为具有挑战性的问题提供更丰富的监督,并在错误信号不提供信息时安全地简化为原始的拒绝采样微调(RFT)。TrajFusion不需要改变架构或训练目标。在多个数学基准上的大量实验表明,TrajFusion始终优于RFT,尤其是在具有挑战性的长篇推理问题上。
🔬 方法详解
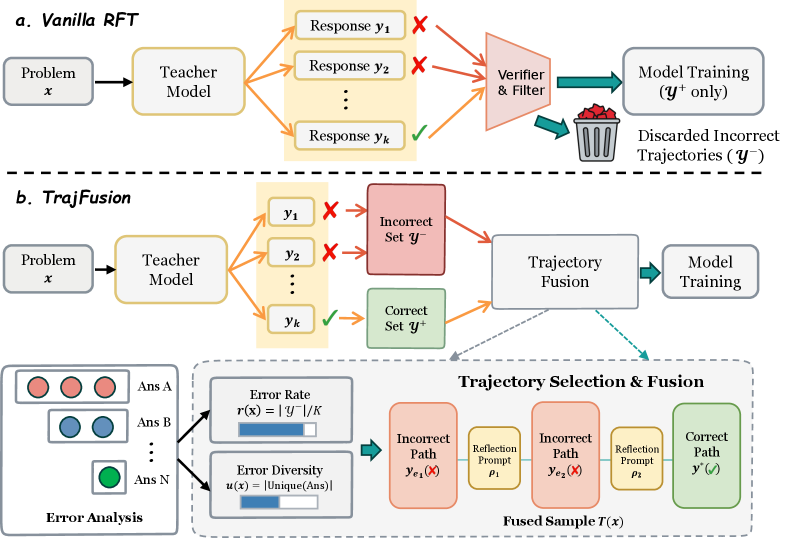
问题定义:现有的大型语言模型在数学推理任务中,通常采用拒绝采样微调(Rejection Sampling Fine-tuning, RFT)方法。RFT仅保留正确的推理轨迹,而丢弃所有错误的轨迹。这种做法的痛点在于,它忽略了错误轨迹中蕴含的丰富信息,使得模型无法学习如何从错误中恢复,尤其是在复杂问题中,错误信息可能包含重要的中间步骤和推理线索。
核心思路:TrajFusion的核心思路是将拒绝采样重新定义为一个结构化的监督构建过程。它不再简单地丢弃错误轨迹,而是将选定的错误轨迹与反思提示和正确的轨迹融合在一起,形成新的训练样本。通过这种方式,TrajFusion显式地建模了试错推理过程,让模型能够学习如何识别和纠正错误。
技术框架:TrajFusion的整体框架如下:首先,对于每个训练样本,生成多个推理轨迹,包括正确和错误的轨迹。然后,根据错误轨迹的质量和多样性,选择一部分错误轨迹。接下来,将选定的错误轨迹与反思提示和正确的轨迹交错融合,形成新的融合轨迹。最后,使用这些融合轨迹对LLM进行微调。整个过程不需要修改LLM的架构或训练目标。
关键创新:TrajFusion最重要的技术创新点在于它对拒绝采样的重新理解和利用。它不再将拒绝采样视为一个简单的二元过滤器,而是将其视为一个结构化的监督构建过程。通过融合错误轨迹,TrajFusion为模型提供了更丰富的监督信号,使其能够更好地学习数学推理。与现有方法的本质区别在于,TrajFusion显式地建模了试错推理过程,而传统的RFT方法则忽略了这一过程。
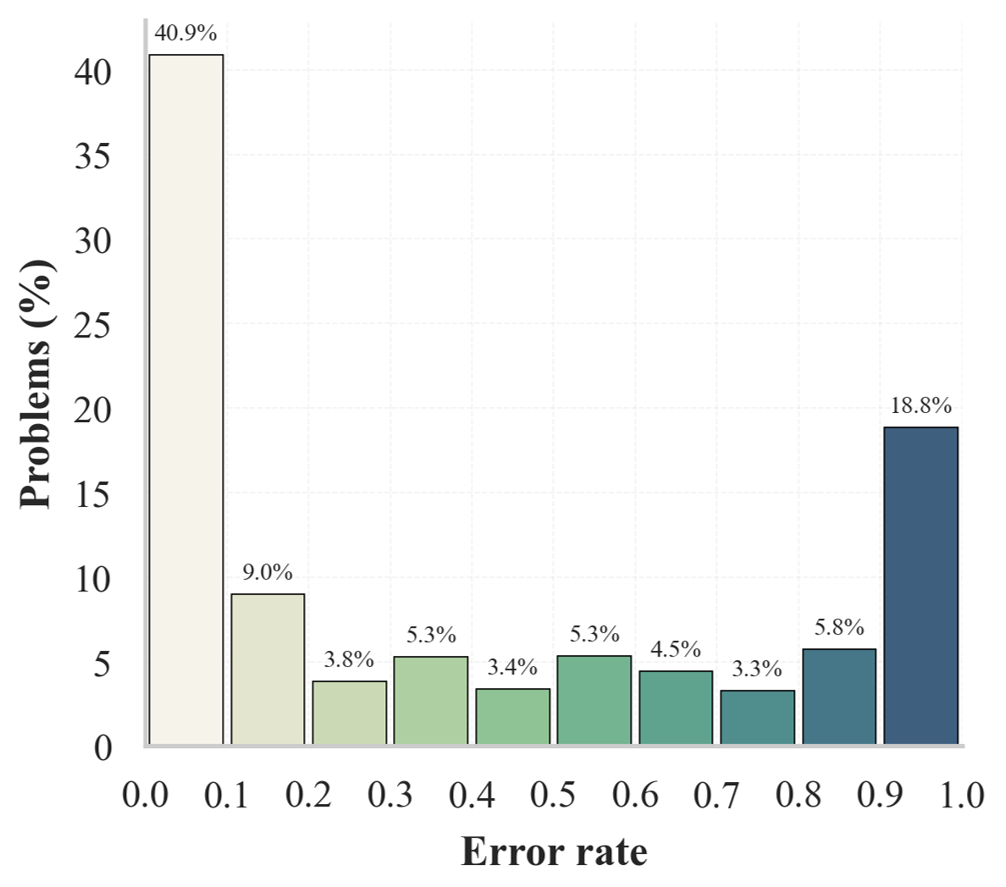
关键设计:TrajFusion的关键设计包括:1) 错误轨迹的选择策略,需要平衡错误轨迹的质量和多样性;2) 反思提示的设计,需要引导模型反思错误的原因和纠正方法;3) 融合轨迹的长度控制,需要根据错误轨迹的频率和多样性自适应地调整。此外,TrajFusion还使用了一种简单的启发式方法来确定何时使用融合轨迹,即当错误信号提供的信息量足够时才使用,否则退化为标准的RFT。
🖼️ 关键图片
📊 实验亮点
实验结果表明,TrajFusion在多个数学基准测试中始终优于RFT。例如,在某些具有挑战性的长篇推理问题上,TrajFusion的性能提升幅度超过10%。这些结果表明,TrajFusion能够有效地利用错误信息,提升LLM的数学推理能力。
🎯 应用场景
TrajFusion可应用于各种需要复杂推理能力的场景,例如科学问题求解、代码生成、逻辑推理等。通过提升LLM的推理能力,可以提高自动化问题解决的效率和准确性,降低人工干预的需求,并有望在教育、科研和工程等领域发挥重要作用。
📄 摘要(原文)
Large language models (LLMs) have made impressive strides in mathematical reasoning, often fine-tuned using rejection sampling that retains only correct reasoning trajectories. While effective, this paradigm treats supervision as a binary filter that systematically excludes teacher-generated errors, leaving a gap in how reasoning failures are modeled during training. In this paper, we propose TrajFusion, a fine-tuning strategy that reframes rejection sampling as a structured supervision construction process. Specifically, TrajFusion forms fused trajectories that explicitly model trial-and-error reasoning by interleaving selected incorrect trajectories with reflection prompts and correct trajectories. The length of each fused sample is adaptively controlled based on the frequency and diversity of teacher errors, providing richer supervision for challenging problems while safely reducing to vanilla rejection sampling fine-tuning (RFT) when error signals are uninformative. TrajFusion requires no changes to the architecture or training objective. Extensive experiments across multiple math benchmarks demonstrate that TrajFusion consistently outperforms RFT, particularly on challenging and long-form reasoning problems.